我有一个工作项目。我们编写了一个模块,并有一个#TODO来实现线程以改进该模块。我是一个相对新的Python程序员,决定尝试一下。在学习和实现线程时,我有一个类似于太多线程会有多少个?的问题,因为我们有一个大约有6个对象需要处理的队列,所以为什么要创建6个线程(或者根本不创建任何线程)来处理列表或队列中的对象,当处理时间无关紧要时呢? (每个对象最多需要大约2秒钟的处理时间)
所以我进行了一个小实验。我想知道使用线程是否会有性能提升。请参见我的Python代码:
所以我进行了一个小实验。我想知道使用线程是否会有性能提升。请参见我的Python代码:
import threading
import queue
import math
import time
results_total = []
results_calculation = []
results_threads = []
class MyThread(threading.Thread):
def __init__(self, thread_id, q):
threading.Thread.__init__(self)
self.threadID = thread_id
self.q = q
def run(self):
# print("Starting " + self.name)
process_data(self.q)
# print("Exiting " + self.name)
def process_data(q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
potentially_prime = True
data = q.get()
queueLock.release()
# check if the data is a prime number
# print("Testing {0} for primality.".format(data))
for i in range(2, int(math.sqrt(data)+1)):
if data % i == 0:
potentially_prime = False
break
if potentially_prime is True:
prime_numbers.append(data)
else:
queueLock.release()
for j in [1, 2, 3, 4, 5, 10, 15, 20, 25, 30, 40, 50, 75, 100, 150, 250, 500,
750, 1000, 2500, 5000, 10000]:
threads = []
numberList = list(range(1, 10001))
queueLock = threading.Lock()
workQueue = queue.Queue()
numberThreads = j
prime_numbers = list()
exitFlag = 0
start_time_total = time.time()
# Create new threads
for threadID in range(0, numberThreads):
thread = MyThread(threadID, workQueue)
thread.start()
threads.append(thread)
# Fill the queue
queueLock.acquire()
# print("Filling the queue...")
for number in numberList:
workQueue.put(number)
queueLock.release()
# print("Queue filled...")
start_time_calculation = time.time()
# Wait for queue to empty
while not workQueue.empty():
pass
# Notify threads it's time to exit
exitFlag = 1
# Wait for all threads to complete
for t in threads:
t.join()
# print("Exiting Main Thread")
# print(prime_numbers)
end_time = time.time()
results_total.append(
"The test took {0} seconds for {1} threads.".format(
end_time - start_time_total, j)
)
results_calculation.append(
"The calculation took {0} seconds for {1} threads.".format(
end_time - start_time_calculation, j)
)
results_threads.append(
"The thread setup time took {0} seconds for {1} threads.".format(
start_time_calculation - start_time_total, j)
)
for result in results_total:
print(result)
for result in results_calculation:
print(result)
for result in results_threads:
print(result)
这个测试找出了1到10000之间的质数。这个设置基本上是从https://www.tutorialspoint.com/python3/python_multithreading.htm中直接采用的,但我要求线程查找质数而不是打印简单的字符串。这实际上并不是我的真实应用程序,但我目前无法测试我为该模块编写的代码。我认为这是一个衡量额外线程效果的好测试。我的真实世界应用程序涉及与多个串行设备通信。我运行了5次测试并平均了时间。以下是图表结果:
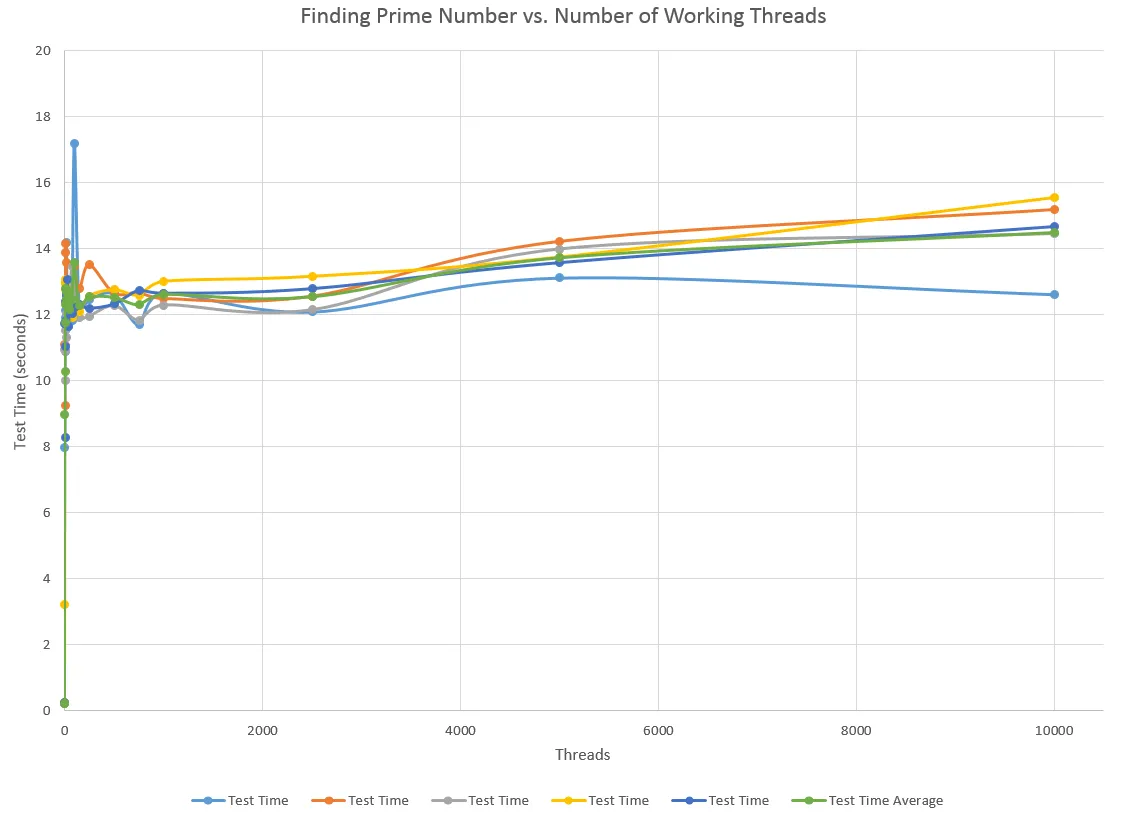
关于线程和这个测试,我的问题如下:
这个测试是否是线程使用的好代表?这不是服务器/客户端情况。在效率方面,当你没有为客户服务或处理添加到队列中的任务/工作时,避免并行处理是否更好?
如果问题1的答案是“不,这个测试不是使用线程的场所。”那么什么时候可以使用线程?一般来说。
如果问题1的答案是“是的,在这种情况下使用线程是可以的。”为什么添加线程最终需要更长的时间并迅速达到平台期?而且,为什么要使用线程,因为它比在循环中计算要花费多倍的时间。
我注意到当工作与线程的比例越接近1:1时,设置线程所需的时间越长。因此,线程仅在您创建线程一次并尽可能长时间保持它们活动以处理可能比它们可以计算的请求更快的请求时才有用吗?