我有以下代码用于创建一个绘图。在
请问是否有其他的符号代替我的
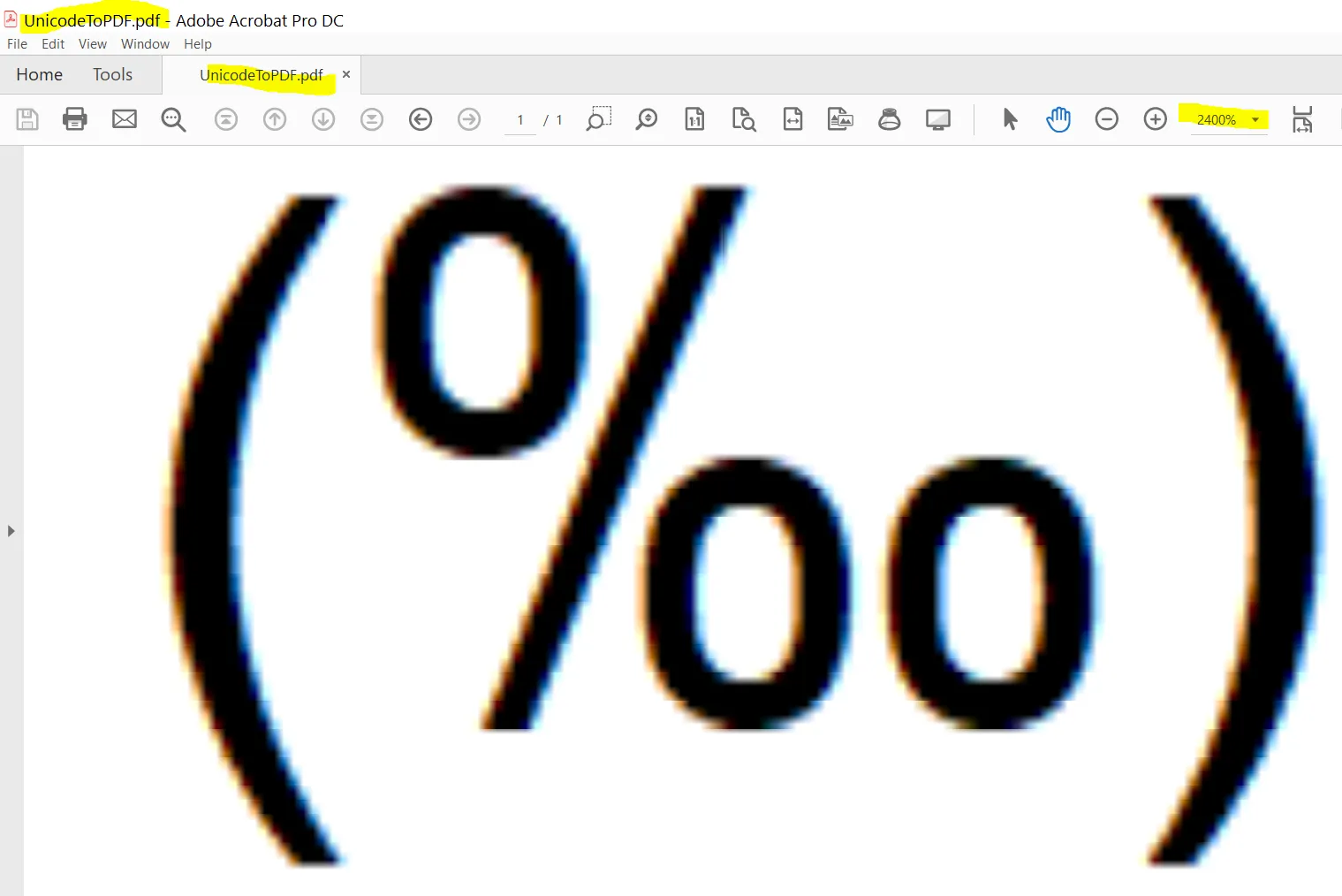
x轴和y轴上,屏幕上会显示符号,当我将绘图保存为JPEG格式时,它们会出现在图片中,但是当我将绘图保存为PDF时则不会出现。请问是否有其他的符号代替我的
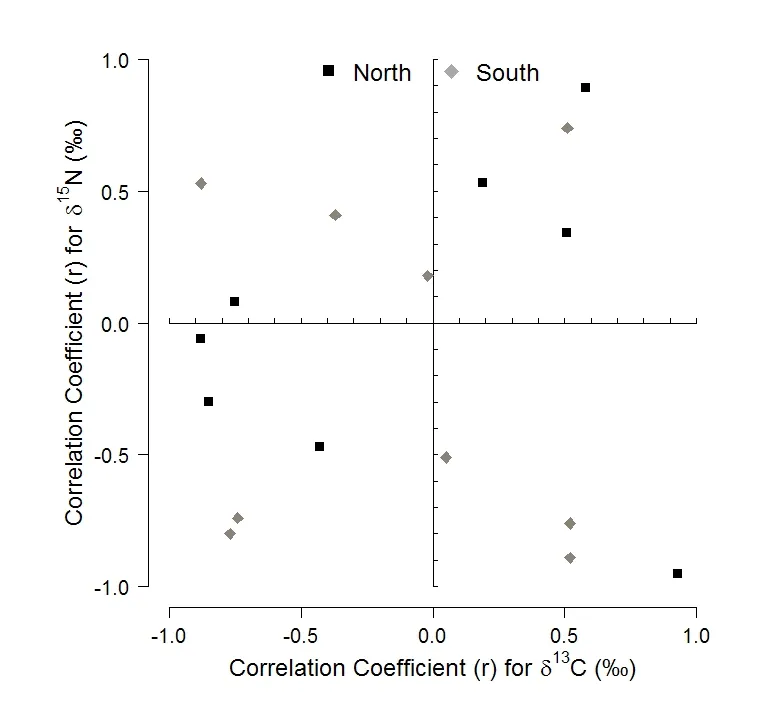
\u2030能够在PDF中打印出来?或者是否有其他解决方案?以下是正确(JPEG格式)和不正确(PDF格式)绘图的示例。plot(c(-1,1), c(-1,1), bty = "n", type= "n", las = 1, cex.lab = 1.5, cex.axis = 1.25, main = NULL,
ylab=expression(paste("Correlation Coefficient (r) for ", delta ^{15},"N"," \u0028","\u2030","\u0029")),
xlab=expression(paste("Correlation Coefficient (r) for ", delta ^{13},"C"," \u0028","\u2030","\u0029")))
axis(1, at = seq(-1.0, 1.0, by = 0.1), labels = F, pos = 0, cex.axis = 0.05, tcl = 0.25)
axis(2, at = seq(-1.0, 1.0, by = 0.1), labels = F, pos = 0, cex.axis = 0.05, tcl = 0.25)
cairo_pdf? - Roman LuštriktikzDevice包(目前被从CRAN流放)。你尝试过使用symbol(),例如?plotmath吗?另请参见https://dev59.com/OW025IYBdhLWcg3wpXod [你在使用cairo_pdf时遇到了什么错误?在类似情况下,它对我有效] - Ben Bolkercairo_pdf可以解决问题,正如许多人在这里指出的那样。ggplot2中的cairo_pdf似乎也可以正确地重现特定于操作系统的permil符号。即,如果您只键入"‰"而不是\u2030。 - Mikko