我使用开发版本5.3(git checkout)制作了一个3D柱状图。这是我的splot命令:
splot for [c = 1:ncats] for [f = 1:nfiles] \
word(cat_files[c],f).'.stats' \
using (f+column(0)*(nfiles+2)):(scale_y(c)):2 \
with boxes \
title (c==1 ? columnhead(1) : '')
输入数据位于描述中的一组“
stats”文件中。为了绘制图形,我将输入
FILES分成了类别 - 两个(
ncats)文件集合存储在数组
cat_files中,每个集合包含相同数量的文件(
nfiles)。
这些类别等同于y轴上的位置(行),而各个文件则等同于x轴上的位置(条形)。每个文件中的行相当于条形的聚类,每行中的值是条形高度,即Z轴。在2D模型中,Z轴是Y轴。下面的丑陋表达式用于将条形定位在x轴和y轴上,如下所述。
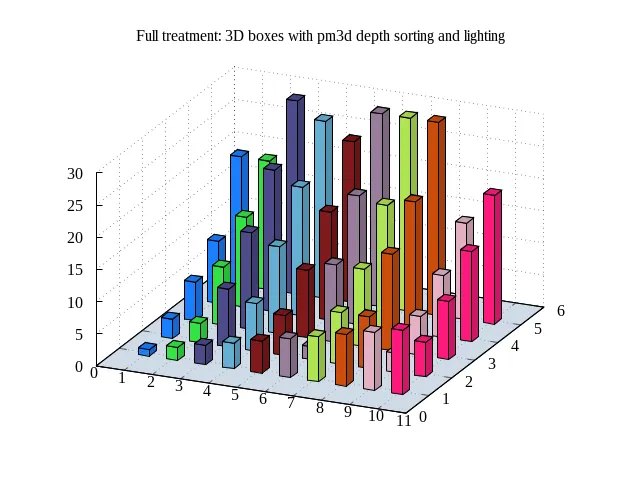
我在实现过程中遇到了很多困难,但我认为结果看起来不错:
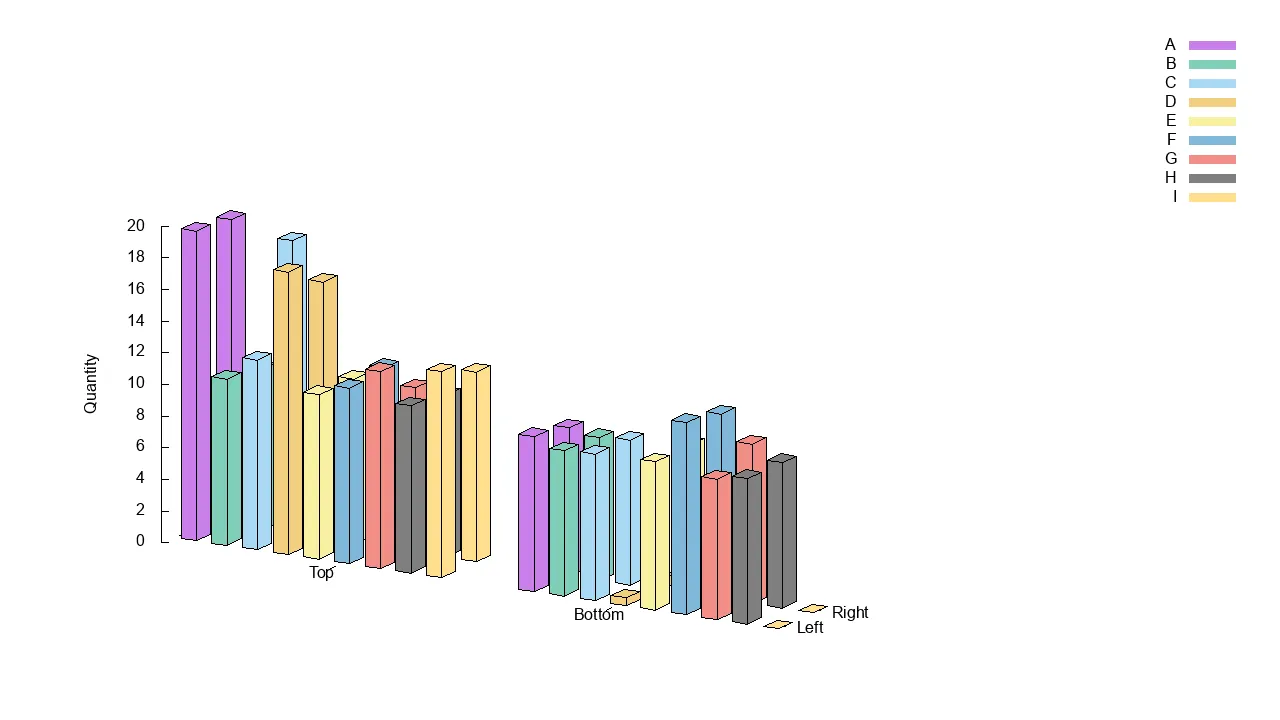
我下面要讨论的问题是:
- 匹配y轴图表“行”之间的颜色
- 条形图的尺寸——制作正方形条形图非常难以掌握,因此需要使用我的
scale_y函数。
- x轴标签方向
- 密钥中有重复项,因此需要使用条件表达式来设置
title。
- 没有聚类支持,因此需要使用不良的定位表达式
我所拥有的东西很脆弱——它在我的Linux系统上运行良好,但是严重依赖于shell帮助程序。 但它确实有效。 希望这些信息能帮助其他人或被视为反馈以改进gnuplot,使其更加出色!
颜色
为了使每个数据集中的颜色排列整齐,我使用了set linetype cycle nfiles,并希望gnuplot定义足够的颜色。
这样做的原因是在文件集(y轴上的类别)之间重置颜色分配,以便不同文件集中的相同条形图具有相同的颜色。 通过在已知文件数(图表条形图)之后明确设置为循环,我确保了颜色匹配。
条形图尺寸
条形图的尺寸(
boxwidth和
boxdepth)是相对于轴范围的,因此很难使它们成为正方形。
如果一根条形图停留在y轴的极端位置(下方或上方),则其垂直切成两半(可见的箱体深度是定义的
boxdepth值的一半)。
我不得不调整y轴的缩放比例,以便我的两个类别集显示在一起。默认行为显示从1到2的范围,步长为0.2,并将两个绘图放置在1和2处,使它们看起来相距甚远。
