除了一些最显著的解决方案的时间安排外,我没有为这个聚会做出太多贡献:
import bisect
def grade_bis(score, thresholds=(0.9, 0.8, 0.7, 0.6), grades="ABCDF"):
i = bisect.bisect(thresholds[::-1], score)
return grades[-i - 1]
def grade_gen(score, thresholds=(0.9, 0.8, 0.7, 0.6), grades="ABCDF"):
return next((
grade
for grade, threshold in zip(grades, thresholds)
if score >= threshold), grades[-1])
def grade_enu(score, thresholds=(0.9, 0.8, 0.7, 0.6), grades="ABCDF"):
for i, threshold in enumerate(thresholds):
if score >= threshold:
return grades[i]
return grades[-1]
def grade_alg(score, grades="ABCDF"):
return grades[-max(int(score * 10) - 5, 0) - 1]
使用一系列的if-elif-else语句(本质上是OP的方法,也不具有普适性):
def grade_iff(score):
if score >= 0.9:
return "A"
elif score >= 0.8:
return "B"
elif score >= 0.7:
return "C"
elif score >= 0.6:
return "D"
else:
return "F"
它们都会给出相同的结果:
import random
random.seed(2)
scores = [round(random.random(), 2) for _ in range(10)]
print(scores)
funcs = grade_bis, grade_gen, grade_enu, grade_alg
for func in funcs:
print(f"{func.__name__:>12}", list(map(func, scores)))
以下是计时情况(在重复
n=100000次的情况下,将结果存储到一个
列表中):
n = 100000
scores = [random.random() for _ in range(n)]
base = list(map(funcs[0], scores))
for func in funcs:
res = list(map(func, scores))
is_good = base == res
print(f"{func.__name__:>12} {is_good} ", end="")
%timeit -n 4 -r 4 list(map(func, scores))
表明OP的方法迄今为止是最快的,而在可以推广到任意阈值的方法中,基于bisect的方法在当前设置中是最快的。
随着阈值数量的增加
考虑到对于非常小的输入,线性搜索应该比二分搜索更快,因此有趣的是看到何时达到了平衡点,并确认二分搜索的应用呈现出次线性增长(对数级别)。
为了做到这一点,提供了一个作为阈值数量函数的基准测试(不包括那些:
import string
n = 1000
m = len(string.ascii_uppercase)
scores = [random.random() for _ in range(n)]
timings = {}
for i in range(2, m + 1):
breakpoints = [round(1 - x / i, 2) for x in range(1, i)]
grades = string.ascii_uppercase[:i]
print(grades)
timings[i] = []
base = [funcs[0](score, breakpoints, grades) for score in scores]
for func in funcs[:-2]:
res = [func(score, breakpoints, grades) for score in scores]
is_good = base == res
timed = %timeit -r 16 -n 16 -q -o [func(score, breakpoints, grades) for score in scores]
timing = timed.best * 1e3
timings[i].append(timing if is_good else None)
print(f"{func.__name__:>24} {is_good} {timing:10.3f} ms")
可以使用以下方法绘制:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame(data=timings, index=[func.__name__ for func in funcs[:-2]]).transpose()
df.plot(marker='o', xlabel='Input size / #', ylabel='Best timing / µs', figsize=(6, 4))
fig = plt.gcf()
fig.patch.set_facecolor('white')
生产:
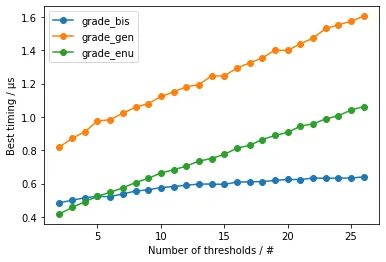
表明盈亏平衡点约为5,也证实了grade_gen()和grade_enu()的线性增长,以及grade_bis()的次线性增长。
基于NumPy的方法
能够使用NumPy处理的方法应该单独进行评估,因为它们接受不同的输入并能够以向量化的方式处理数组。