我将使用Python解析一个相当复杂的XML文件,其中有许多嵌套的子元素;访问其中一些值非常麻烦,因为代码开始变得非常难看。
首先让我介绍一下这个XML文件:
我的目标是以比我下面示例代码更好的方式访问名为“GOAL”的子项中包含的值。此外,我想找到一种自动化的方式来查找具有相同类型标记的GOALS的值,这些标记属于具有相同名称的不同子项:
例如:GIOVANNI和ANDREA都位于同一种标记(
以下是我编写的代码:
我想要的输出应该像这样:
如您所见,我能够轻松读取
第二件事是以自动化的方式获取
注意:如您所见,我无法读取
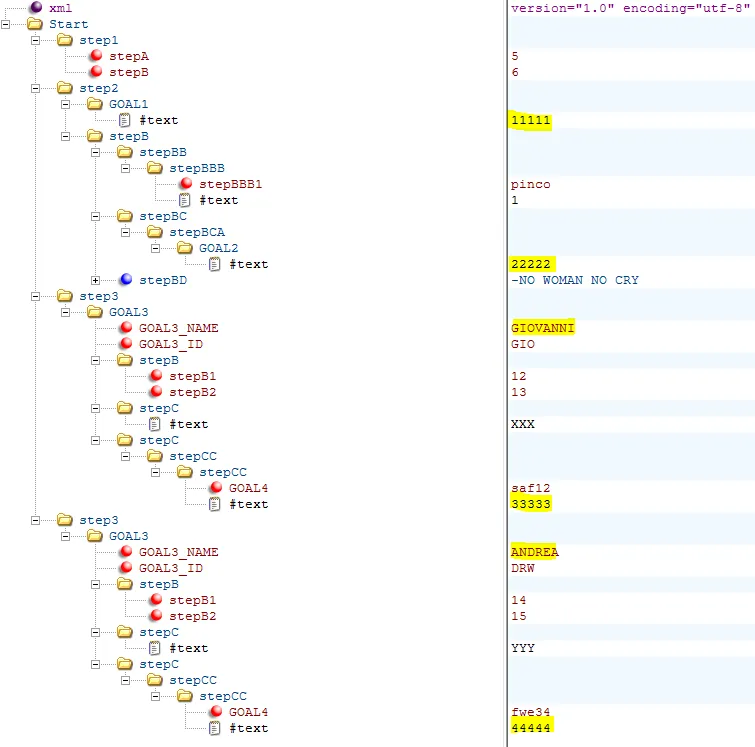
为了使.xml文件结构更易于理解,我发布了一个图像,展示了它的外观。
首先让我介绍一下这个XML文件:
<?xml version="1.0" encoding="utf-8"?>
<Start>
<step1 stepA="5" stepB="6" />
<step2>
<GOAL1>11111</GOAL1>
<stepB>
<stepBB>
<stepBBB stepBBB1="pinco">1</stepBBB>
</stepBB>
<stepBC>
<stepBCA>
<GOAL2>22222</GOAL2>
</stepBCA>
</stepBC>
<stepBD>-NO WOMAN NO CRY
-I SHOT THE SHERIF
-WHO LET THE DOGS OUT
</stepBD>
</stepB>
</step2>
<step3>
<GOAL3 GOAL3_NAME="GIOVANNI" GOAL3_ID="GIO">
<stepB stepB1="12" stepB2="13" />
<stepC>XXX</stepC>
<stepC>
<stepCC>
<stepCC GOAL4="saf12">33333</stepCC>
</stepCC>
</stepC>
</GOAL3>
</step3>
<step3>
<GOAL3 GOAL3_NAME="ANDREA" GOAL3_ID="DRW">
<stepB stepB1="14" stepB2="15" />
<stepC>YYY</stepC>
<stepC>
<stepCC>
<stepCC GOAL4="fwe34">44444</stepCC>
</stepCC>
</stepC>
</GOAL3>
</step3>
</Start>
我的目标是以比我下面示例代码更好的方式访问名为“GOAL”的子项中包含的值。此外,我想找到一种自动化的方式来查找具有相同类型标记的GOALS的值,这些标记属于具有相同名称的不同子项:
例如:GIOVANNI和ANDREA都位于同一种标记(
GOAL3_NAME)下,并属于具有相同名称(<step3>)的不同子项。以下是我编写的代码:
import xml.etree.ElementTree as ET
data = ET.parse('test.xml').getroot()
GOAL1 = data.getchildren()[1].getchildren()[0].text
print(GOAL1)
GOAL2 = data.getchildren()[1].getchildren()[1].getchildren()[1].getchildren()[0].getchildren()[0].text
print(GOAL2)
GOAL3 = data.getchildren()[2].getchildren()[0].text
print(GOAL3)
GOAL4_A = data.getchildren()[2].getchildren()[0].getchildren()[2].getchildren()[0].getchildren()[0].text
print(GOAL4_A)
GOAL4_B = data.getchildren()[3].getchildren()[0].getchildren()[2].getchildren()[0].getchildren()[0].text
print(GOAL4_B)
我得到的输出如下:
11111
22222
33333
44444
我想要的输出应该像这样:
11111
22222
GIOVANNI
33333
ANDREA
44444
如您所见,我能够轻松读取
GOAL1和GOAL2,但我正在寻找更好的代码实践来访问这些值,因为对我来说读/理解起来太长太难了。第二件事是以自动化的方式获取
GOAL3和GOAL4,这样我就不必重复编写类似的代码行,并使其更易读和理解。注意:如您所见,我无法读取
GOAL3。如果可能的话,我想同时获取GOAL3_NAME和GOAL3_ID。为了使.xml文件结构更易于理解,我发布了一个图像,展示了它的外观。