我想要一个清晰的例子,展示任务如何被分配到多个线程中。
如何在Python中使用多线程?
1498
- albruno
7
37Jeff Knupp的博客文章Python's Hardest Problem 对这个主题进行了很好的概括讨论。总的来说,多线程编程并不适合初学者。 - Matthew Walker
129哈哈,我倾向于认为线程对所有人来说都是有用的,但是初学者不适合使用线程 :))))) - Bohdan
56提醒大家要阅读所有答案,因为后面的答案可能会更好,因为利用了新的语言特性... - Gwyn Evans
6记得用 C 编写你的核心逻辑,并通过 ctypes 调用它,以充分利用 Python 的线程。 - aaa90210
5我只是想补充一下,PyPubSub 是一个很好的发送和接收消息以控制线程流的方式。 - rassa45
显示剩余2条评论
24个回答
1624
自2010年提出这个问题以来,Python中使用 map 和 pool 进行简单多线程操作的方法已经得到了真正的简化。
下面的代码来自一篇文章/博客帖子,你一定应该查看(没有关联)-一行代码实现并行:日常线程任务的更好模型。我将在下面进行总结 - 最终只需要几行代码即可完成。
from multiprocessing.dummy import Pool as ThreadPool
pool = ThreadPool(4)
results = pool.map(my_function, my_array)
以下哪个是多线程版本:
results = []
for item in my_array:
results.append(my_function(item))
描述
Map是一个很棒的小函数,是轻松将并行性注入Python代码的关键。对于那些不熟悉的人来说,map是从类似Lisp的函数式语言中提取出来的东西。它是一个将另一个函数映射到序列上的函数。
Map为我们处理了序列的迭代、应用函数,并将所有结果存储在方便的列表中。
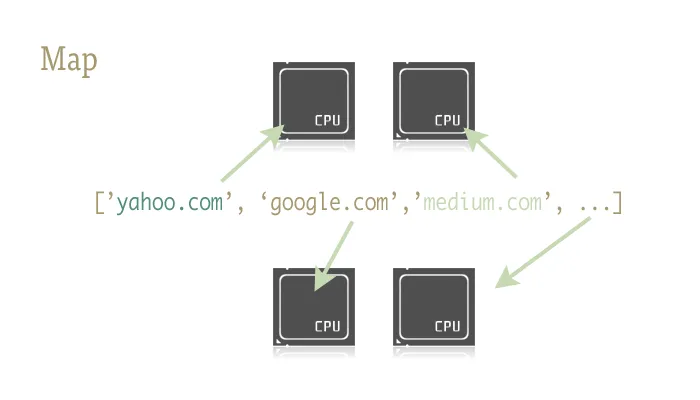
实现
两个库提供了map函数的并行版本:multiprocessing和它的鲜为人知的好伙伴multiprocessing.dummy。
multiprocessing.dummy与multiprocessing模块完全相同,但使用线程而不是进程 (一个重要的区别 - 对于CPU密集型任务使用多个进程;对于I/O(期间)使用线程):
multiprocessing.dummy复制了multiprocessing的API,但不过是线程模块的一个包装。
import urllib2
from multiprocessing.dummy import Pool as ThreadPool
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
]
# Make the Pool of workers
pool = ThreadPool(4)
# Open the URLs in their own threads
# and return the results
results = pool.map(urllib2.urlopen, urls)
# Close the pool and wait for the work to finish
pool.close()
pool.join()
并且这是定时结果:
Single thread: 14.4 seconds
4 Pool: 3.1 seconds
8 Pool: 1.4 seconds
13 Pool: 1.3 seconds
传递多个参数(仅适用于Python 3.3及更高版本,类似于这样操作):
要传递多个数组:
results = pool.starmap(function, zip(list_a, list_b))
或者传递一个常量和一个数组:
results = pool.starmap(function, zip(itertools.repeat(constant), list_a))
(感谢user136036提供的有用评论。)
- philshem
36
104这个答案只是因为发布时间比较短而缺乏投票。这个答案展示了“map”功能,使语法比其他答案更易于理解并且非常有效。 - idle
29这是线程而不是进程吗?它似乎试图进行多进程处理,而非多线程处理。 - AturSams
87顺便说一下,大家可以这样写:
with Pool(8) as p: p.map( *whatever* ),这样可以省去繁琐的代码。 - user29717112虽然这很有用,但值得注意的是,这仅适用于Python 3.3及以上版本。 - fuglede
14你怎么能留下这个答案而不提到它只对I/O操作有用呢?这只在单线程上运行,对于大多数情况来说是无用的,实际上比正常方法还要慢。 - Frobot
显示剩余31条评论
763
这里有一个简单的示例:您需要尝试几个备选的URL,并返回第一个响应的内容。
这是一个使用线程作为简单优化的案例:每个子线程等待URL解析和响应,将其内容放入队列中;每个线程都是守护进程(如果主线程结束,不会保持进程--这比不是更常见);主线程启动所有子线程,在队列上执行
