所以为了回答这个问题,我将使用一个有趣、甜美的比喻:自动售货机。但我的实际表格结构是相同的。(你可以假设有大量的索引、约束等。)
- 基本表格#1 - 库存
我知道,通常会有一个
ITEM_TYPE表格,其中包含'Snickers'、'Milky Way'等行,但由于多种原因,我们的表格并不是这样构建的。实际上,这不是产品数量,而是预先聚合的销售数据:"Pipeline Total"、"Forecast Total"等。因此,我所要处理的只是一个简单的表格,其中有不同类型总数的单独列。
对于这个示例,我还添加了一些文本列,以演示我必须考虑各种数据类型。(这使事情变得复杂。)
除了ID之外,所有列都可为空-这是一个真正的问题。 就我们而言,如果该列为NULL,则NULL是我们需要用于分析和报告的官方值。

CREATE table "VENDING_MACHINES" (
"ID" NUMBER NOT NULL ENABLE,
"SNICKERS_COUNT" NUMBER,
"MILKY_WAY_COUNT" NUMBER,
"TWIX_COUNT" NUMBER,
"SKITTLES_COUNT" NUMBER,
"STARBURST_COUNT" NUMBER,
"SWEDISH_FISH_COUNT" NUMBER,
"FACILITIES_ADDRESS" VARCHAR2(100),
"FACILITIES_CONTACT" VARCHAR2(100),
CONSTRAINT "VENDING_MACHINES_PK" PRIMARY KEY ("ID") USING INDEX ENABLE
)
/
示例数据:
INSERT INTO VENDING_MACHINES (ID, SNICKERS_COUNT, MILKY_WAY_COUNT, TWIX_COUNT,
SKITTLES_COUNT, STARBURST_COUNT, SWEDISH_FISH_COUNT,
FACILITIES_ADDRESS, FACILITIES_CONTACT)
SELECT 225, 11, 15, 14, 0, NULL, 13, '123 Abc Street', 'Steve' FROM DUAL UNION ALL
SELECT 349, NULL, 7, 3, 11, 8, 7, NULL, '' FROM DUAL UNION ALL
SELECT 481, 8, 4, 0, NULL, 14, 3, '1920 Tenaytee Way', NULL FROM DUAL UNION ALL
SELECT 576, 4, 2, 8, 4, 9, NULL, '', 'Angela' FROM DUAL
- 基础表格 #2 - 变更日志
自动售货机会定期连接到数据库并更新其库存记录。
也许他们每次有人购买东西时都会更新,也许他们每30分钟更新一次,或者也许只有在有人重新装满糖果时才更新 - 说实话这并不重要。
重要的是,每当 VENDING_MACHINES 表中的记录被更新时,将执行一个触发器,在单独的日志表 VENDING_MACHINES_CHANGE_LOG 中记录每个单独的更改。
该触发器已经编写并且运行良好。
(如果使用相同值“更新”列,则触发器应忽略更改。)
为 VENDING_MACHINES 表中修改的每个列(除了 ID)记录一个单独的行。
因此,如果在 VENDING_MACHINES 表中插入全新的行(即新的自动售货机),则会在 VENDING_MACHINES_CHANGE_LOG 表中记录八行 - 每个非 ID 列都有一行。
这个“更改日志”旨在成为“售货机”表的永久历史记录,因此我们不会创建外键约束-如果从“售货机”中删除行,则要保留孤立的历史记录在更改日志中。此外,Apex不支持“ON UPDATE CASCADE”,因此触发器必须检查对ID列的更新,并手动在相关表(例如更改日志)中传播更新。
CREATE table "VENDING_MACHINE_CHANGE_LOG" (
"ID" NUMBER NOT NULL ENABLE,
"CHANGE_TIMESTAMP" TIMESTAMP(6) NOT NULL ENABLE,
"VENDING_MACHINE_ID" NUMBER NOT NULL ENABLE,
"MODIFIED_COLUMN_NAME" VARCHAR2(30) NOT NULL ENABLE,
"MODIFIED_COLUMN_TYPE" VARCHAR2(30) GENERATED ALWAYS AS
(CASE "MODIFIED_COLUMN_NAME" WHEN 'FACILITIES_ADDRESS' THEN 'TEXT'
WHEN 'FACILITIES_CONTACT' THEN 'TEXT'
ELSE 'NUMBER' END) VIRTUAL NOT NULL ENABLE,
"NEW_NUMBER_VALUE" NUMBER,
"NEW_TEXT_VALUE" VARCHAR2(4000),
CONSTRAINT "VENDING_MACHINE_CHANGE_LOG_CK" CHECK
("MODIFIED_COLUMN_NAME" IN('SNICKERS_COUNT', 'MILKY_WAY_COUNT', 'TWIX_COUNT',
'SKITTLES_COUNT', 'STARBURST_COUNT', 'SWEDISH_FISH_COUNT',
'FACILITIES_ADDRESS', 'FACILITIES_CONTACT')) ENABLE,
CONSTRAINT "VENDING_MACHINE_CHANGE_LOG_PK" PRIMARY KEY ("ID") USING INDEX ENABLE,
CONSTRAINT "VENDING_MACHINE_CHANGE_LOG_UK" UNIQUE ("CHANGE_TIMESTAMP",
"VENDING_MACHINE_ID",
"MODIFIED_COLUMN_NAME") USING INDEX ENABLE
/* No foreign key, since we want this change log to be orphaned and preserved.
