我正在使用正则表达式模式匹配和其他方法解决一个问题(搜索问题)。 我想看看Google,Yahoo,Bing,Ask等搜索引擎的行为。
考虑到Firefox,Chrome,Opera和其他浏览器也有URL栏或搜索栏,我开始尝试不同的单词,然后是符号。
在Firefox中,我看到了许多不同的结果。以下是一些截图-
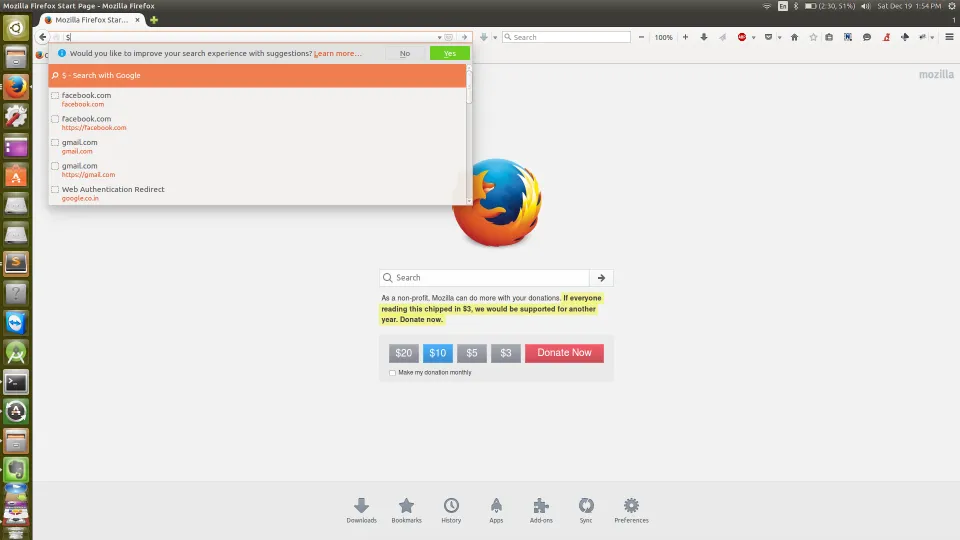
^ 符号 - 给出一些随机结果。
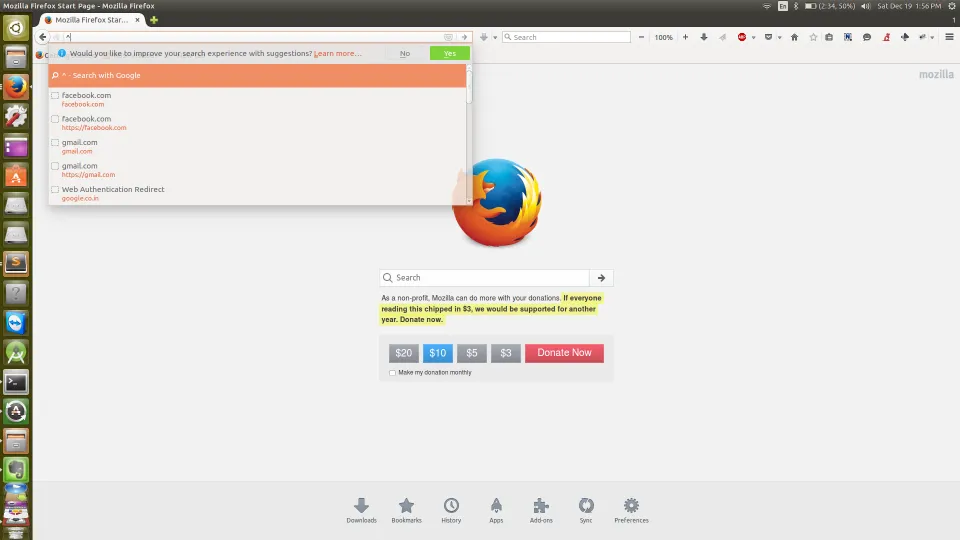
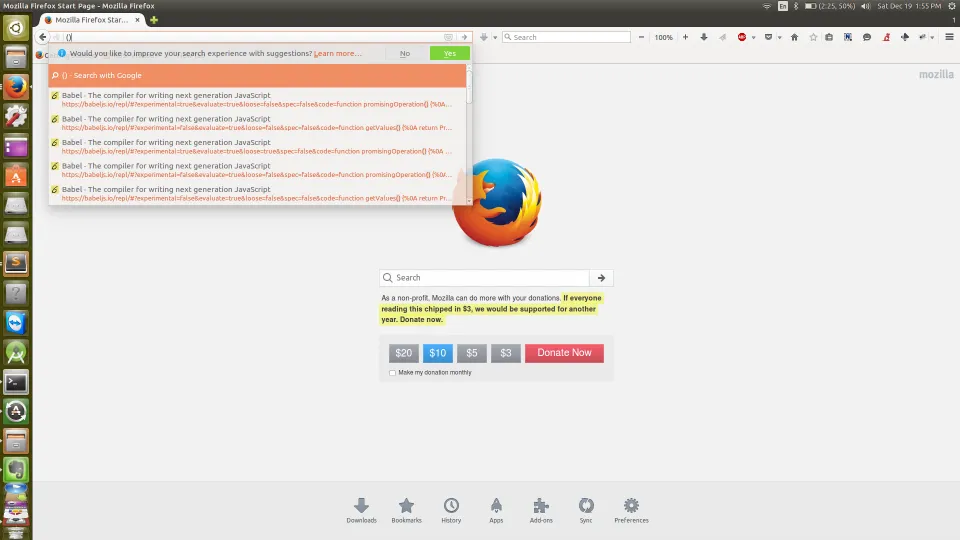
()括号 - 当使用时可以得到正确的结果。它被视为一种比较类似字符串的符号。
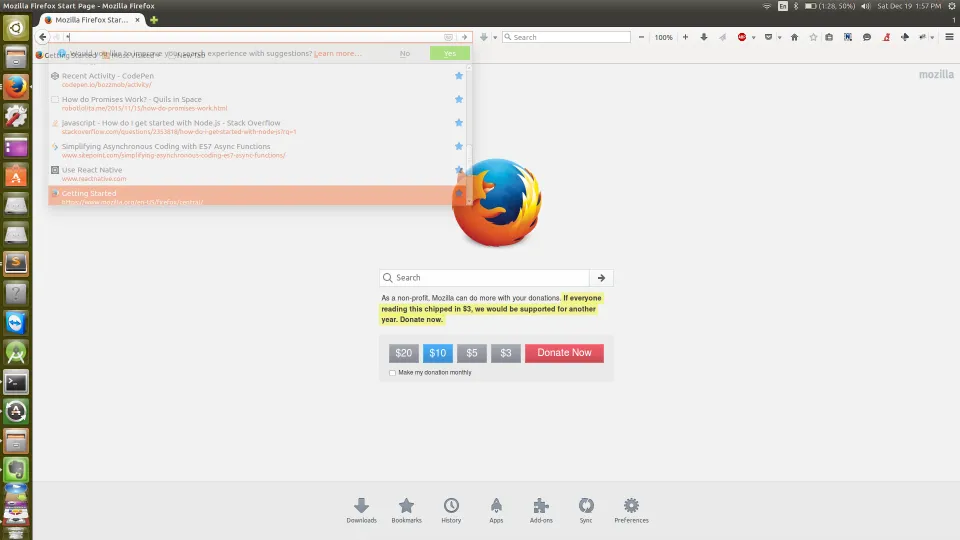
*符号 - 这也给出了一组没有符号本身匹配的结果。不确定为什么会有这些不同的结果。
~符号 - 这也给出了一组没有符号本身匹配的结果。不确定为什么会有这些不同的结果。
我很想知道为什么许多符号的行为有如此大的差异,而其他字符串和/或符号则按预期工作。
-
@thanksd并不是一个重复。那个是关于字符串匹配的工作原理。我已经知道了那部分内容。我很明显在问符号。符号如何被考虑用于匹配。
textFromtheWholeOfTheInternet.match(new RegExp('.*' + urlbar.value + '.*'));- 考虑到它需要在每次按键时匹配整个互联网的内容,速度相当快。 - Jaromanda Xurlbar.value首先要通过某种RegExp.escape进行清理。然后就可以安全地匹配整个互联网的内容了 :P - Oriol