在Python中正确使用线程通常与I/O操作相关(由于CPython无论如何都不使用多个核心来运行CPU绑定任务,因此线程的唯一原因是不阻塞进程,而在等待某些I/O时)。顺便说一句,队列几乎总是将工作分配给线程和/或收集工作结果的最佳方式,并且它们本质上是线程安全的,因此您不必担心锁,条件,事件,信号量和其他线程间协调/通信概念。
import Queue
import threading
import urllib2
# Called by each thread
def get_url(q, url):
q.put(urllib2.urlopen(url).read())
theurls = ["http://google.com", "http://yahoo.com"]
q = Queue.Queue()
for u in theurls:
t = threading.Thread(target=get_url, args = (q,u))
t.daemon = True
t.start()
s = q.get()
print s
这是一个使用线程作为简单优化的案例:每个子线程等待URL解析和响应,将其内容放入队列中;每个线程都是守护进程(如果主线程结束,不会保持进程--这比不是更常见);主线程启动所有子线程,在队列上执行
get等待直到其中一个执行了put,然后发出结果并终止(这将关闭可能仍在运行的任何子线程,因为它们是守护线程)。在Python中正确使用线程通常与I/O操作相关(由于CPython无论如何都不使用多个核心来运行CPU绑定任务,因此线程的唯一原因是不阻塞进程,而在等待某些I/O时)。顺便说一句,队列几乎总是将工作分配给线程和/或收集工作结果的最佳方式,并且它们本质上是线程安全的,因此您不必担心锁,条件,事件,信号量和其他线程间协调/通信概念。
- Alex Martelli
19
12谢谢你,MartelliBot。
我已经更新了示例以等待所有URL响应:import Queue, threading, urllib2q = Queue.Queue()urls = '''http://www.a.com
http://www.b.com
http://www.c.com'''.split()urls_received = 0 def get_url(q, url):
req = urllib2.Request(url)
resp = urllib2.urlopen(req)
q.put(resp.read())
global urls_received
urls_received +=1
print urls_received for u in urls:
t = threading.Thread(target=get_url, args = (q,u))
t.daemon = True
t.start()while q.empty() and urls_received < len(urls):
s = q.get()
print s - htmldrum
5如果您查看下面的答案,我认为更好的等待线程完成的方法是使用
join()方法,因为这将使主线程等待直到它们完成,而不会通过不断检查值来消耗处理器。谢谢,这恰好是我需要理解如何使用线程的东西。 - krs0139对于Python3,请将“import urllib2”替换为“import urllib.request as urllib2”,并在print语句中加上括号。 - Harvey
8针对 Python 3,将模块名
Queue 替换为 queue。方法名称不变。 - JSmyth2我注意到这个解决方案只会打印其中一页。要从队列中打印出两页,请再次运行命令:
s = q.get()
print s@krs013 因为Queue.get()是阻塞的,所以您不需要使用join。 - Tom Anderson显示剩余14条评论
292
注意:如果要在Python中实现真正的并行化,应使用multiprocessing 模块来分叉多个进程并行执行(由于全局解释器锁定,Python线程提供交错执行,但它们实际上是串行执行的,只有在交错I/O操作时才有用)。
然而,如果您仅仅需要交错执行(或者正在进行可以并行化的I/O操作,尽管存在全局解释器锁定),那么threading模块是开始的地方。作为一个非常简单的示例,让我们考虑通过并行求和子范围来求解大范围求和问题:
import threading
class SummingThread(threading.Thread):
def __init__(self,low,high):
super(SummingThread, self).__init__()
self.low=low
self.high=high
self.total=0
def run(self):
for i in range(self.low,self.high):
self.total+=i
thread1 = SummingThread(0,500000)
thread2 = SummingThread(500000,1000000)
thread1.start() # This actually causes the thread to run
thread2.start()
thread1.join() # This waits until the thread has completed
thread2.join()
# At this point, both threads have completed
result = thread1.total + thread2.total
