最近我注意到一个名为 SonarQube 规则 (https://rules.sonarsource.com/java/RSPEC-4784),该规则提醒我有些性能问题可能会被用作反对Java正则表达式实现的拒绝服务攻击。
事实上,以下Java测试展示了错误的正则表达式会有多么慢:
import org.junit.Test;
public class RegexTest {
@Test
public void fastRegex1() {
"aaaaaaaaaaaaaaaaaaaaaaaaaaaabs".matches("(a+)b");
}
@Test
public void fastRegex2() {
"aaaaaaaaaaaaaaaaaaaaaaaaaaaab".matches("(a+)+b");
}
@Test
public void slowRegex() {
"aaaaaaaaaaaaaaaaaaaaaaaaaaaabs".matches("(a+)+b");
}
}
正如您所看到的,前两个测试非常快,第三个测试在Java 8中非常慢。
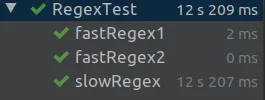
然而,在Perl或Python中使用相同的数据和正则表达式却并不慢,这让我想知道为什么在Java中评估这个正则表达式如此缓慢。
$ time perl -e '"aaaaaaaaaaaaaaaaaaaaaaaaaaaabs" =~ /(a+)+b/ && print "$1\n"'
aaaaaaaaaaaaaaaaaaaaaaaaaaaa
real 0m0.004s
user 0m0.000s
sys 0m0.004s
$ time python3 -c 'import re; m=re.search("(a+)+b","aaaaaaaaaaaaaaaaaaaaaaaaaaaabs"); print(m.group(0))'
aaaaaaaaaaaaaaaaaaaaaaaaaaaab
real 0m0.018s
user 0m0.015s
sys 0m0.004s
在数据中使用额外匹配修饰符+或尾字符s会导致这个正则表达式变得很慢,为什么只有Java受影响?
(a+)+b而不是a+b?如果你只想匹配而不是获取 b 前面的组,那么我不认为有任何理由使用组和组后的 +! - Youcef LAIDANI.matches("(a+)b")实际上等同于Perl的/^(a+)+b\z/。 - ikegami