我尝试使用
set ytics但没有效果。最终我调整了y值的缩放比例。
scale(y) = 0.1 * y - 0.05
set yrange [0:1]
set boxdepth (0.8 / clusters)
所有数字都是虚拟因素。
clusters 是聚类的数量(文件中的行数)。我拥有的数字可以与我的测试数据保持正方形外观(我有数据需要显示最多5个聚类)。
我不得不从0.5开始x轴,否则第一条柱将出现太远(如果x从0开始)或垂直被切掉一半(如果x从1开始)。
set xrange [0.5:*]
轴标签
我用自定义标签替换了自动刻度线。在Y轴上:
set ytics ()
set for [c = 1:ncats] ytics add (word(CATS,c) scale_y(c) )
同样地,对于x轴。首先,在只有1个聚类的情况下,我标记每个类别。
set xtics ()
set for [f = 1:nfiles] xtics add (label(word(cat_files[1],f)) f)
如果存在多个集群,我会对这些集群进行标记:
set xtics ()
set set for [c = 2:(clusters+1)] xtics add (cell(f,c,1) (nfiles/2)+2+((c-2)*nfiles))
这里,
cell 是一个 shell 帮助程序,它返回文件
f 中第
c 行位置 1 的值。可怕的公式是一种 hack,用于将标签定位在聚类的中心沿轴线上。我还使用 shell 帮助程序获取聚类数。我无法找到在 gnuplot 中查询行和列的方法。请注意,以前(当进行 2D 绘图时),我会使用
xticlabels(1) 来绘制聚类的 x 轴。
我想将 x 标签转为与轴垂直运行,但似乎不可能。我还想通过“右”对齐来微调它们的位置,但也无法实现。
关键标签
每个绘制的条形图都会向键中添加一个条目。因为这些在每个类别中重复出现,所以它们会在键中重复。我通过使用条件语句使其仅添加一次,从而进行了更改。
title columnhead(1)
到
title (c==1 ? columnhead(1) : '')
当存在多个聚类时,我才会显示密钥。
聚类
2D图被聚类了。我在制作3D聚类外观时遇到了困难。如果我在聚类数据上运行图形,则它们会重叠(它们具有相同的Y值)。为了克服这个问题,我使用了一个公式来沿着x轴移动后面的聚类,并在它们之间添加间隙。因此,x不再是一个简单的值:
... using (f):(scale_y(c)):2 ...