print result
请注意,上述示例非常愚蠢,因为它根本不进行输入/输出操作,将在CPython中由于全局解释器锁的存在串行执行,尽管会交错执行(带有上下文切换的额外开销)。
- Michael Aaron Safyan
10
17@Alex,我并不是说这种方法是实用的,但它确实演示了如何定义和启动线程,我认为这正是 OP 想要的。 - Michael Aaron Safyan
8虽然这段代码展示了如何定义和启动线程,但它实际上并没有并行地求和子区间。
thread1运行直到完成,同时主线程被阻塞,然后thread2也是同样的过程,接着主线程恢复并打印出它们累加的值。 - martineau那不应该是
super(SummingThread, self).__init__() 吗?就像这个链接中的 https://dev59.com/YHI95IYBdhLWcg3wsQFm#2197625 所示。 - James Andres@JamesAndres,假设没有人继承“SummingThread”,那么两种方法都可以;在这种情况下,super(SummingThread,self)只是一种查找方法解析顺序(MRO)中的下一个类(即threading.Thread),然后在两种情况下都调用__init__的花哨方式。你是对的,使用super()对于当前Python来说更好的风格。在我提供这个答案时,Super相对较新,因此直接调用超类而不是使用super()。我会更新这个问题来使用super。 - Michael Aaron Safyan
18警告:在这样的任务中不要使用多线程!正如Dave Beazley所示:http://www.dabeaz.com/python/NewGIL.pdf,2个Python线程在2个CPU上执行一个CPU密集型任务的速度比1个CPU上的1个线程慢2倍,并且比1个CPU上的2个线程慢1.5倍。这种奇怪的行为是由于操作系统和Python之间的协调不当造成的。线程的真实用例是I/O密集型任务。例如,当您在网络上执行读取/写入时,将等待数据读取/写入的线程置于后台并将CPU切换到另一个需要处理数据的线程是有意义的。 - Boris Burkov
显示剩余5条评论
117
正如其他人所提到的,由于全局解释器锁(GIL),CPython只能在I/O等待时使用线程。
如果您想从多个核心中受益以完成CPU密集型任务,请使用multiprocessing:
from multiprocessing import Process
def f(name):
print 'hello', name
if __name__ == '__main__':
p = Process(target=f, args=('bob',))
p.start()
p.join()
- Kai
7
37你能稍微解释一下这个是做什么的吗? - pandita
7这段代码创建了一个进程,然后启动它。现在有两件事情同时发生:程序的主线和以目标函数
f 启动的进程。同时,主程序现在只等待进程退出,并与之 join 起来。如果主程序刚刚退出,子进程可能会完成,也可能不会完成,因此总是建议使用 join。 - johntellsall1这里有一个包含
map函数的扩展答案:https://dev59.com/BXE85IYBdhLWcg3wSxkv#28463266 - philshem5请注意,您发布的链接正在使用线程池(而非进程),如此处所述https://dev59.com/0l8d5IYBdhLWcg3wzEv4。但是,此答案正在使用进程。我对这方面的知识不多,但似乎由于GIL,在Python中使用多线程只有在特定情况下才能获得性能提升。然而,使用进程池可以利用多核处理器,通过让多个核心同时处理一个进程来提高性能。 - user3731622
3这是最佳答案,可以实际做些有用的事情并利用多个CPU核心。 - Frobot
显示剩余2条评论
102
请注意:线程不需要队列。
以下是我可以想象到的最简单的示例,展示了10个进程同时运行。
import threading
from random import randint
from time import sleep
def print_number(number):
# Sleeps a random 1 to 10 seconds
rand_int_var = randint(1, 10)
sleep(rand_int_var)
print "Thread " + str(number) + " slept for " + str(rand_int_var) + " seconds"
thread_list = []
for i in range(1, 10):
# Instantiates the thread
# (i) does not make a sequence, so (i,)
t = threading.Thread(target=print_number, args=(i,))
# Sticks the thread in a list so that it remains accessible
thread_list.append(t)
# Starts threads
for thread in thread_list:
thread.start()
