有一个字符串$processhtml包含一些HTML代码。我想使用PHP从HTML中删除所有链接标签及其内容。
举个例子:
"This is some text with <a href="#">link</a>"
必须成为:
"This is some text with"
我需要在DOMDocument的帮助下对HTML进行其他解析,因此尝试查找与DOM相关的解决方案。
我已经尝试过:
$dom = new DOMDocument();
@$dom->loadHtml($processhtml);
foreach ($dom->getElementsByTagName('*') as $element) {
if ($element->nodeName == 'a') {
$element->parentNode->removeChild($element);
}
}
echo $dom->saveHTML();
结果如下:
一些链接完全被移除了(不错)
一些链接被替换成“问号”字符(奇怪)
一些链接没有改变(不好)
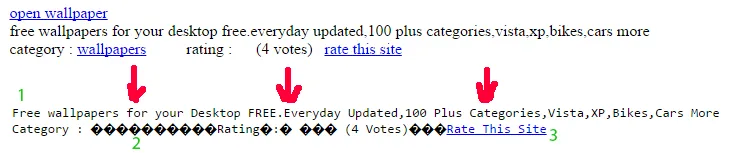
所以我的问题是:
1)是什么导致了我使用的代码不一致?如何解决?
2)有没有更好的方法来实现所需的功能?(正则表达式不行:P)
提前谢谢!
<a ...>和</a>之间的内容呢?它也必须被删除。 - Acidon