这篇回答使用了Xeon 5500和7500数据手册中的元素(它们使用环和Rbox连接到系统的其他部分),但是该回答谈论的系统其环总线架构类似于IvB-EX Xeon e7 v2(使用2个环),但也适用于Haswell-EX(使用4个环,并在两者之间使用互连)。我假设每个环仍然分为4个32字节的双向环:嗅探/失效、数据/块、请求/地址、确认环。
Xeon e7 v2:
在复位信号的下降沿,该芯片立即确定NodeID和相邻的NodeIDs、x2APIC集群ID和逻辑处理器APIC ID(在桌面CPU上的SnB之前,它使用输入引脚上的MCH信号进行采样;我不确定多插座是否也是如此)。此后,缓存和TLB被清空,核心执行BIST,然后进行多插座
MP初始化算法。Xeon D-1500 vol2显示了一个CPUNODEID寄存器;我不确定在重置后更改该寄存器会引起什么样的行为,涉及正在进行的事务。当其他核心的CPUNODEID发生变化时,SAD目标列表是否通过自动生成的写入来更改,或者它是否触发SMI处理程序,或者这是程序员的任务?我不知道。假设,在更改SAD配置之前,所有代理都必须处于静止状态,以防止它们访问Cbo。
缓存代理
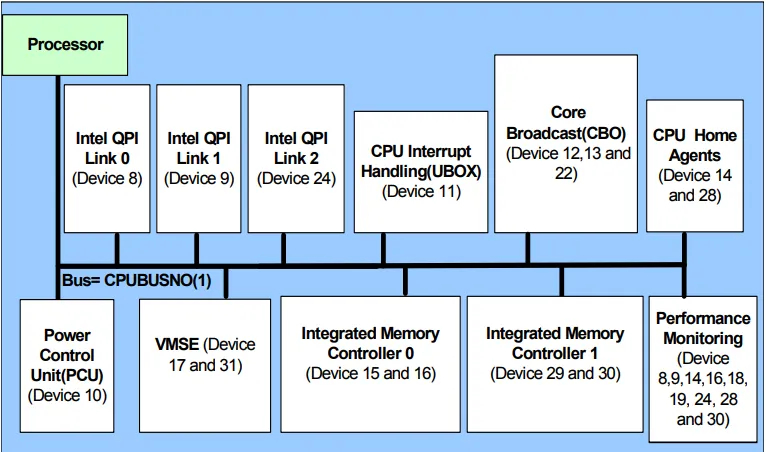