我有一个公式:
... using (f+column(0)*(nfiles+2)):(scale_y(c)):2 ...
其中f是文件编号(例如,条形码编号),column(0)是群集编号,nfiles是文件数量(即条形码数量或群集大小),2是分隔符间隔。
顺便提一下,在执行此操作时,我发现在gnuplot 5.3中($0)无法使用,必须使用column(0)代替(在5.2.4中可以使用$0)。
我使用Arch Linux AUR软件包构建了一个软件包gnuplot-git-5.3r20180810.10527-1-x86_64.pkg.tar.xz。
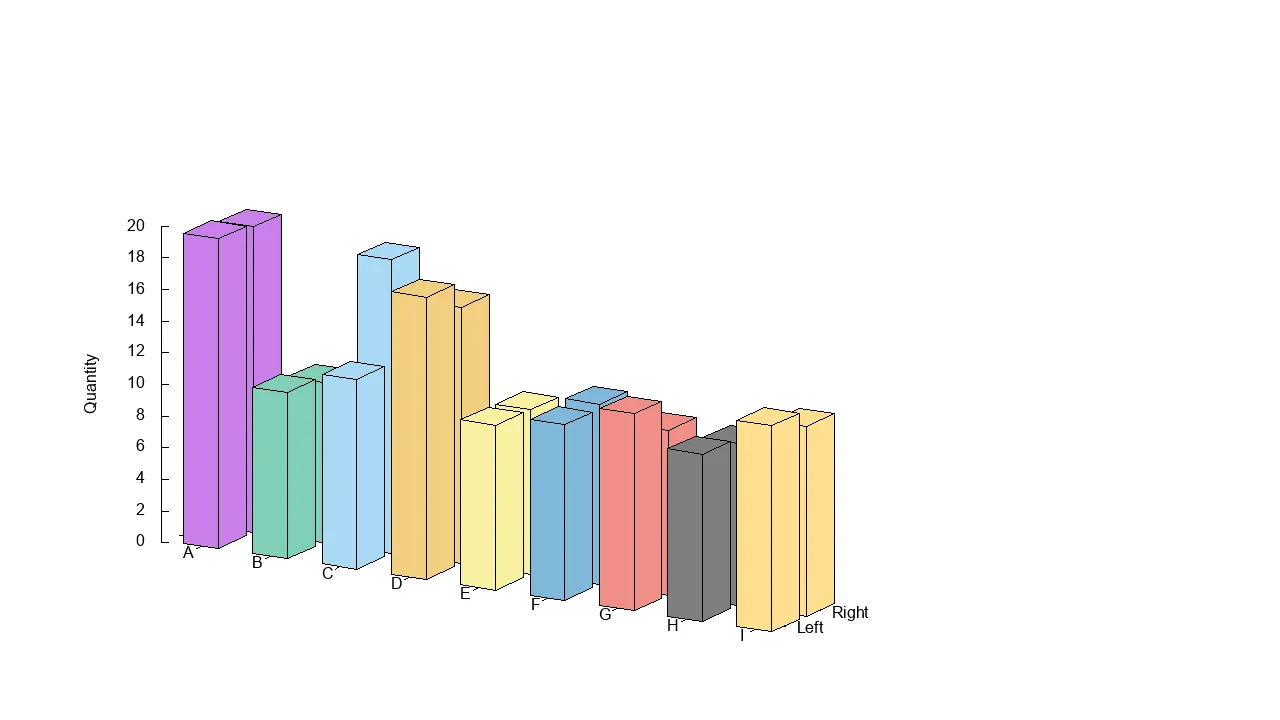