Also, apparently Apex doesn't support ON UPDATE CASCADE for some reason? */
)
/
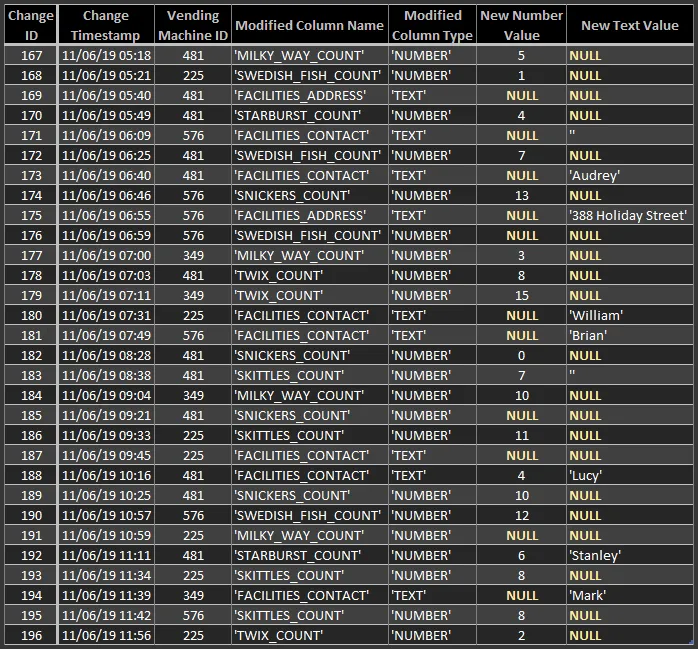
更改日志示例数据:
INSERT INTO VENDING_MACHINE_CHANGE_LOG (ID, CHANGE_TIMESTAMP, VENDING_MACHINE_ID,
MODIFIED_COLUMN_NAME, NEW_NUMBER_VALUE, NEW_TEXT_VALUE)
SELECT 167, '11/06/19 05:18', 481, 'MILKY_WAY_COUNT', 5, NULL FROM DUAL UNION ALL
SELECT 168, '11/06/19 05:21', 225, 'SWEDISH_FISH_COUNT', 1, NULL FROM DUAL UNION ALL
SELECT 169, '11/06/19 05:40', 481, 'FACILITIES_ADDRESS', NULL, NULL FROM DUAL UNION ALL
SELECT 170, '11/06/19 05:49', 481, 'STARBURST_COUNT', 4, NULL FROM DUAL UNION ALL
SELECT 171, '11/06/19 06:09', 576, 'FACILITIES_CONTACT', NULL, '' FROM DUAL UNION ALL
SELECT 172, '11/06/19 06:25', 481, 'SWEDISH_FISH_COUNT', 7, NULL FROM DUAL UNION ALL
SELECT 173, '11/06/19 06:40', 481, 'FACILITIES_CONTACT', NULL, 'Audrey' FROM DUAL UNION ALL
SELECT 174, '11/06/19 06:46', 576, 'SNICKERS_COUNT', 13, NULL FROM DUAL UNION ALL
SELECT 175, '11/06/19 06:55', 576, 'FACILITIES_ADDRESS', NULL, '388 Holiday Street' FROM DUAL UNION ALL
SELECT 176, '11/06/19 06:59', 576, 'SWEDISH_FISH_COUNT', NULL, NULL FROM DUAL UNION ALL
SELECT 177, '11/06/19 07:00', 349, 'MILKY_WAY_COUNT', 3, NULL FROM DUAL UNION ALL
SELECT 178, '11/06/19 07:03', 481, 'TWIX_COUNT', 8, NULL FROM DUAL UNION ALL
SELECT 179, '11/06/19 07:11', 349, 'TWIX_COUNT', 15, NULL FROM DUAL UNION ALL
SELECT 180, '11/06/19 07:31', 225, 'FACILITIES_CONTACT', NULL, 'William' FROM DUAL UNION ALL
SELECT 181, '11/06/19 07:49', 576, 'FACILITIES_CONTACT', NULL, 'Brian' FROM DUAL UNION ALL