每个套接字都有一个缓存代理和一个主机代理(或在MCC / HCC上有2个CA和2个HA)。缓存代理的功能是通过Cbo切片进行地址哈希(在SnB之前,缓存代理是与其相关联的Sbox和50%的Cbox的组合,其中Sbox是从环形拾取Cbox消息并将它们直接转换为QPI消息到Rbox的QPI接口,而Cbox是LLC切片和环形总线之间的接口;在SnB之后,Cbo在一个环形接口上实现了Sbox和Cbox的功能并发送QPI / IDI消息)。映射在引导时设置,因为那时候设置了窥探模式。在Haswell-EX上,可以在BIOS中在没有窥探、主页窥探、早期窥探、源窥探、HS w.目录+ OSB + HitME缓存或COD之间切换窥探模式,具体取决于CPU;虽然我还没有看到任何与snoop模式相关的PCIe配置寄存器的数据表。当此项更改后重置时,不确定正在进行的事务会出现什么行为。当BIOS禁用核心时,它不会影响Cbo,Cbo将继续运作。在Nehalem-EX上,缓存代理是一个单独的组件(请参见7500数据表),但在后来的体系结构中,它用于指代整个Cbo。在Haswell-EP上引入的COD(Die上的集群)将缓存代理分为每个套接字的2个。
在每个缓存切片中,都有一个缓存盒子,它是LLC和系统其余部分之间的控制器和代理,基本上是LLC控制器。Cbo包含请求表,其中包含所有未决事务。 Cbo支持三种类型的交易:1.核心/IIO发起的请求2.英特尔QPI外部嗅探3.LLC容量驱逐。每个事务在TOR中都有一个关联条目。 TOR条目保存Cbo所需的信息,以唯一地识别请求(例如地址和事务类型)和跟踪事务当前状态所需的状态元素。
