我正在尝试理解合成器论文 (https://arxiv.org/pdf/2005.00743.pdf 1),其中描述了密集型合成器机制,该机制应替换Transformer架构中描述的传统注意力模型。

密集合成器(Dense Synthesizer)的描述如下:

所以我尝试实现这个层,它看起来像这样,但我不确定我是否做对了:
class DenseSynthesizer(nn.Module):
def __init__(self, l, d):
super(DenseSynthesizer, self).__init__()
self.linear1 = nn.Linear(d, l)
self.linear2 = nn.Linear(l, l)
def forward(self, x, v):
# Equation (1) and (2)
# Shape: l x l
b = self.linear2(F.relu(self.linear1(x)))
# Equation (3)
# [l x l] x [l x d] -> [l x d]
return torch.matmul(F.softmax(b), v)
使用方法:
l, d = 4, 5
x, v = torch.rand(l, d), torch.rand(l, d)
synthesis = DenseSynthesizer(l, d)
synthesis(x, v)
例子:
x和v都是张量:
x = tensor([[0.0844, 0.2683, 0.4299, 0.1827, 0.1188],
[0.2793, 0.0389, 0.3834, 0.9897, 0.4197],
[0.1420, 0.8051, 0.1601, 0.3299, 0.3340],
[0.8908, 0.1066, 0.1140, 0.7145, 0.3619]])
v = tensor([[0.3806, 0.1775, 0.5457, 0.6746, 0.4505],
[0.6309, 0.2790, 0.7215, 0.4283, 0.5853],
[0.7548, 0.6887, 0.0426, 0.1057, 0.7895],
[0.1881, 0.5334, 0.6834, 0.4845, 0.1960]])
通过密集合成的前向传递,它返回:
>>> synthesis = DenseSynthesizer(l, d)
>>> synthesis(x, v)
tensor([[0.5371, 0.4528, 0.4560, 0.3735, 0.5492],
[0.5426, 0.4434, 0.4625, 0.3770, 0.5536],
[0.5362, 0.4477, 0.4658, 0.3769, 0.5468],
[0.5430, 0.4461, 0.4559, 0.3755, 0.5551]], grad_fn=<MmBackward>)
实现和理解密集合成器是否正确?
从理论上讲,它与接收两个不同输入并在前向传播的不同点利用它们的多层感知器有何不同?
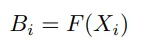

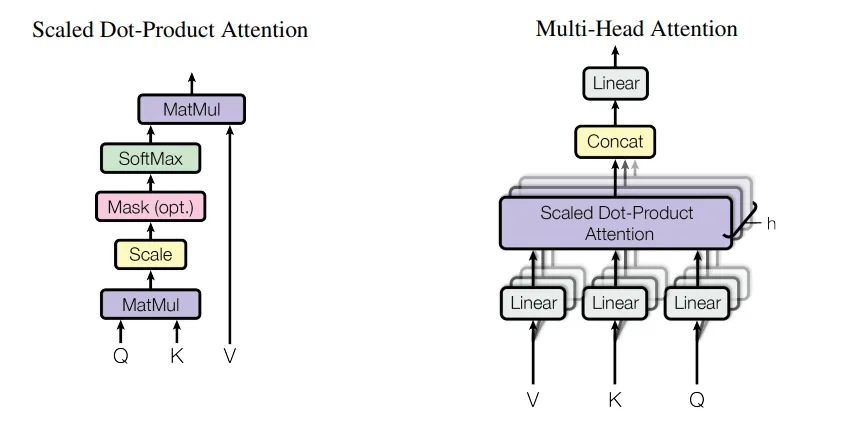
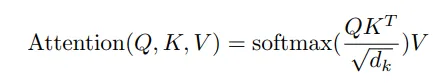
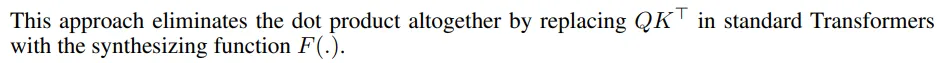
(d, l)和(l, l),就像你的实现一样,也可以是(d, d)和(d, l)。我认为后者可能效果更好。 - Mohammad Arvan(d, d)和(d, l)更符合QK^t注意力的对齐方式。 - Mohammad Arvan