我想从像这样的字符串中提取数字:
我想从像这样的字符串中提取数字:
String numbers[] = "M0.286-3.099-0.44c-2.901,-0.436,,,123,0.123,.34".split(PATTERN);
我想从这个字符串中提取以下数字:
- 0.286
- -3.099
- -0.44
- -2.901
- -0.436
- 123
- 0.123
- .34
即:
- 可能会有垃圾字符,例如 "M"、"c"、"c"
- "-"符号是包括在数字中的,不是用来分割的
- 一个“数字”可以是任何
Float.parseFloat可以解析的内容,因此.34是有效的
我目前的进展如下:
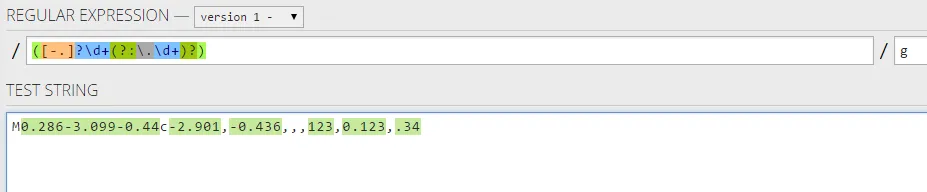
String PATTERN = "([^\\d.-]+)|(?=-)";
这种方法在某种程度上有效,但显然还远非完美:
- 无法跳过示例中的起始垃圾字符“M”
- 无法处理连续的垃圾字符,例如中间的
,,,
如何修复PATTERN以使其正常工作?
yourString.split(regex)或while(matcher.find()){...}也是可以接受的解决方案吗?在这种情况下,我反对使用split,因为它可能会在结果数组的开头创建额外的空元素,就像在"notNumber123NotNumber".split(regexForNotNumber)中返回["", "123"]一样。 - Pshemo