核心/PCIe请求被地址哈希以选择要翻译并将请求放置在环上的Cbo。
核心知道在环上发送请求的方向以获得最小延迟时间,因此它将配置相同的地址映射,并等待环上的空位以容纳事务。
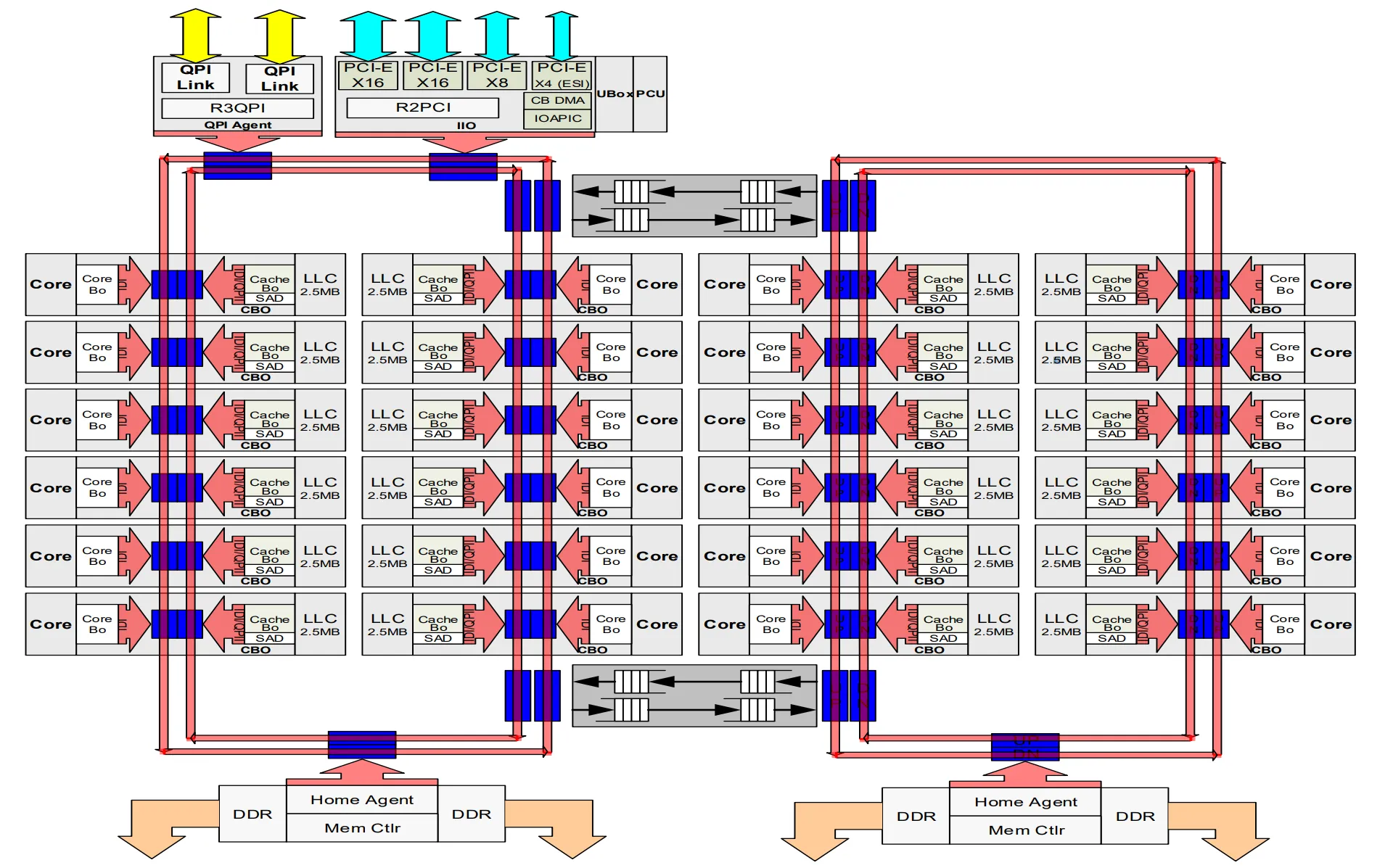
核心发起的请求使用IDI数据包接口。在Broadwell-EX上显示了IDI(芯片内部互联)。该图表明核心仅使用IDI数据包,而CBos使用QPI和IDI。Xeon e7 v2操作码显示在表2-18中,QPI操作码显示在表2-218中。这也可以防止像IIO这样的组件在解码之前声明地址,因为它只接受QPI操作码。在一些图表上,Ubox被描绘为与IIO共享一个停止位;在其他图表上,它们是分开的。
当空位出现时,与Cbo共享的双向停止逻辑会将32字节的flit放入请求环中,如果Cbo需要同时向同一方向发送,则选择目标极性正确的事务,否则使用其他形式的仲裁。我认为内核可以在一个周期内向两个方向写入,而停止状态下的Cbo可以从两个方向读取,或者根据仲裁情况,Cbo和内核可以各自写一个并读取一个。我想象IDI flit的链路层标头包含源ID、目标ID,允许更高层次的事务(传输层)按顺序分割并非连续地到达,这样它就知道是否继续缓冲该事务并从环中移除flit。