我正在尝试构建一个Shell脚本,用于在图像中搜索文本。根据文本,该脚本会尽力从图像中获取文本。但是对于文字字体颜色与其周围较小区域类似的图片,该脚本不能正常工作。您是否能提供帮助和意见?
# !/bin/bash
#
# imt-ocr.sh is image magick tessearc OCR tool that is used for finding out text in image
#
# Arguments:
# 1 -- image filename (with path)
# 2 -- text to search in image (default to '')
# 3 -- occurence of text (default to 1)
# Usage:
# imt-ocr.sh [image_filename] [text_to_search] [occurence]
#
image=$1
txt=$2
occurence=$3 # Default to 1
if [ "$occurence" == "" ]
then
occurence=1
fi
get_major_color ()
# Returns the major color of an image with its hex value
# Parameter: Image filename (with path)
# Return format: Returns a string "hex_val_of_color major_color_name"
{
convert $1 -format %c histogram:info: > x.txt
cat x.txt | awk '{print $1}' > x1.txt
h=$(sort -n x1.txt | tail -1);
color_info=$(cat x.txt | grep "$h" | cut -d '#' -f2)
rm -rf x.txt x1.txt
echo "$color_info"
}
invert_color()
# Inverts the color hex value
# Parameter: Hex value to be inverted
# Return format: Returns in hex
{
input_color_hex=$1 # Input color's hex value
white_color_hex=FFFFFF # White color's hex vlaue
inv_color_hex=`echo $(printf '%06X\n' $((0x$white_color_hex - 0x$input_color_hex)))`
echo $inv_color_hex
}
start_scale=100
end_scale=300
increment_scale=100
tmp_img=dst.tif
attempt=1
for ((scale=$start_scale, attempt=$attempt; scale <= $end_scale ; scale=scale+$increment_scale, attempt++))
do
echo "IMT-OCR-LOG: Scaling image to $scale% in attempt #$attempt"
convert $image -type Grayscale -scale $scale% $tmp_img
tesseract $tmp_img OUT
found_oc=$(grep -o "$txt" OUT.txt | wc -l)
echo "IMT-OCR-LOG: Found $found_oc occurence(s) of text '$txt' in attempt #$attempt"
if [ $occurence -le $found_oc ] && [ $found_oc -ne 0 ]
then
echo "IMT-OCR-LOG: Printing out the last text found on image"
echo "IMT-OCR-LOG: ======================================================"
cat OUT.txt
echo "IMT-OCR-LOG: ======================================================"
rm -rf $tmp_img OUT.txt
exit 1
else
echo "IMT-OCR-LOG: Getting major color of image in attempt #$attempt"
color_info=`get_major_color $image`
true_color=$(echo $color_info | awk '{print $2}')
true_val=$(echo $color_info | awk '{print $1}')
echo "IMT-OCR-LOG: Major color of image is '$true_color' with hex value of $true_val in attempt #$attempt"
# Blur the image
echo "IMT-OCR-LOG: Bluring image in attempt #$attempt"
convert $tmp_img -blur 1x65535 $tmp_img
# Flip the color
inverted_val=`invert_color $true_val`
echo "IMT-OCR-LOG: Inverting the major color of image from 0x$true_val to 0x$inverted_val in attempt #$attempt"
convert $tmp_img -fill \#$inverted_val -opaque \#$true_val $tmp_img
# Sharpen the image
echo "IMT-OCR-LOG: Sharpening image in attempt #$attempt"
convert $tmp_img -sharpen 1x65535 $tmp_img
# Find text
tesseract $tmp_img OUT
found_oc=$(grep -o "$txt" OUT.txt | wc -l)
echo "IMT-OCR-LOG: Found $found_oc occurence(s) of text '$txt' in attempt #$attempt"
if [ "$found_oc" != "0" ]
then
if [ $occurence -le $found_oc ]
then
echo "IMT-OCR-LOG: Printing out the last text found on image"
echo "IMT-OCR-LOG: ======================================================"
cat OUT.txt
echo "IMT-OCR-LOG: ======================================================"
rm -rf $tmp_img OUT.txt
exit 1
fi
fi
fi
rm -rf OUT.txt
done
rm -rf $tmp_img
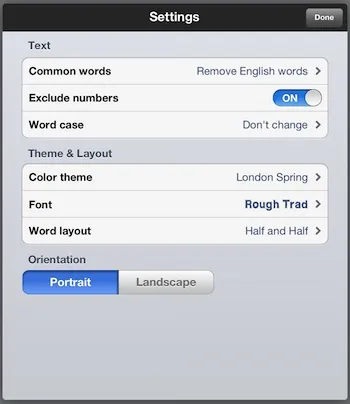
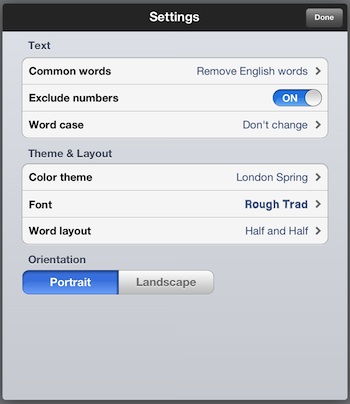
这里是一个带有问题的示例,图片(test.jpeg)http://www.igoipad.com/wp-content/uploads/2012/07/03-Word-Collage-iPad.jpeg
[admin@ba-callgen image-magick-tesseract-processing]$ sh imt-ocr.sh test.jpeg Common
IMT-OCR-LOG: Scaling image to 100% in attempt #1
Tesseract Open Source OCR Engine with Leptonica
IMT-OCR-LOG: Found 0 occurence(s) of text 'Common' in attempt #1
IMT-OCR-LOG: Getting major color of image in attempt #1
IMT-OCR-LOG: Major color of image is 'grey96' with hex value of F5F5F5 in attempt #1
IMT-OCR-LOG: Bluring image in attempt #1
IMT-OCR-LOG: Inverting the major color of image from 0xF5F5F5 to 0x0A0A0A in attempt #1
IMT-OCR-LOG: Sharpening image in attempt #1
Tesseract Open Source OCR Engine with Leptonica
IMT-OCR-LOG: Found 0 occurence(s) of text 'Common' in attempt #1
IMT-OCR-LOG: Scaling image to 200% in attempt #2
Tesseract Open Source OCR Engine with Leptonica
IMT-OCR-LOG: Found 1 occurence(s) of text 'Common' in attempt #2
IMT-OCR-LOG: Printing out the last text found on image
IMT-OCR-LOG: ======================================================
Settings M...