一个只有一个簇的示例图。
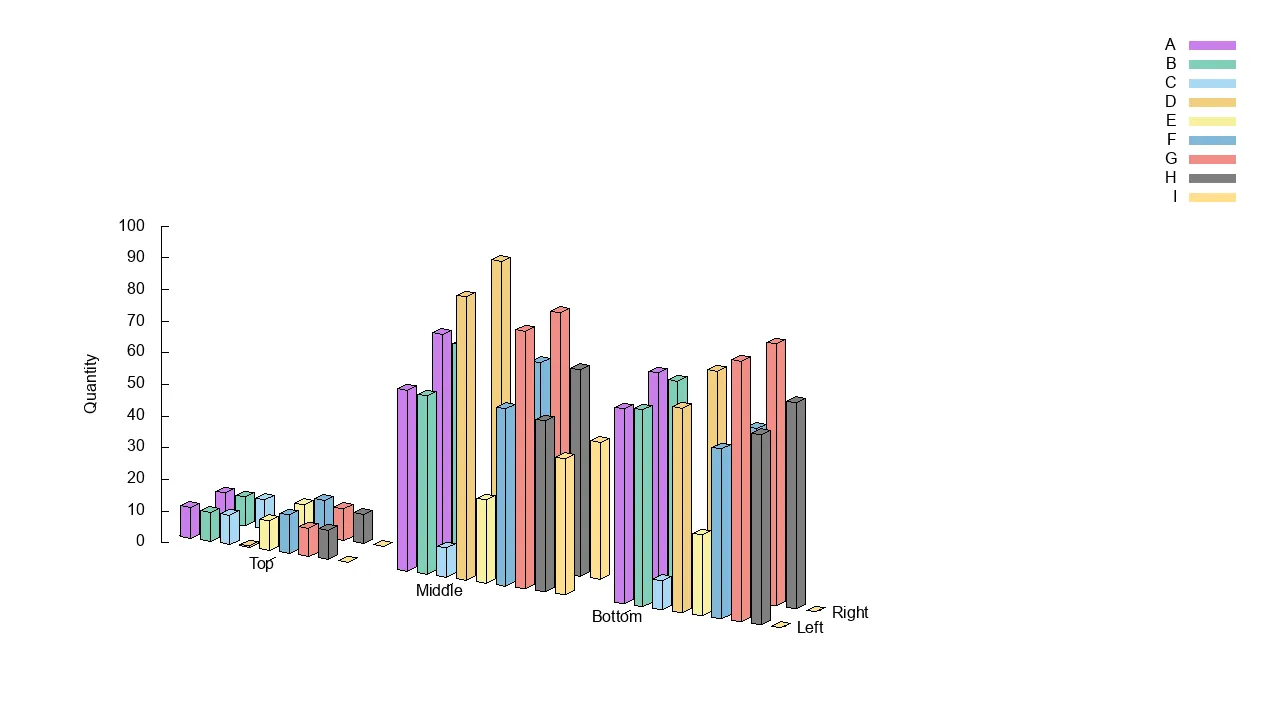
一个带有三个聚类和关键图例的示例绘图。
这里可能有更好的方法来完成我所做的事情。作为一个相对新手的gnuplot用户,我很乐意听取任何改进此解决方案的建议。
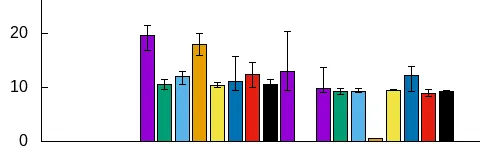
splot for [f=1:N] "file".f.".stats" using 2:(f):3 with boxes title columnhead(1)的内容。您原来的x仍然是x;您原来的y现在是z,文件的索引现在是y。 - Ethan