(Ring IDI/QPI不同于QPI,因为QPI是点对点的,没有链路层源/目标;而且QPI只有80位的flit,很容易找到一个图表;但环形总线标头不是这种情况)。Cbo针对每个目的地实现了QPI链路层信用/借记方案,以防止缓冲区溢出。这个请求可能只需要1个flit,但缓存行获取需要3个flit。Cbo解码时看到相关的操作码和地址,并在其被分配的地址范围内解码地址以确定如何处理它。
在Cbo中,请求同时分配到TOR并通过SAD发送到LLC。非LLC消息类型也会在分配到TOR时经过SAD。SAD接收地址、地址空间、操作码和一些其他交易细节。为了减少对不同DRAM容量所需解码器条目的数量,地址解码器具有多个交错选项,在Xeon 7500上分为三个解码器,优先级从高到低依次为:I/O小(IOS)解码器,I/O大(IOL)解码器,DRAM解码器。在Xeon e7 v2上,有4个解码器:DRAM,MMIO,Interleave,legacy。
每个解码器都会同时接收一个地址进行访问。与解码器中的条目匹配的地址将导致解码器查找并生成QPI内存属性和NodeID。每个解码器只允许一个匹配。在高优先级解码器中的地址匹配将覆盖低优先级解码器中的同时匹配。
I/O解码器
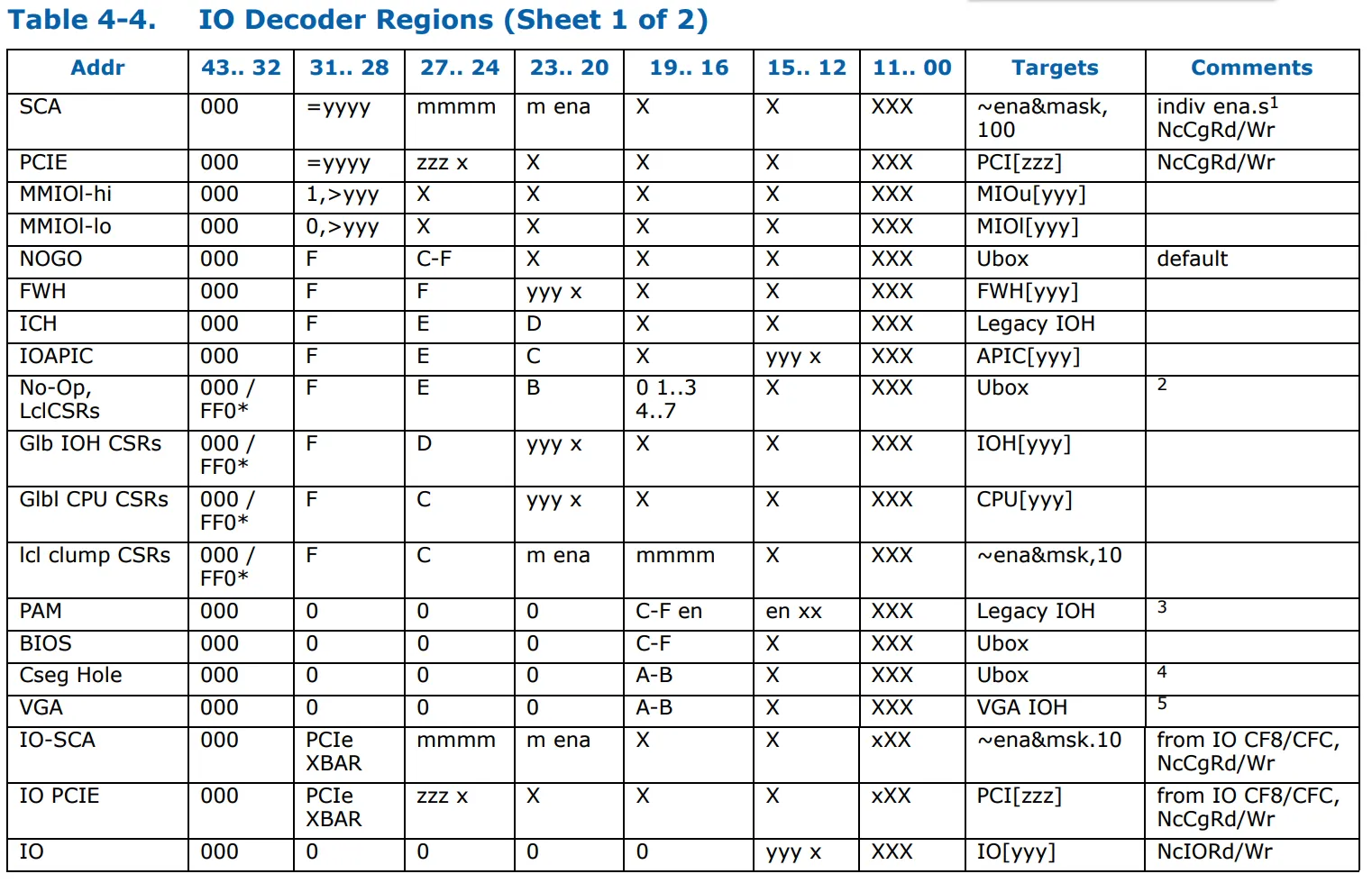
这里提供了8个目标列表,分别是PCI[]、MIOU[]、MIOL[]、FWH[]、APIC[]、IOH[]、CPU[]和IO[]。除此之外,一些I/O解码器条目
