我正在使用ELK(Elasticsearch、Kibana、Logstash、Filebeat)来收集日志。我有一个日志文件,其中每行都有一个JSON对象。我的目标是使用Logstash Grok从JSON对象中提取键/值对并将其转发到Elasticsearch。
2018-03-28 13:23:01 charge:{"oldbalance":5000,"managefee":0,"afterbalance":"5001","cardid":"123456789","txamt":1}
2018-03-28 13:23:01 manage:{"cuurentValue":5000,"payment":0,"newbalance":"5001","posid":"123456789","something":"new2","additionalFields":1}
我正在使用Grok调试器来创建正则表达式模式并查看结果。我当前的正则表达式是:
%{TIMESTAMP_ISO8601} %{SPACE} %{WORD:$:data}:{%{QUOTEDSTRING:key1}:%{BASE10NUM:value1}[,}]%{QUOTEDSTRING:key2}:%{BASE10NUM:value2}[,}]%{QUOTEDSTRING:key3}:%{QUOTEDSTRING:value3}[,}]%{QUOTEDSTRING:key4}:%{QUOTEDSTRING:value4}[,}]%{QUOTEDSTRING:key5}:%{BASE10NUM:value5}[,}]
正如您所见,这段代码是硬编码的,因为真实日志中json的键可以是任何单词,值可以是整数、双精度数或字符串,而且键的长度也会变化。因此,我的解决方案不可行。下面是我提供的解决方案结果,仅供参考。我正在使用Grok patterns。
我的问题是,在elastic search中使用json,是否明智尝试提取json中的键?其次,如果我尝试从json中取出键/值,是否有正确简洁的Grok模式?
当前的Grok模式在解析上述行的第一行时给出以下输出:
{
"TIMESTAMP_ISO8601": [
[
"2018-03-28 13:23:01"
]
],
"YEAR": [
[
"2018"
]
],
"MONTHNUM": [
[
"03"
]
],
"MONTHDAY": [
[
"28"
]
],
"HOUR": [
[
"13",
null
]
],
"MINUTE": [
[
"23",
null
]
],
"SECOND": [
[
"01"
]
],
"ISO8601_TIMEZONE": [
[
null
]
],
"SPACE": [
[
""
]
],
"WORD": [
[
"charge"
]
],
"key1": [
[
""oldbalance""
]
],
"value1": [
[
"5000"
]
],
"key2": [
[
""managefee""
]
],
"value2": [
[
"0"
]
],
"key3": [
[
""afterbalance""
]
],
"value3": [
[
""5001""
]
],
"key4": [
[
""cardid""
]
],
"value4": [
[
""123456789""
]
],
"key5": [
[
""txamt""
]
],
"value5": [
[
"1"
]
]
}
第二次编辑
能否使用Logstash的Json过滤器?但在我的情况下,Json是行/事件的一部分,而不是整个事件都是Json。
===========================================================
第三版
我没有看到更新后的解决方案能够成功解析json。我的正则表达式如下:
filter {
grok {
match => {
"message" => [
"%{TIMESTAMP_ISO8601}%{SPACE}%{GREEDYDATA:json_data}"
]
}
}
}
filter {
json{
source => "json_data"
target => "parsed_json"
}
}
它没有键值对,而是msg+json字符串。解析后的json不是已解析的。
测试数据如下:
2018-03-28 13:23:01 manage:{"cuurentValue":5000,"payment":0,"newbalance":"5001","posid":"123456789","something":"new2","additionalFields":1}
2018-03-28 13:23:03 payment:{"cuurentValue":5001,"reload":0,"newbalance":"5002","posid":"987654321","something":"new3","additionalFields":2}
2018-03-28 13:24:07 management:{"cuurentValue":5002,"payment":0,"newbalance":"5001","posid":"123456789","something":"new2","additionalFields":1}
[2018-06-04T15:01:30,017][WARN ][logstash.filters.json ] Error parsing json {:source=>"json_data", :raw=>"manage:{\"cuurentValue\":5000,\"payment\":0,\"newbalance\":\"5001\",\"posid\":\"123456789\",\"something\":\"new2\",\"additionalFields\":1}", :exception=>#<LogStash::Json::ParserError: Unrecognized token 'manage': was expecting ('true', 'false' or 'null')
at [Source: (byte[])"manage:{"cuurentValue":5000,"payment":0,"newbalance":"5001","posid":"123456789","something":"new2","additionalFields":1}"; line: 1, column: 8]>}
[2018-06-04T15:01:30,017][WARN ][logstash.filters.json ] Error parsing json {:source=>"json_data", :raw=>"payment:{\"cuurentValue\":5001,\"reload\":0,\"newbalance\":\"5002\",\"posid\":\"987654321\",\"something\":\"new3\",\"additionalFields\":2}", :exception=>#<LogStash::Json::ParserError: Unrecognized token 'payment': was expecting ('true', 'false' or 'null')
at [Source: (byte[])"payment:{"cuurentValue":5001,"reload":0,"newbalance":"5002","posid":"987654321","something":"new3","additionalFields":2}"; line: 1, column: 9]>}
[2018-06-04T15:01:34,986][WARN ][logstash.filters.json ] Error parsing json {:source=>"json_data", :raw=>"management:{\"cuurentValue\":5002,\"payment\":0,\"newbalance\":\"5001\",\"posid\":\"123456789\",\"something\":\"new2\",\"additionalFields\":1}", :exception=>#<LogStash::Json::ParserError: Unrecognized token 'management': was expecting ('true', 'false' or 'null')
at [Source: (byte[])"management:{"cuurentValue":5002,"payment":0,"newbalance":"5001","posid":"123456789","something":"new2","additionalFields":1}"; line: 1, column: 12]>}
请查看结果:
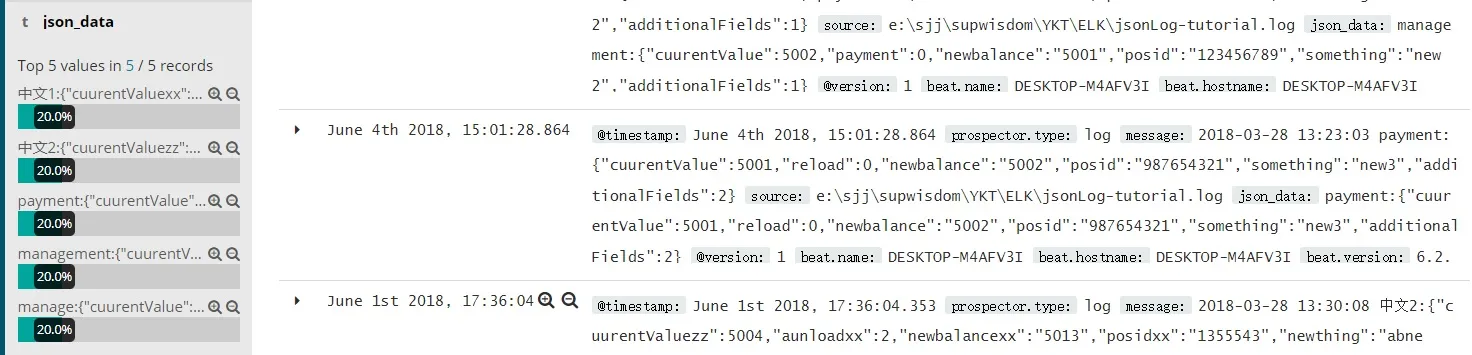
%{TIMESTAMP_ISO8601}%{SPACE}%{WORD}:%{GREEDYDATA:json_data}- Sufiyan Ghori