# This blocks the calling thread until the thread whose join() method is called is terminated.
# From http://docs.python.org/2/library/threading.html#thread-objects
for thread in thread_list:
thread.join()
# Demonstrates that the main process waited for threads to complete
print "Done"
- Douglas Adams
7
4将最后一个引用添加到“完成”以使其打印“完成”。 - iChux
3我比Martelli的例子更喜欢这个,用起来更容易。不过,我建议printNumber应该做以下修改,以使正在发生的事情更清晰一些:在沉睡之前将randint保存到一个变量中,然后将打印内容更改为"Thread" + str(number) + "睡了" + theRandintVariable + "秒"。 - Nickolai
2有没有一种方法可以知道每个线程何时完成,以及它何时完成? - Matt
2@Matt 有几种方法可以做到这样的事情,但它将取决于你的需求。一种方法是更新单例或其他公共可访问变量,在 while 循环中被监视并在线程结束时进行更新。 - Douglas Adams
3无需第二个
for循环,你可以在第一个循环中调用thread.start()。 - Mark Mishyn显示剩余2条评论
52
Alex Martelli的回答对我很有帮助。不过,这里有一个我认为更有用的修改版(至少对我是这样)。
更新:适用于Python 2和Python 3。
try:
# For Python 3
import queue
from urllib.request import urlopen
except:
# For Python 2
import Queue as queue
from urllib2 import urlopen
import threading
worker_data = ['http://google.com', 'http://yahoo.com', 'http://bing.com']
# Load up a queue with your data. This will handle locking
q = queue.Queue()
for url in worker_data:
q.put(url)
# Define a worker function
def worker(url_queue):
queue_full = True
while queue_full:
try:
# Get your data off the queue, and do some work
url = url_queue.get(False)
data = urlopen(url).read()
print(len(data))
except queue.Empty:
queue_full = False
# Create as many threads as you want
thread_count = 5
for i in range(thread_count):
t = threading.Thread(target=worker, args = (q,))
t.start()
- JimJty
7
6为什么不直接在异常出现时中断程序? - Stavros Korokithakis
1你可以这样做,只是个人喜好。 - JimJty
2我还没有运行代码,但是你不需要将线程变成守护进程吗?我认为在最后一个for循环之后,你的程序可能会退出 - 至少应该这样,因为这就是线程应该工作的方式。我认为更好的方法不是将工作数据放入队列中,而是将输出放入队列中,因为这样你可以有一个主循环来处理从工作线程进入队列的信息,现在它也不是线程化的,你知道它不会过早退出。 - dylnmc
@JimJty 你知道我为什么会得到这个错误吗:
import Queue ModuleNotFoundError: No module named 'Queue' 我正在运行Python 3.6.5,一些帖子提到在Python 3.6.5中应该是 queue,但即使我更改了它,仍然不起作用。 - user9371654显示剩余2条评论
28
给定一个函数f,可以按照以下方式进行线程处理:
import threading
threading.Thread(target=f).start()
要将参数传递给f
threading.Thread(target=f, args=(a,b,c)).start()
- starfry
5
这非常简单。你如何确保在使用完线程后它们会关闭? - cameronroytaylor
我看到了
is_alive 方法,但是我不知道该如何将其应用到线程上。我尝试使用 thread1=threading.Thread(target=f).start() 进行赋值,并用 thread1.is_alive() 进行检查,但是 thread1 被填充为 None,所以没有成功。你知道是否有其他访问线程的方法吗? - cameronroytaylor5你需要将线程对象分配给一个变量,然后使用该变量启动它:
thread1=threading.Thread(target=f),接着调用 thread1.start()。然后你可以使用 thread1.is_alive() 方法来检查线程是否还在运行。 - starfry2成功了。是的,使用
thread1.is_alive() 进行测试,当函数退出时返回 False。 - cameronroytaylor27
我发现这很有用:创建与核心数相同数量的线程,并让它们执行大量的任务(在本例中,调用一个shell程序):
import Queue
import threading
import multiprocessing
import subprocess
q = Queue.Queue()
for i in range(30): # Put 30 tasks in the queue
q.put(i)
def worker():
while True:
item = q.get()
# Execute a task: call a shell program and wait until it completes
subprocess.call("echo " + str(item), shell=True)
q.task_done()
cpus = multiprocessing.cpu_count() # Detect number of cores
print("Creating %d threads" % cpus)
for i in range(cpus):
t = threading.Thread(target=worker)
t.daemon = True