可以通过Cbo设备下的CSR进行配置,每个Cbo都有自己的SAD。本地Cfg寄存器仅映射本地PCIe配置寄存器的固定MMIO区域,只有一个目标,即本地插座,并且不需要任何目标列表(它总是会被路由到Ubox,因此NodeID将是7500上本地Ubox的ID)。
Intel Xeon处理器E7 v2产品系列实现了4位节点ID(NID)。Intel Xeon处理器E7 v2产品系列每个插槽最多可以支持2个HA。同一插槽中的HA将由
NID [2]区分。在目标仅为3位的情况下,假定
NID [2]为零。因此,插座ID将是
NID [3,1:0]。Intel® Xeon®处理器7500系列实现了5位,并且最多可以支持四个插座(由
NID [3:2]选择,当
NID [4]为零时)。每个插座内有四个设备(
NID [1:0]):Intel® 7500芯片组(00),B0 / S0(01),Ubox(10),B1 / S1(11)。 B0 / S0和B1 / S1是两组HA(Bboxes)和CA(Sboxes)。
E7 v2有4位NodeID,意味着它最多支持8个插槽和每个插槽2个HA。如果一个插槽有2个HA(MCC,HCC),则仍将为每个HA分别拥有2个独立的NodeID,无论它是否处于COD模式下,并且可以使用半球位将缓存和DRAM局部性利用于NUMA感知应用程序,因为哈希算法始终将CBos与其插槽半部分(半球)中的HA相关联。
