我需要从一个大文件(1500000行)中多次循环获取一条特定的数据,并且这个操作会在多个文件中进行。我在思考什么是最好的选项(以性能为考量)。有许多方法可以实现这个目标,但我主要使用以下两种方式:
cat ${file} | head -1
cat ${file} | sed -n '1p'
我找不到答案,它们两个是否都只获取第一行,还是其中的一个(或两者)会先打开整个文件,然后再获取第一行?
我需要从一个大文件(1500000行)中多次循环获取一条特定的数据,并且这个操作会在多个文件中进行。我在思考什么是最好的选项(以性能为考量)。有许多方法可以实现这个目标,但我主要使用以下两种方式:
cat ${file} | head -1
cat ${file} | sed -n '1p'
我找不到答案,它们两个是否都只获取第一行,还是其中的一个(或两者)会先打开整个文件,然后再获取第一行?
cat命令,改为使用以下方式:$ sed -n '1{p;q}' file
打印完这一行后,sed 脚本将会退出。
基准测试脚本:
#!/bin/bash
TIMEFORMAT='%3R'
n=25
heading=('head -1 file' 'sed -n 1p file' "sed -n '1{p;q} file" 'read line < file && echo $line')
# files upto a hundred million lines (if your on slow machine decrease!!)
for (( j=1; j<=100,000,000;j=j*10 ))
do
echo "Lines in file: $j"
# create file containing j lines
seq 1 $j > file
# initial read of file
cat file > /dev/null
for comm in {0..3}
do
avg=0
echo
echo ${heading[$comm]}
for (( i=1; i<=$n; i++ ))
do
case $comm in
0)
t=$( { time head -1 file > /dev/null; } 2>&1);;
1)
t=$( { time sed -n 1p file > /dev/null; } 2>&1);;
2)
t=$( { time sed '1{p;q}' file > /dev/null; } 2>&1);;
3)
t=$( { time read line < file && echo $line > /dev/null; } 2>&1);;
esac
avg=$avg+$t
done
echo "scale=3;($avg)/$n" | bc
done
done
将其保存为benchmark.sh,然后运行bash benchmark.sh。
结果:
head -1 file
.001
sed -n 1p file
.048
sed -n '1{p;q} file
.002
read line < file && echo $line
0
**来自有1,000,000行的文件的结果。*
因此,sed -n 1p的时间会随着文件长度呈线性增长,但其他变体的时间是恒定的(并且可以忽略不计),因为它们在阅读第一行后立即退出:
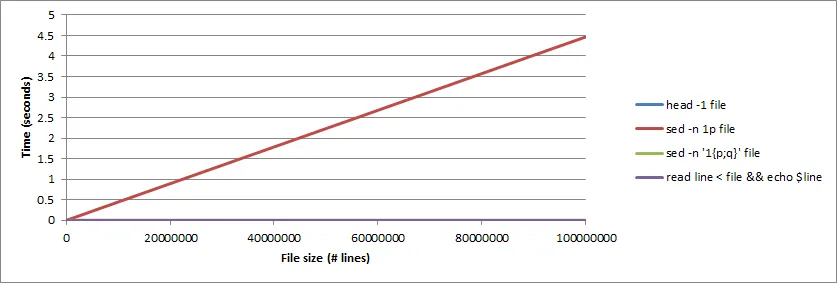
注意:由于位于较快的Linux系统上,时序与原始帖子中不同。
sed 1q file会更简单一些,输出结果也会更少。 - potongcase 和 heading 中的 sed 1q 行是不同的。 :) 特别是为了性能测试,让它们相同会很好。无论如何,回答得很好! - Kentj<=100,000,000 看起来是无效的 Bash 语法。 - Roel Van de Paarhead -20 filename | tail -1
我使用bash进行了一个“基本”的测试,似乎比上面提到的sed -n '1{p;q}解决方案表现更好。
测试使用一个大文件,在文件中选择某个位置(第10000000行),重复执行100次,每次选择下一行。因此它选择10000000,10000001,10000002, ... 这些行,直到10000099。
$wc -l english
36374448 english
$time for i in {0..99}; do j=$((i+10000000)); sed -n $j'{p;q}' english >/dev/null; done;
real 1m27.207s
user 1m20.712s
sys 0m6.284s
对比。
$time for i in {0..99}; do j=$((i+10000000)); head -$j english | tail -1 >/dev/null; done;
real 1m3.796s
user 0m59.356s
sys 0m32.376s
打印多个文件中的一行
$wc -l english*
36374448 english
17797377 english.1024MB
3461885 english.200MB
57633710 total
$time for i in english*; do sed -n '10000000{p;q}' $i >/dev/null; done;
real 0m2.059s
user 0m1.904s
sys 0m0.144s
$time for i in english*; do head -10000000 $i | tail -1 >/dev/null; done;
real 0m1.535s
user 0m1.420s
sys 0m0.788s
sed 调用在低行位置(如 i + 1000)时略快。请参见 @roel's answer 和我的评论:对于像 100k 这样的大行位置,我可以重现与您非常相似的结果,并确认 Roel 的结果,即对于较短的计数,仅使用 sed 更好。(对于我来说,在 i7-6700k 桌面 Skylake 上,head|tail 比您更好,在大 n 的情况下具有更大的相对加速比。可能是由于更好的内核间带宽,因此将所有数据传输的成本更低。) - Peter Cordessed '1{p;q}' uopgenl20121216.lis
real 0m0.917s
user 0m0.258s
sys 0m0.492s
阅读:read foo < uopgenl20121216.lis ; export foo; echo "$foo"
解释:该命令从文件“uopgenl20121216.lis”中读取内容到变量“foo”,然后导出该变量,并将其值输出。
real 0m0.017s
user 0m0.000s
sys 0m0.015s
这显然是刻意安排的,但它展示了内置性能与使用命令之间的差异。
read,结果确实是最快的(甚至除了偶尔的0.001毫秒之外都没有注册)。 - Chris Seymoursed和head都支持文件名作为参数。这样,您就可以避免通过cat传递。我没有测量过,但是在处理大文件时,head应该更快,因为它在N行后停止计算(而sed会通过所有行,即使不打印它们 - 除非您像上面建议的那样指定quit选项)。sed -n '1{p;q}' /path/to/file
head -n 1 /path/to/file
再次强调,我没有测试效率。
我进行了广泛的测试,并发现,如果你想要文件中的每一行:
while IFS=$'\n' read LINE; do
echo "$LINE"
done < your_input.txt
相比其他基于Bash的方法,它要快得多。所有其他方法(如sed)每次都会读取文件,至少到匹配行为止。如果文件有4行,则会得到:1 -> 1,2 -> 1,2,3 -> 1,2,3,4= 10 次读取,而while循环只维护一个位置光标(基于IFS),因此总共只需要4次读取。
在大约15k行的文件上,差异是惊人的:使用基于sed的方法提取每个时间的特定行需要大约25-28秒,而使用基于while...read的方法只需大约0-1秒,只需一次读取整个文件。
上面的示例还展示了如何更好地将IFS设置为换行符(感谢下面评论中的Peter),这将希望解决在某些情况下在Bash中使用while... read ...时遇到的其他问题。
为了完整起见,您还可以使用基本的 Linux 命令cut:
cut -d $'\n' -f <linenumber> <filename>
time命令测量指令执行时间。 - chorobacat命令的输出通过管道传输给其他工具?它们本身也可以打开文件,且如果您担心效率问题,这些工具可能会做得更好。但是,确实应该通过管道“流式传输”文件的前几个块(然后注意到消费者已经停止关注)。 - Thilo