t.start()
q.join() # Block until all tasks are done
- dolphin
3
@shavenwarthog 当然可以根据自己的需求调整“cpus”变量。无论如何,子进程调用将会生成子进程,并且这些子进程将由操作系统分配CPU(Python的“父进程”并不意味着子进程使用“相同的CPU”)。 - dolphin
2你说得对,我的关于“线程在与父进程相同的CPU上启动”的评论是错误的。谢谢回复! - johntellsall
1也许值得注意的是,与使用相同内存空间的多线程不同,多进程不能像那样轻松地共享变量/数据。但还是要点个赞。 - fantabolous
23
我在这里看到了很多例子,大部分都是CPU密集型的,并没有真正的工作。以下是一个计算1000万至1005万之间所有质数的CPU密集型任务的示例,我在这里使用了四种方法:
import math
import timeit
import threading
import multiprocessing
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
def time_stuff(fn):
"""
Measure time of execution of a function
"""
def wrapper(*args, **kwargs):
t0 = timeit.default_timer()
fn(*args, **kwargs)
t1 = timeit.default_timer()
print("{} seconds".format(t1 - t0))
return wrapper
def find_primes_in(nmin, nmax):
"""
Compute a list of prime numbers between the given minimum and maximum arguments
"""
primes = []
# Loop from minimum to maximum
for current in range(nmin, nmax + 1):
# Take the square root of the current number
sqrt_n = int(math.sqrt(current))
found = False
# Check if the any number from 2 to the square root + 1 divides the current numnber under consideration
for number in range(2, sqrt_n + 1):
# If divisible we have found a factor, hence this is not a prime number, lets move to the next one
if current % number == 0:
found = True
break
# If not divisible, add this number to the list of primes that we have found so far
if not found:
primes.append(current)
# I am merely printing the length of the array containing all the primes, but feel free to do what you want
print(len(primes))
@time_stuff
def sequential_prime_finder(nmin, nmax):
"""
Use the main process and main thread to compute everything in this case
"""
find_primes_in(nmin, nmax)
@time_stuff
def threading_prime_finder(nmin, nmax):
"""
If the minimum is 1000 and the maximum is 2000 and we have four workers,
1000 - 1250 to worker 1
1250 - 1500 to worker 2
1500 - 1750 to worker 3
1750 - 2000 to worker 4
so let’s split the minimum and maximum values according to the number of workers
"""
nrange = nmax - nmin
threads = []
for i in range(8):
start = int(nmin + i * nrange/8)
end = int(nmin + (i + 1) * nrange/8)
# Start the thread with the minimum and maximum split up to compute
# Parallel computation will not work here due to the GIL since this is a CPU-bound task
t = threading.Thread(target = find_primes_in, args = (start, end))
threads.append(t)
t.start()
# Don’t forget to wait for the threads to finish
for t in threads:
t.join()
@time_stuff
def processing_prime_finder(nmin, nmax):
"""
Split the minimum, maximum interval similar to the threading method above, but use processes this time
"""
nrange = nmax - nmin
processes = []
for i in range(8):
start = int(nmin + i * nrange/8)
end = int(nmin + (i + 1) * nrange/8)
p = multiprocessing.Process(target = find_primes_in, args = (start, end))
processes.append(p)
p.start()
for p in processes:
p.join()
@time_stuff
def thread_executor_prime_finder(nmin, nmax):
"""
Split the min max interval similar to the threading method, but use a thread pool executor this time.
