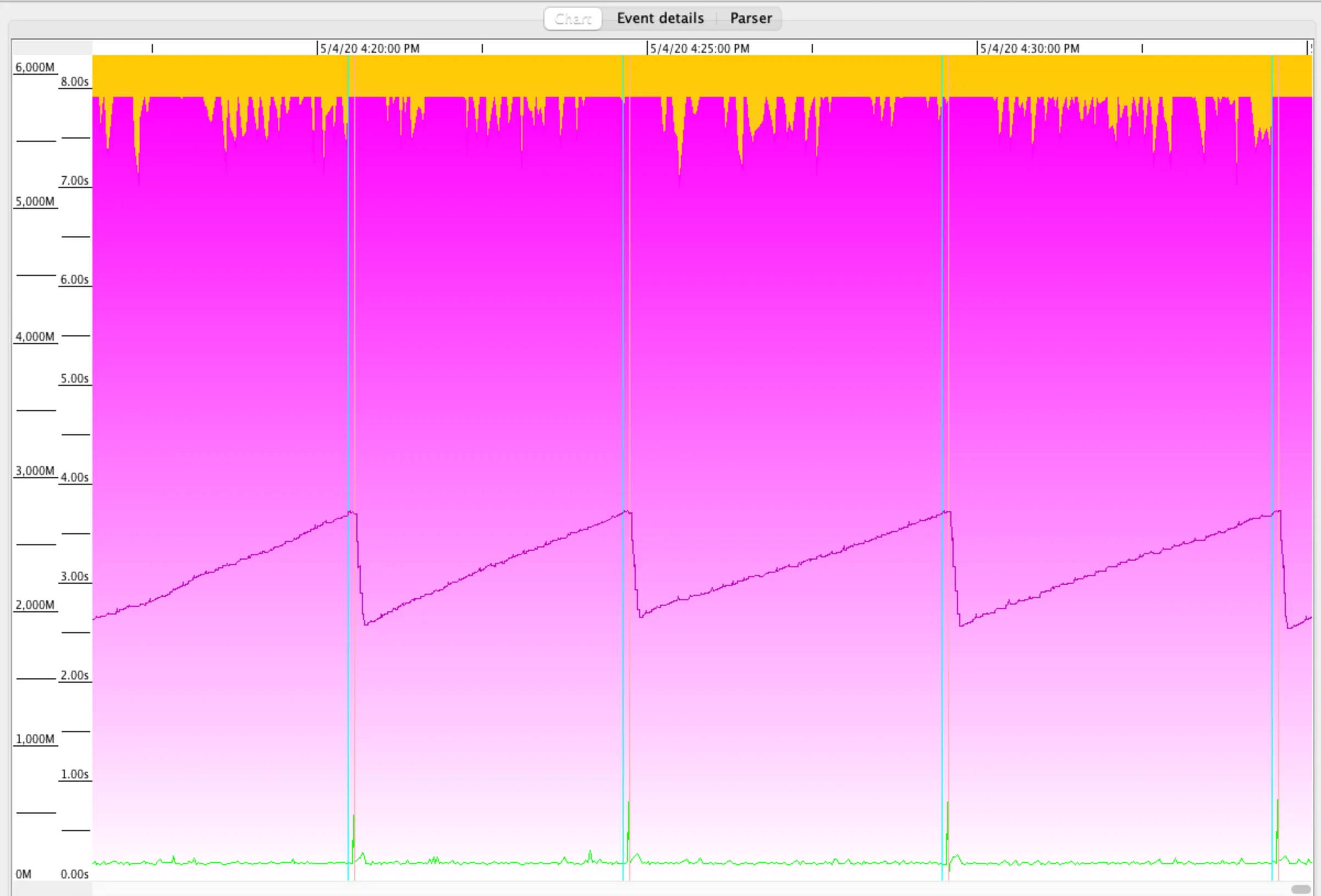
老年代已分配堆随着时间的推移而增加(在生产环境中大约为5至6天),但是老年代已使用堆并没有增加。伊甸园和幸存者堆被强制减少到最小值(总堆大小的5%),所以垃圾收集会变得越来越频繁。应用程序从一开始就缓存了一个大对象图,然后在其运行期间有其他时间/使用限制的缓存。它具有相当高的对象创建速率,但除了缓存的对象之外,很少将其提升到老年代。
我已经通过gceasy.io运行了GC日志,并且可以看到内存的上述行为: https://gceasy.io/my-gc-report.jsp?p=c2hhcmVkLzIwMjAvMDUvMTEvLS1nY2xvZy50YXIuZ3otLTExLTMwLTE5&channel=WEB.
我们使用基于CentOS的Openshift运行: CentOS Linux release 7.7.1908 (Core) 内核版本:3.10.0-1062.12.1.el7.x86_64
我已经通过gceasy.io运行了GC日志,并且可以看到内存的上述行为: https://gceasy.io/my-gc-report.jsp?p=c2hhcmVkLzIwMjAvMDUvMTEvLS1nY2xvZy50YXIuZ3otLTExLTMwLTE5&channel=WEB.
gclog: https://drive.google.com/open?id=176X-Lku4D3DGCCdTiB0_z545N8n0tfKc
本次运行的Grafana内存指标https://snapshot.raintank.io/dashboard/snapshot/k6g3ljG7cQUEJM7jA4c5tBK1dsUnzabd
运行结束时的堆转储(负载已经移除了大约一个小时,这是一个500M的gz文件):https://drive.google.com/open?id=14ghzIVnpelInSyQBhCwUwM5VkuOjX13-
我们似乎没有高数量的巨型对象创建。服务器有12G的RAM,堆有6G。
JVM:
openjdk version "1.8.0_242"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_242-b08)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.242-b08, mixed mode)
虚拟机标志:
-XX:CICompilerCount=4
-XX:ConcGCThreads=2
-XX:G1HeapRegionSize=2097152
-XX:GCLogFileSize=104857600
-XX:InitialHeapSize=6442450944
-XX:InitialRAMPercentage=50.000000
-XX:+ManagementServer
-XX:MarkStackSize=4194304
-XX:MaxHeapSize=6442450944
-XX:MaxNewSize=3865051136
-XX:MaxRAMPercentage=50.000000
-XX:MinHeapDeltaBytes=2097152
-XX:MinRAMPercentage=50.000000
-XX:NumberOfGCLogFiles=10
-XX:+PrintGC
-XX:+PrintGCDateStamps
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+UseCompressedClassPointers
-XX:+UseCompressedOops
-XX:+UseG1GC
-XX:+UseGCLogFileRotation
我们使用基于CentOS的Openshift运行: CentOS Linux release 7.7.1908 (Core) 内核版本:3.10.0-1062.12.1.el7.x86_64