语义搜索示例
以下是基于OpenAI API使用嵌入的语义搜索示例。
错误的目标:OpenAI API应该在提示与微调数据集中的提示相似时从微调数据集中回答
这是完全错误的逻辑。忘掉微调吧。正如官方OpenAI文档所述:
通过提供以下内容,微调使您能够更好地利用API可用的模型:
- 比提示设计更高质量的结果
- 能够训练更多无法适应提示的示例
- 由于提示较短而节省令牌
- 请求延迟较低
微调通过在许多无法适应提示的示例上进行训练,改进了少样本学习,使您能够在广泛的任务上取得更好的结果。
微调并不是指从微调数据集中回答特定问题的特定答案。换句话说,微调模型不知道对于给定的问题应该给出什么答案。它无法读取你的思想。你将得到一个基于微调模型所具有的所有知识的答案,其中:微调模型的知识=默认知识(即微调之前模型已经具备的知识)+微调知识(即你通过微调添加到模型中的知识)。
尽管GPT-3模型拥有很多通用知识,但有时我们希望模型能够针对给定的特定问题给出一个具体的答案(即“事实”)。如果微调不是正确的方法,那么什么才是呢?
正确的目标:当被问到一个“事实”时,回答一个“事实”,否则使用OpenAI API进行回答。
正确的方法是基于嵌入向量的语义搜索,我们使用余弦相似度将它们相互比较,以找到给定特定问题的“事实”。请参见下面的示例和详细描述。
注意:为了更好地(视觉上)理解,以下代码在Jupyter中运行和测试。
步骤1:创建一个包含“事实”的.csv文件
为了简单起见,让我们添加两个公司(即ABC和XYZ)的内容。在我们的案例中,内容将是公司的一句话描述。
companies.csv

运行
print_dataframe.ipynb 来打印数据框。
print_dataframe.ipynb
import pandas as pd
df = pd.read_csv('companies.csv')
df
我们应该得到以下输出:

第二步:为每个“事实”计算一个嵌入向量
嵌入是一组数字向量,帮助我们理解文本在语义上相似或不同。两个嵌入向量越接近,它们的内容就越相似(来源)。
让我们先测试嵌入终端点。使用输入This is a test运行get_embedding.ipynb。
注意:在嵌入终端点的情况下,参数prompt被称为input。
get_embedding.ipynb
import openai
import os
openai.api_key = os.getenv('OPENAI_API_KEY')
def get_embedding(model: str, text: str) -> list[float]:
result = openai.Embedding.create(
model = model,
input = text
)
return result['data'][0]['embedding']
print(get_embedding('text-embedding-ada-002', 'This is a test'))
我们应该得到以下输出:

在上面的屏幕截图中,我们看到的是这是一个测试作为嵌入向量。更准确地说,我们得到了一个1536维的嵌入向量(即内部有1536个数字)。你可能熟悉三维空间(即X、Y、Z)。嗯,这是一个1536维的空间,很难想象。
现在我们需要理解两件事:
- 为什么我们需要将文本转换为嵌入向量(即数字)?之后,我们可以比较嵌入向量并确定两个文本的相似程度。我们不能直接比较文本。
- 为什么嵌入向量中恰好有1536个数字?因为
text-embedding-ada-002模型的输出维度是1536。这是预定义的。
现在我们可以为每个“事实”创建一个嵌入向量。运行get_all_embeddings.ipynb。
get_all_embeddings.ipynb
import openai
from openai.embeddings_utils import get_embedding
import pandas as pd
import os
openai.api_key = os.getenv('OPENAI_API_KEY')
df = pd.read_csv('companies.csv')
df['embedding'] = df['content'].apply(lambda x: get_embedding(x, engine = 'text-embedding-ada-002'))
df.to_csv('companies_embeddings.csv')
上面的代码将获取第一个公司(即
x),获取其
'content'(即"fact"),并使用
text-embedding-ada-002模型应用函数
get_embedding。它将把第一个公司的嵌入向量保存在名为
'embedding'的新列中。然后,它将获取第二个公司、第三个公司、第四个公司等等。最后,该代码将自动生成一个名为
companies_embeddings.csv的新的
.csv文件。
将嵌入向量本地保存(即保存在
.csv文件中)意味着我们不必每次需要它们时都调用OpenAI API。我们只需为给定的"fact"计算一次嵌入向量,就可以了。
运行
print_dataframe_embeddings.ipynb以打印带有名为
'embedding'的新列的数据框。
print_dataframe_embeddings.ipynb
import pandas as pd
import numpy as np
df = pd.read_csv('companies_embeddings.csv')
df['embedding'] = df['embedding'].apply(eval).apply(np.array)
df
我们应该得到以下输出:

第三步:为输入计算一个嵌入向量,并使用
余弦相似度将其与
companies_embeddings.csv中的嵌入向量进行比较。
我们需要为输入计算一个嵌入向量,以便我们可以将输入与给定的“事实”进行比较,并查看这两个文本有多相似。实际上,我们将输入的嵌入向量与“事实”的嵌入向量进行比较。然后我们将输入与第二个“事实”,第三个“事实”,第四个“事实”等进行比较。运行
get_cosine_similarity.ipynb。
get_cosine_similarity.ipynb
import openai
from openai.embeddings_utils import cosine_similarity
import pandas as pd
import os
openai.api_key = os.getenv('OPENAI_API_KEY')
my_model = 'text-embedding-ada-002'
my_input = '<INSERT_INPUT_HERE>'
def get_embedding(model: str, text: str) -> list[float]:
result = openai.Embedding.create(
model = my_model,
input = my_input
)
return result['data'][0]['embedding']
input_embedding_vector = get_embedding(my_model, my_input)
df = pd.read_csv('companies_embeddings.csv')
df['embedding'] = df['embedding'].apply(eval).apply(np.array)
df['similarity'] = df['embedding'].apply(lambda x: cosine_similarity(x, input_embedding_vector))
df
上面的代码将获取输入并与第一个事实进行比较。它会将两者的相似度计算结果保存在名为“similarity”的新列中。然后它会依次处理第二个事实、第三个事实、第四个事实等。
如果
my_input = '告诉我关于ABC公司的一些信息':

如果我的输入是 '告诉我一些关于XYZ公司的信息':

如果
my_input = '告诉我一些关于苹果公司的信息':

我们可以看到,当我们将“Tell me something about company ABC”作为输入时,它与第一个“fact”最相似。当我们将“Tell me something about company XYZ”作为输入时,它与第二个“fact”最相似。然而,如果我们将“Tell me something about company Apple”作为输入,它与这两个“facts”中的任何一个都最不相似。
第四步:如果相似度超过我们的阈值,则用最相似的“fact”回答;否则使用OpenAI API回答。
让我们将相似度阈值设置为“>= 0.9”。如果相似度“>= 0.9”,下面的代码应该用最相似的“fact”回答;否则使用OpenAI API回答。运行“get_answer.ipynb”。
get_answer.ipynb
import openai
from openai.embeddings_utils import cosine_similarity
import pandas as pd
import numpy as np
import os
openai.api_key = os.getenv('OPENAI_API_KEY')
my_model = 'text-embedding-ada-002'
my_input = '<INSERT_INPUT_HERE>'
def get_embedding(model: str, text: str) -> list[float]:
result = openai.Embedding.create(
model = my_model,
input = my_input
)
return result['data'][0]['embedding']
input_embedding_vector = get_embedding(my_model, my_input)
df = pd.read_csv('companies_embeddings.csv')
df['embedding'] = df['embedding'].apply(eval).apply(np.array)
df['similarity'] = df['embedding'].apply(lambda x: cosine_similarity(x, input_embedding_vector))
highest_similarity = df['similarity'].max()
if highest_similarity >= 0.9:
fact_with_highest_similarity = df.loc[df['similarity'] == highest_similarity, 'content']
print(fact_with_highest_similarity)
else:
response = openai.Completion.create(
model = 'text-davinci-003',
prompt = my_input,
max_tokens = 30,
temperature = 0
)
content = response['choices'][0]['text'].replace('\n', '')
print(content)
如果
my_input = '告诉我一些关于ABC公司的信息',并且阈值为
>= 0.9,我们应该从
companies_embeddings.csv中得到以下答案:

如果我的输入是'Tell me something about company XYZ',并且阈值为>= 0.9,我们应该从companies_embeddings.csv中得到以下答案:

如果
my_input = '告诉我一些关于苹果公司的信息',并且阈值为
>= 0.9,我们应该从OpenAI API中得到以下答案:
。

额外的技巧和建议
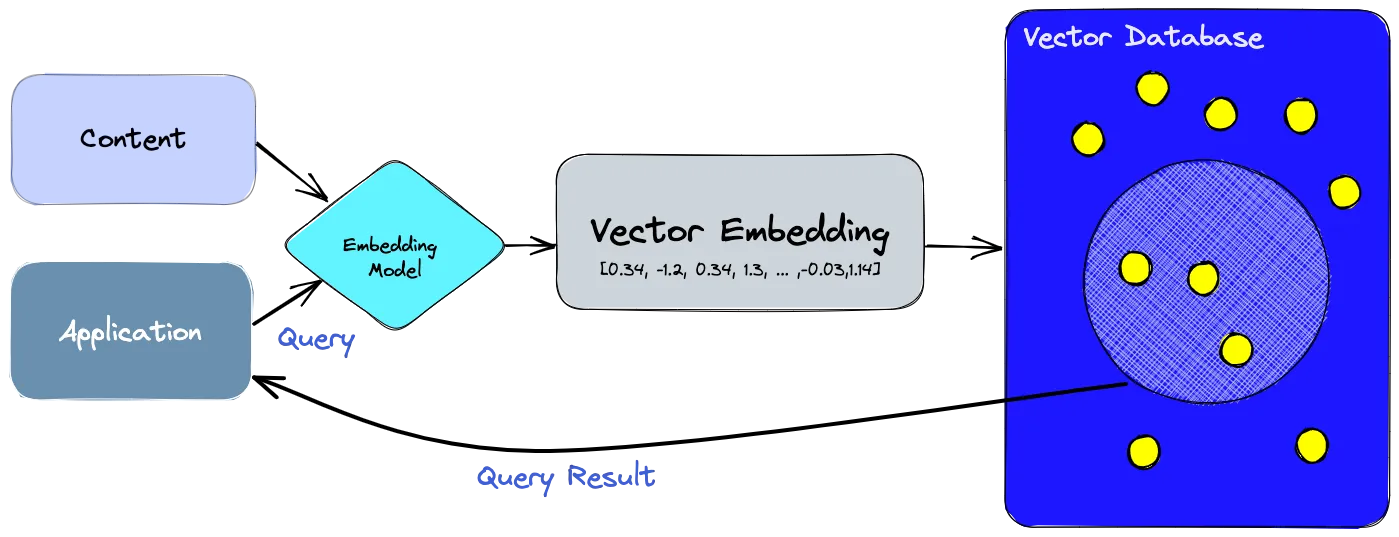
你可以使用Pinecone来存储嵌入向量,正如官方Pinecone文章所述:
嵌入向量是由人工智能模型(如大型语言模型)生成的,具有大量属性或特征,使得它们的表示方式具有挑战性。在人工智能和机器学习的背景下,这些特征代表了数据的不同维度,对于理解模式、关系和潜在结构至关重要。
这就是为什么我们需要一个专门设计用于处理这种类型数据的数据库。像Pinecone这样的向量数据库通过提供针对嵌入向量的优化存储和查询功能来满足这一需求。向量数据库具备传统数据库的功能,而独立的向量索引则缺乏这些功能,并且专门处理向量嵌入,这是传统基于标量的数据库所缺乏的。
davinci、curie、babbage和ada。您不能微调GPT-4模型。即使您可以,我仍然认为使用嵌入是获取个性化响应的最佳(如果不是唯一)方法。 - Rok Benko