首先,我正在解析一个文本文件,该文件以UTF-8编码保存在notepad中。这样做足以确保它是UTF-8吗?我尝试了chardet模块,但它并没有真正帮助我。如果有人能找出更多信息,以下是一些文本文件的几行:
CUSTOMERLOC|1|N/A|N/A|LEGACY COPPER|N/A|Existing|N/A|NRZ|NRZ|N/A|N/A
FTSMAR08|01/A|N/A|N/A|LEGACY COPPER|N/A|Existing|N/A|NRZ|NRZ|N/A|N/A
FTSMAR08|01/B|N/A|N/A|LEGACY COPPER|N/A|Existing|N/A|NRZ|NRZ|N/A|N/A
我使用lxml模块编写了XML,并使用tostring()方法将其分配给名为data的变量。
然后,我使用binascii模块的a2b_qp()函数将XML字符串转换为二进制,并将所有内容放入bytearray中。
data = bytearray(binascii.a2b_qp(ET.tostring(root, pretty_print=True)), "UTF-8")
在我看来,这个data变量应该包含我的XML二进制形式,它存储在一个bytearray里。
之后,我使用了一个更新游标,并将数据插入到表格的BLOB字段中。
row[2] = data
cursor.updateRow(row)
一切似乎都正常,但是当我使用以下代码读取BLOB字段时:
with arcpy.da.SearchCursor("Point", ['BlobField']) as cursor:
for row in cursor:
binaryRep = row[0]
open("C:/Blob.xml, 'wb').write(binaryRep.tobytes())
当我打开
Blob.xml 文件时,我期望看到我最初创建的 XML 字符串以可读的形式呈现,但是我得到了这个混乱的结果,使用 UTF-8 编码设置 Notepad++:

而使用 ANSI 编码设置 Notepad++ 则出现以下混乱:
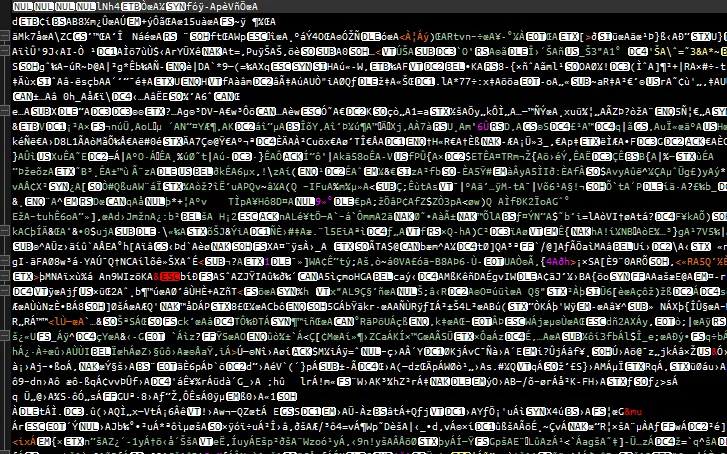
我认为有经验的人可能通过查看图片知道发生了什么。我已经阅读了很多并尝试解决问题,但是我一直被卡住了。