据我理解,六边形架构的一个关键规则是将领域层与除了与之协作的应用层以外的所有内容隔离开来(领域层完全没有依赖项,因为它位于核心位置)。
加载运行业务逻辑所需的所有内容 -> 告诉领域层运行所有业务逻辑 -> 提取业务逻辑的结果并告诉基础架构层将其持久化 ->
在这种意义上,应用层是否总是需要跟踪领域层计算出的任何结果,并因此始终实现某种UnitOfWork模式来跟踪这些结果?
领域层是否会使用存储库或存储库接口进行任何工作?有些来源似乎表明这是可以的,但从我的角度来看,这与图表完全矛盾。
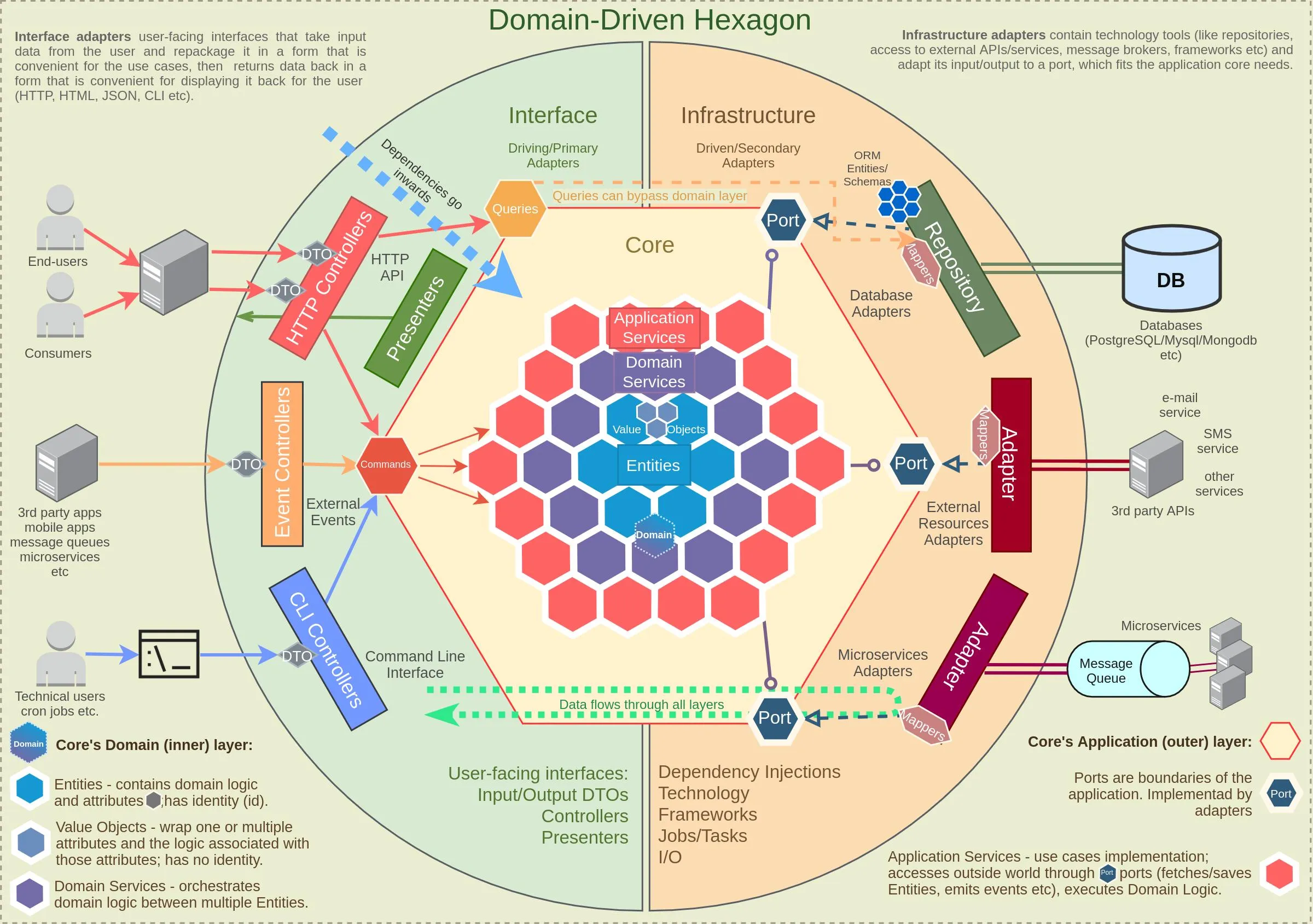
加载运行业务逻辑所需的所有内容 -> 告诉领域层运行所有业务逻辑 -> 提取业务逻辑的结果并告诉基础架构层将其持久化 ->
在这种意义上,应用层是否总是需要跟踪领域层计算出的任何结果,并因此始终实现某种UnitOfWork模式来跟踪这些结果?
领域层是否会使用存储库或存储库接口进行任何工作?有些来源似乎表明这是可以的,但从我的角度来看,这与图表完全矛盾。