This method is slightly faster than using pure threading as the pools manage threads more efficiently.
This method is still slow due to the GIL limitations since we are doing a CPU-bound task.
"""
nrange = nmax - nmin
with ThreadPoolExecutor(max_workers = 8) as e:
for i in range(8):
start = int(nmin + i * nrange/8)
end = int(nmin + (i + 1) * nrange/8)
e.submit(find_primes_in, start, end)
@time_stuff
def process_executor_prime_finder(nmin, nmax):
"""
Split the min max interval similar to the threading method, but use the process pool executor.
This is the fastest method recorded so far as it manages process efficiently + overcomes GIL limitations.
RECOMMENDED METHOD FOR CPU-BOUND TASKS
"""
nrange = nmax - nmin
with ProcessPoolExecutor(max_workers = 8) as e:
for i in range(8):
start = int(nmin + i * nrange/8)
end = int(nmin + (i + 1) * nrange/8)
e.submit(find_primes_in, start, end)
def main():
nmin = int(1e7)
nmax = int(1.05e7)
print("Sequential Prime Finder Starting")
sequential_prime_finder(nmin, nmax)
print("Threading Prime Finder Starting")
threading_prime_finder(nmin, nmax)
print("Processing Prime Finder Starting")
processing_prime_finder(nmin, nmax)
print("Thread Executor Prime Finder Starting")
thread_executor_prime_finder(nmin, nmax)
print("Process Executor Finder Starting")
process_executor_prime_finder(nmin, nmax)
if __name__ == "__main__":
main()
这是我在我的Mac OS X四核机器上的测试结果。
Sequential Prime Finder Starting
9.708213827005238 seconds
Threading Prime Finder Starting
9.81836523200036 seconds
Processing Prime Finder Starting
3.2467174359990167 seconds
Thread Executor Prime Finder Starting
10.228896902000997 seconds
Process Executor Finder Starting
2.656402041000547 seconds
- PirateApp
5
1@TheUnfunCat,对于 CPU 绑定任务来说,没有进程执行器比线程更好。 - PirateApp
2很棒的回答,伙计。我可以确认,在Python 3.6上的Windows系统中,ThreadPoolExecutor对于CPU密集型任务没有任何好处。它不利用核心进行计算。而ProcessPoolExecutor则会将数据复制到它生成的每个进程中,这对于大矩阵来说是致命的。 - Anatoly Alekseev
1非常有用的例子,但我不明白它是如何工作的。我们需要在主调用之前加上
if __name__ == '__main__':,否则测量会自行生成并打印 An attempt has been made to start a new process before...。 - Stein1@Stein 我相信这只是在Windows上的问题。 - AMC
谢谢。为什么ProcessExecutor比ThreadExecutor更好呢?您能否添加更多细节或分享参考资料? - Avv
23
Python 3提供了启动并行任务的功能,这使我们的工作更加轻松。
以下是一个示例:
ThreadPoolExecutor示例(源代码)
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Start the load operations and mark each future with its URL
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
ProcessPoolExecutor(源代码)
import concurrent.futures
import math
PRIMES = [
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419]
def is_prime(n):
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def main():
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
- Jeril
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接