例如,哈希函数可能导致addr[6]选择核心中的CBo半球,具体取决于半球中有多少(n)CBos,addr[x:7] mod n选择CBo。每个CBo处理特定范围的LLC集,其中插槽的LLC高速缓存覆盖整个地址范围。相反,COD创建了2个缓存亲和力域(其中每个半球中的CBos现在都涵盖完整的地址范围,而不是地址范围的一半,因此成为自己的官方NUMA节点,具有完全跨越缓存(而不是2个NUCA缓存)的缓存,就像它是自己的插槽--核心缓存访问现在永远不会穿过到插槽的另一半,减少延迟,但由于缓存现在只有一半大小而降低命中率--如果仅访问与NUCA / NUMA节点相关联的内存,则仍可以获得相同级别的缓存延迟和更多容量,即使关闭COD)。与CBo半球相关联的HA也是CBo在本地访问DRAM时使用的HA,因为
addr[6]用于选择DRAM解码器中的HA。当存在多个插槽时,
addr[8:6]选择HA,它可能位于另一个插槽上,因此它将使用
addr[6]的一半中的CBos,但是如果NUMA调度程序无法正确地“亲和”进程和内存,则CBo将将LLC miss发送到另一个插槽上的home agent,
如果与其关联的home agent的addr[8:7]未被使用。
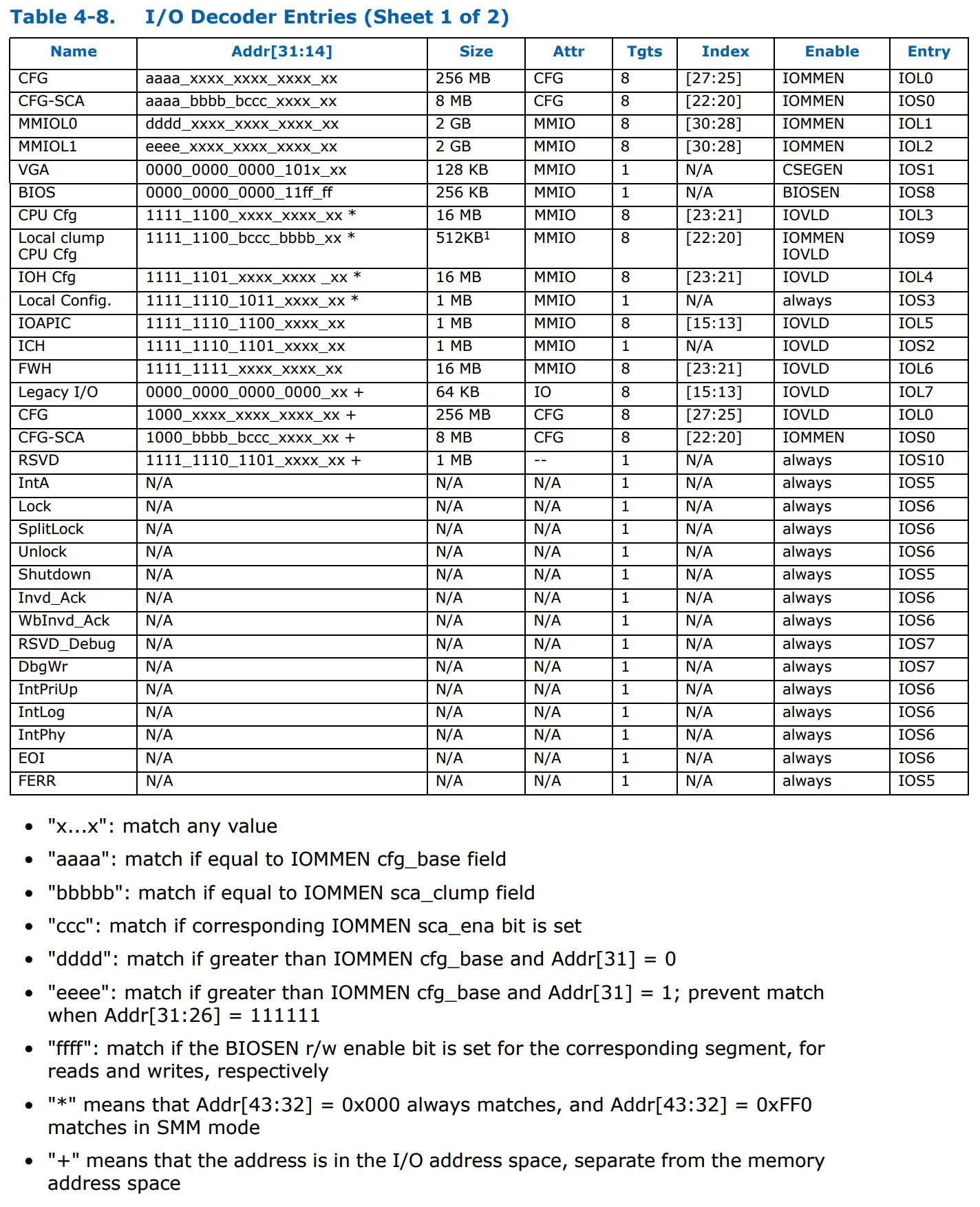
