[前言]
本问答旨在更清楚地解释我首次发布于此处的近似搜索类的内部工作方式。
由于各种原因,我已被多次要求提供有关此内容的更详细信息,因此我决定编写问答风格的主题,在将来可以轻松引用它,而不需要一遍又一遍地解释。
[问题]
如何在实数域(double)中近似值/参数以实现拟合多项式、参数化函数或解决(困难的)方程(如超越方程)?
限制条件
- 实数域(
double精度) - C++语言
- 可配置的近似精度
- 已知搜索区间
- 拟合的值/参数不是严格单调或根本不是函数
[前言]
本问答旨在更清楚地解释我首次发布于此处的近似搜索类的内部工作方式。
由于各种原因,我已被多次要求提供有关此内容的更详细信息,因此我决定编写问答风格的主题,在将来可以轻松引用它,而不需要一遍又一遍地解释。
[问题]
如何在实数域(double)中近似值/参数以实现拟合多项式、参数化函数或解决(困难的)方程(如超越方程)?
限制条件
double精度)近似搜索
这类似于二分搜索,但没有其限制,即被搜索的函数/值/参数必须是严格单调函数,同时共享 O(log(n)) 复杂度。
例如,假设有以下问题
我们已知函数 y=f(x) 并想要找到 x0 ,使得 y0=f(x0)。基本上可以通过 f 的反函数来完成,但是有许多函数我们不知道如何计算其反函数。那么在这种情况下如何计算?
已知
y=f(x) - 输入函数y0 - 想要的点 y 值a0,a1 - 解决方案 x 区间范围未知
x0 - 想要的点 x 值必须在范围 x0=<a0,a1> 中算法
probe some points x(i)=<a0,a1> evenly dispersed along the range with some step da
So for example x(i)=a0+i*da where i={ 0,1,2,3... }
for each x(i) compute the distance/error ee of the y=f(x(i))
This can be computed for example like this: ee=fabs(f(x(i))-y0) but any other metrics can be used too.
remember point aa=x(i) with minimal distance/error ee
stop when x(i)>a1
recursively increase accuracy
so first restrict the range to search only around found solution for example:
a0'=aa-da;
a1'=aa+da;
then increase precision of search by lowering search step:
da'=0.1*da;
if da' is not too small or if max recursions count is not reached then go to #1
found solution is in aa
这是我心中所想:
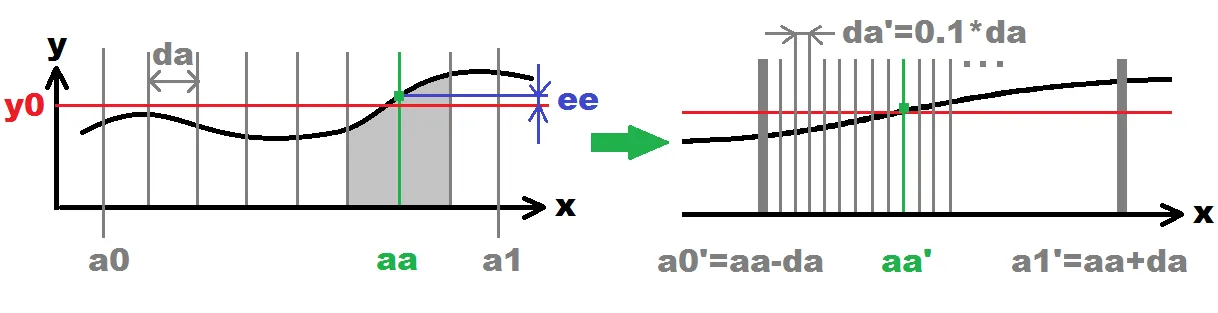
10倍(0.1*da)。灰色垂直线代表探测的x(i)点。
以下是此代码的C++源代码:
//---------------------------------------------------------------------------
//--- approx ver: 1.01 ------------------------------------------------------
//---------------------------------------------------------------------------
#ifndef _approx_h
#define _approx_h
#include <math.h>
//---------------------------------------------------------------------------
class approx
{
public:
double a,aa,a0,a1,da,*e,e0;
int i,n;
bool done,stop;
approx() { a=0.0; aa=0.0; a0=0.0; a1=1.0; da=0.1; e=NULL; e0=NULL; i=0; n=5; done=true; }
approx(approx& a) { *this=a; }
~approx() {}
approx* operator = (const approx *a) { *this=*a; return this; }
//approx* operator = (const approx &a) { ...copy... return this; }
void init(double _a0,double _a1,double _da,int _n,double *_e)
{
if (_a0<=_a1) { a0=_a0; a1=_a1; }