SELECT 182, '11/06/19 08:28', 481, 'SNICKERS_COUNT', 0, NULL FROM DUAL UNION ALL
SELECT 183, '11/06/19 08:38', 481, 'SKITTLES_COUNT', 7, '' FROM DUAL UNION ALL
SELECT 184, '11/06/19 09:04', 349, 'MILKY_WAY_COUNT', 10, NULL FROM DUAL UNION ALL
SELECT 185, '11/06/19 09:21', 481, 'SNICKERS_COUNT', NULL, NULL FROM DUAL UNION ALL
SELECT 186, '11/06/19 09:33', 225, 'SKITTLES_COUNT', 11, NULL FROM DUAL UNION ALL
SELECT 187, '11/06/19 09:45', 225, 'FACILITIES_CONTACT', NULL, NULL FROM DUAL UNION ALL
SELECT 188, '11/06/19 10:16', 481, 'FACILITIES_CONTACT', 4, 'Lucy' FROM DUAL UNION ALL
SELECT 189, '11/06/19 10:25', 481, 'SNICKERS_COUNT', 10, NULL FROM DUAL UNION ALL
SELECT 190, '11/06/19 10:57', 576, 'SWEDISH_FISH_COUNT', 12, NULL FROM DUAL UNION ALL
SELECT 191, '11/06/19 10:59', 225, 'MILKY_WAY_COUNT', NULL, NULL FROM DUAL UNION ALL
SELECT 192, '11/06/19 11:11', 481, 'STARBURST_COUNT', 6, 'Stanley' FROM DUAL UNION ALL
SELECT 193, '11/06/19 11:34', 225, 'SKITTLES_COUNT', 8, NULL FROM DUAL UNION ALL
SELECT 194, '11/06/19 11:39', 349, 'FACILITIES_CONTACT', NULL, 'Mark' FROM DUAL UNION ALL
SELECT 195, '11/06/19 11:42', 576, 'SKITTLES_COUNT', 8, NULL FROM DUAL UNION ALL
SELECT 196, '11/06/19 11:56', 225, 'TWIX_COUNT', 2, NULL FROM DUAL
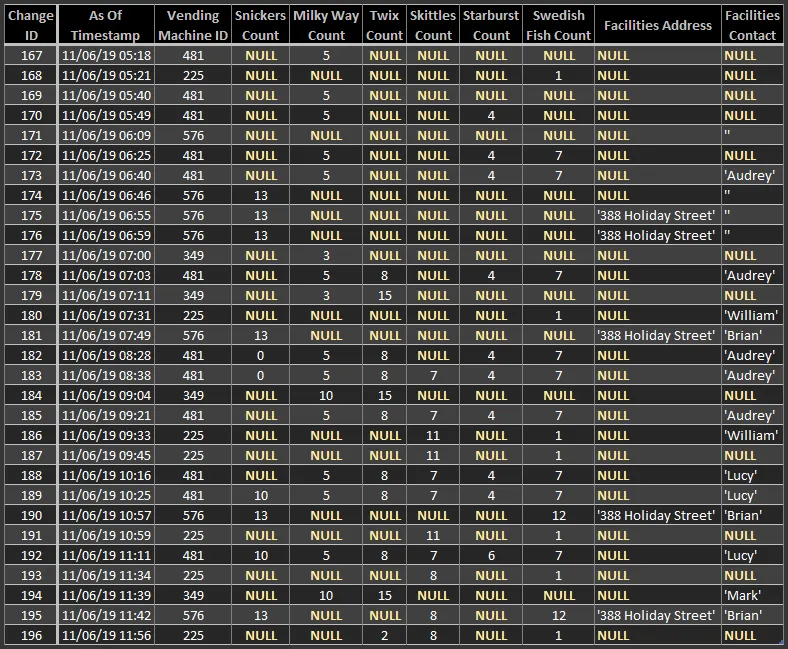
- 期望结果 - 查询(视图)从更改日志中重构历史表行
我需要构建一个视图,仅使用VENDING_MACHINE_CHANGE_LOG表中的数据,重构完整的历史VENDING_MACHINES表。
例如:由于更改日志行可以是孤立的,因此先前从VENDING_MACHINES删除的行应重新出现。
生成的视图应允许我检索任何VENDING_MACHINE行,正如它在历史上的任何特定时刻一样。
VENDING_MACHINE_CHANGE_LOG的示例数据非常简短,不足以产生完整的结果...
