这里还有另一种可能性,但是过于简化了,因为它没有考虑到一个群体在一个它没有赢得的群体中拥有更高的人口的可能性。
library(dplyr)
df<- structure(list(Group = c(1L, 1L, 1L, 2L, 2L, 2L, 3L, 3L, 3L), country = c("A", "B", "C", "A", "E", "F", "A", "E", "G"), pop = c(200L, 100L, 50L, 200L, 150L, 120L, 200L, 150L,
100L)), class = "data.frame", row.names = c(NA, -9L))
df %>%
group_by(country) %>%
summarize(popmax = max(pop)) %>%
inner_join(df, by = c("popmax" = 'pop')) %>%
rename(country = country.y) %>%
select(-country.x) %>%
group_by(country) %>%
arrange(Group) %>%
slice(1) %>%
ungroup() %>%
group_by(Group) %>%
arrange(country) %>%
slice(1) %>%
select(Group, country, popmax) %>%
rename(pop = popmax)
我的答案在这个数据集上失败了(而其他答案没有):
df <- tribble(
~Group, ~ country, ~pop,
1 , 'A', 200,
1 , 'B', 100,
1 , 'C', 50,
1 , 'G', 150,
2 , 'A', 200,
2 , 'E', 150,
2 , 'F', 120,
3 , 'A', 200,
3 , 'E', 150,
3 , 'G', 100
)
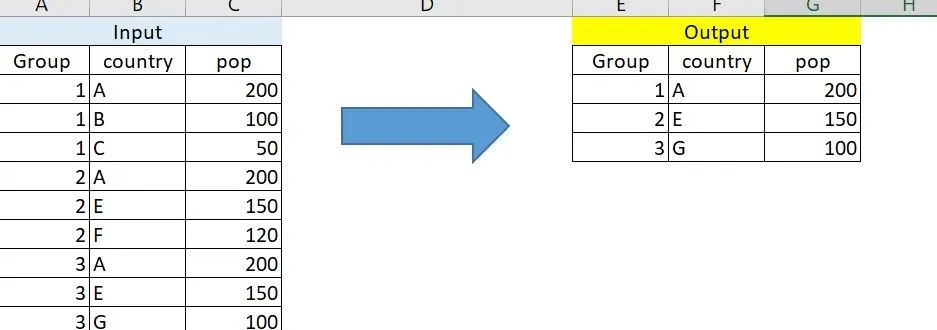 这有点棘手,我会尽力解释,如下所述。 我有以下数据框。 我需要根据国家列中的最大pop过滤行组,但是该组尚未出现在上述组中。(根据输出(图像),之所以A没有出现在第二组中,是因为它已经出现在第一组中)
这有点棘手,我会尽力解释,如下所述。 我有以下数据框。 我需要根据国家列中的最大pop过滤行组,但是该组尚未出现在上述组中。(根据输出(图像),之所以A没有出现在第二组中,是因为它已经出现在第一组中)