else { a0=_a1; a1=_a0; }
da=fabs(_da);
n =_n ;
e =_e ;
e0=-1.0;
i=0; a=a0; aa=a0;
done=false; stop=false;
}
void step()
{
if ((e0<0.0)||(e0>*e)) { e0=*e; aa=a; } // better solution
if (stop) // increase accuracy
{
i++; if (i>=n) { done=true; a=aa; return; } // final solution
a0=aa-fabs(da);
a1=aa+fabs(da);
a=a0; da*=0.1;
a0+=da; a1-=da;
stop=false;
}
else{
a+=da; if (a>a1) { a=a1; stop=true; } // next point
}
}
};
//---------------------------------------------------------------------------
#endif
//---------------------------------------------------------------------------
这是使用它的方法:
approx aa;
double ee,x,y,x0,y0=here_your_known_value;
// a0, a1, da,n, ee
for (aa.init(0.0,10.0,0.1,6,&ee); !aa.done; aa.step())
{
x = aa.a; // this is x(i)
y = f(x) // here compute the y value for whatever you want to fit
ee = fabs(y-y0); // compute error of solution for the approximation search
}
aa.init(... 中的操作数被命名。a0,a1 是对 x(i) 进行探测的区间,da 是 x(i) 和 n 之间的初始步长,n = 6 并且 da = 0.1 时,x 拟合的最终最大误差将为~ 0.1 / 10 ^ 6 = 0.0000001。 &ee 是指向变量的指针,该变量存储实际误差。我选择了指针,因此当嵌套函数时没有冲突,并且速度更快,因为将参数传递给经常使用的函数会创建堆垃圾。
[注]
这种近似搜索可以嵌套到任何维度(但是需要注意速度),请参见一些示例。
如果需要获取“所有”解决方案并进行非函数拟合,您可以使用递归子搜索间隔来检查另一个解决方案。请参见示例:
你需要注意什么?
你必须仔细选择搜索区间<a0,a1>,使其包含解决方案,但不要太宽(否则速度会很慢)。此外,初始步骤da非常重要,如果太大,则可能会错过局部极小/极大值解决方案,如果太小,则速度会变得太慢(特别是对于嵌套的多维拟合)。
将割线方法(与括号法结合使用,但请参见底部的更正)和二分法相结合会更好(当然,原始图形归功于上面回答中的用户Spektre):
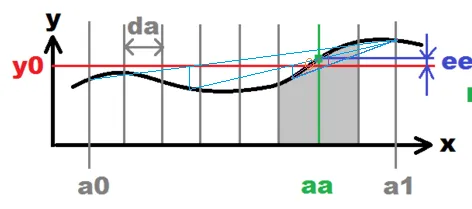

Given a function f,
Given two points a, b, such that a < b and sign(f(a)) /= sign(f(b)),
Given tolerance tol,
TO FIND root z of f such that abs(f(z)) < tol -- stop_condition
DO:
x = root of f by linear interpolation of f between a and b
m = midpoint between a and b
if stop_condition holds at x or m, set z and STOP
[a,b] := [a,x,m,b].sort.choose_shortest_interval_with_
_opposite_signs_at_its_ends
[a,b]减半,或者在每次迭代中做得更好;因此,除非函数的行为非常糟糕(比如说,在x=0附近的sin(1/x)),否则这将非常快速地收敛,每个迭代步骤最多只需要两次f的评估。
我们可以通过检查b-a是否变得太小(特别是如果我们使用有限精度,如双精度)来检测不良行为的情况。
更新: 显然,这实际上是双假位法,它是由上面的伪代码描述的带定界的割线法。像二分法一样增加中点可以确保在最病态的情况下也能收敛。
f(x +- delta) 来确定根的范围;对于二维问题,我们需要四个点 f(x +- delta, y +- delta);对于三维问题,我们需要八个点 f(x +- delta, y +- delta, z +- delta),以此类推。然后我们计算 f(x,y) 并选择误差符号相反的子区间,以确保真正的根在其中。这可以通过添加类似于梯度下降的割线法来改进。显然,这实际上是双假位法,而不是割线法。我已经更新了答案。 - Will Nessf(a) / 2。谢谢你告诉我。 :) - Will Ness