但这应该足以证明所需的结果。
最终,我认为需要使用分析函数。
但我对SQL分析函数和Oracle以及Apex都很陌生。
因此,我不知道如何解决这个问题-重构原始表行的最佳方法是什么?
以下是期望结果的样子(按CHANGE_TIMESTAMP排序):
这里是相同的期望结果,此外还按VENDING_MACHINE_ID排序:
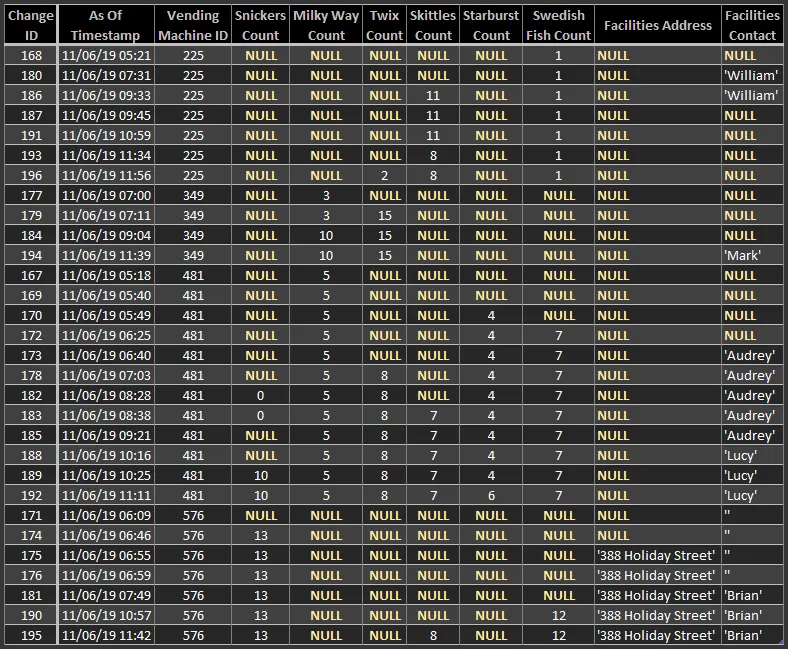
VENDING_MACHINE_ID 最近的列值,但我认为这种方法不适合处理如此庞大的任务。我想使用分析函数来获得更好的性能和灵活性。(或者我错了?)select vmcl.ID,
vmcl.CHANGE_TIMESTAMP,
vmcl.VENDING_MACHINE_ID,
vmcl.MODIFIED_COLUMN_NAME,
vmcl.MODIFIED_COLUMN_TYPE,
vmcl.NEW_NUMBER_VALUE,
vmcl.NEW_TEXT_VALUE
from ( select sqvmcl.VENDING_MACHINE_ID,
sqvmcl.MODIFIED_COLUMN_NAME,
max(sqvmcl.CHANGE_TIMESTAMP) as LAST_CHANGE_TIMESTAMP
from VENDING_MACHINE_CHANGE_LOG sqvmcl
where sqvmcl.CHANGE_TIMESTAMP <= /*[Current timestamp, or specified timestamp]*/
group by sqvmcl.VENDING_MACHINE_ID, sqvmcl.MODIFIED_COLUMN_NAME ) sq
left join VENDING_MACHINE_CHANGE_LOG vmcl on vmcl.VENDING_MACHINE_ID = sq.VENDING_MACHINE_ID
and vmcl.MODIFIED_COLUMN_NAME = sq.MODIFIED_COLUMN_NAME
and vmcl.CHANGE_TIMESTAMP = sq.LAST_CHANGE_TIMESTAMP
请注意,
left join 特别命中 VENDING_MACHINE_CHANGE_LOG 表的唯一索引 - 这是有意设计的。