Text
Common words
Exclude numbers
word case
Theme & Layuul
Color theme
Fnnl
Word layout
Clrien lalion
7301
Lrmclsc ape
\u2018OTC
Ergl sw v.-ords >
li( `
I):Jntc1'\:1r\qa )
Landon Spring >
Hough Trad >
H3'fJ|1d :-Ialf >
H L
IMT-OCR-LOG: ======================================================
[admin@ba-callgen image-magick-tesseract-processing]$
[admin@ba-callgen image-magick-tesseract-processing]$
[admin@ba-callgen image-magick-tesseract-processing]$
[admin@ba-callgen image-magick-tesseract-processing]$
[admin@ba-callgen image-magick-tesseract-processing]$
[admin@ba-callgen image-magick-tesseract-processing]$
[admin@ba-callgen image-magick-tesseract-processing]$ sh imt-ocr.sh test.jpeg Portrait
IMT-OCR-LOG: Scaling image to 100% in attempt #1
Tesseract Open Source OCR Engine with Leptonica
IMT-OCR-LOG: Found 0 occurence(s) of text 'Portrait' in attempt #1
IMT-OCR-LOG: Getting major color of image in attempt #1
IMT-OCR-LOG: Major color of image is 'grey96' with hex value of F5F5F5 in attempt #1
IMT-OCR-LOG: Bluring image in attempt #1
IMT-OCR-LOG: Inverting the major color of image from 0xF5F5F5 to 0x0A0A0A in attempt #1
IMT-OCR-LOG: Sharpening image in attempt #1
Tesseract Open Source OCR Engine with Leptonica
IMT-OCR-LOG: Found 0 occurence(s) of text 'Portrait' in attempt #1
IMT-OCR-LOG: Scaling image to 200% in attempt #2
Tesseract Open Source OCR Engine with Leptonica
IMT-OCR-LOG: Found 0 occurence(s) of text 'Portrait' in attempt #2
IMT-OCR-LOG: Getting major color of image in attempt #2
IMT-OCR-LOG: Major color of image is 'grey96' with hex value of F5F5F5 in attempt #2
IMT-OCR-LOG: Bluring image in attempt #2
IMT-OCR-LOG: Inverting the major color of image from 0xF5F5F5 to 0x0A0A0A in attempt #2
IMT-OCR-LOG: Sharpening image in attempt #2
Tesseract Open Source OCR Engine with Leptonica
IMT-OCR-LOG: Found 0 occurence(s) of text 'Portrait' in attempt #2
IMT-OCR-LOG: Scaling image to 300% in attempt #3
Tesseract Open Source OCR Engine with Leptonica
IMT-OCR-LOG: Found 0 occurence(s) of text 'Portrait' in attempt #3
IMT-OCR-LOG: Getting major color of image in attempt #3
IMT-OCR-LOG: Major color of image is 'grey96' with hex value of F5F5F5 in attempt #3
IMT-OCR-LOG: Bluring image in attempt #3
IMT-OCR-LOG: Inverting the major color of image from 0xF5F5F5 to 0x0A0A0A in attempt #3
IMT-OCR-LOG: Sharpening image in attempt #3
Tesseract Open Source OCR Engine with Leptonica
IMT-OCR-LOG: Found 0 occurence(s) of text 'Portrait' in attempt #3
[admin@ba-callgen image-magick-tesseract-processing]$
您可以看到,我能找到文字“common”,但找不到“Portrait”。原因是“Portrait”字体颜色的问题。有助于改进此脚本的任何帮助...
我正在使用Centos 5。
{kind=link}