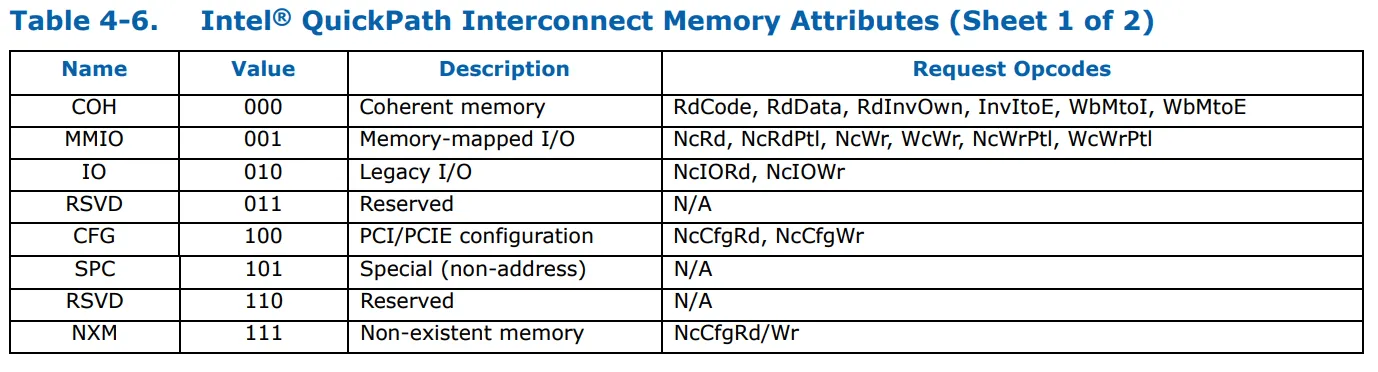
这是I/O解码器列表的释义。表格包括IOS和IOL解码器条目。属性(例如CFG)是输出操作码类别,用于选择操作码。
DRAM解码器由两个数组组成,即CAM数组和payload数组。在Xeon 7500上,DRAM解码器每个数组有20个条目,用于20个不同的最小256MiB区域,具有8个子区域(交错)。DRAM解码器条目还可用于定义一致性、MMIO、MMCG和NXM空间。如果需要多个PCI段,DRAM解码器条目将用于在DRAM顶部配置它,但与正常的低于4G的PCIe条目不同,这些条目不应交错,因此多个目标将需要多个SAD条目,并且需要将这些相同的SAD条目放入每个插座中。CAM数组具有特殊的比较逻辑,可以计算出地址是否小于或等于每个条目的区域限制,以允许任何256 MiB倍数的区域大小。区域限制地址位[43:28]存储在条目的CAM数组中(意味着256MiB粒度)。payload数组(tgtlist-attr)每个条目有42位。

你会期望看到这些SAD DRAM解码器条目有20个64位(保留6位)配置寄存器(而且所有插座上的SAD都使用同一组SAD规则),尽管这是针对5500的,我认为在更新的CPU上
仍然只有一组寄存器用于所有CBo SADs。
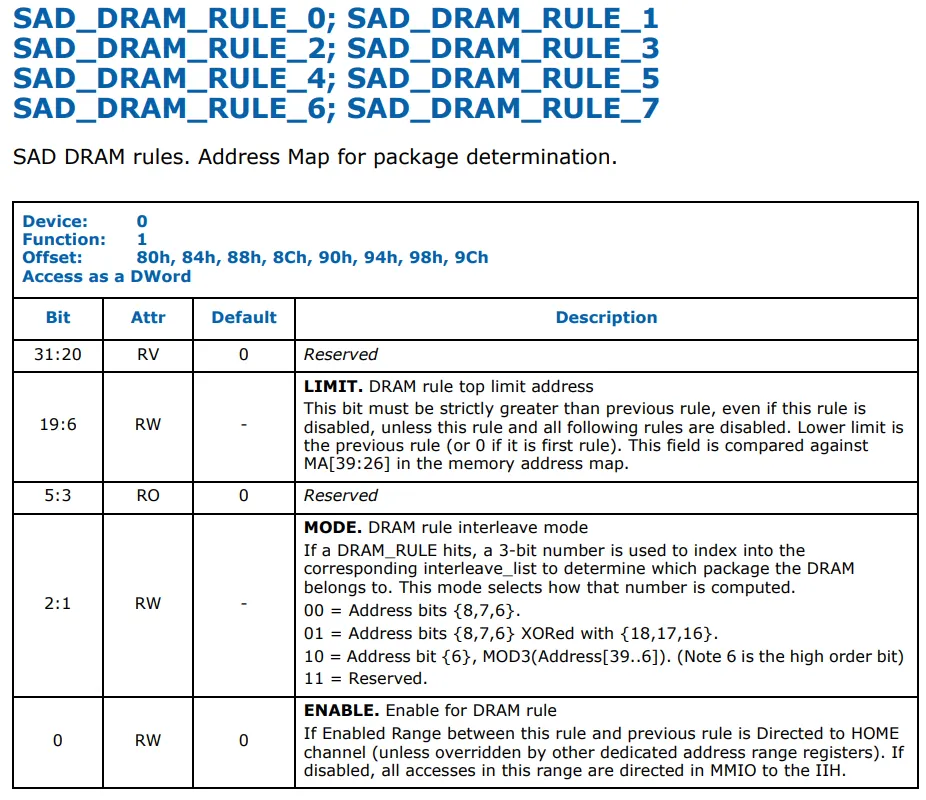
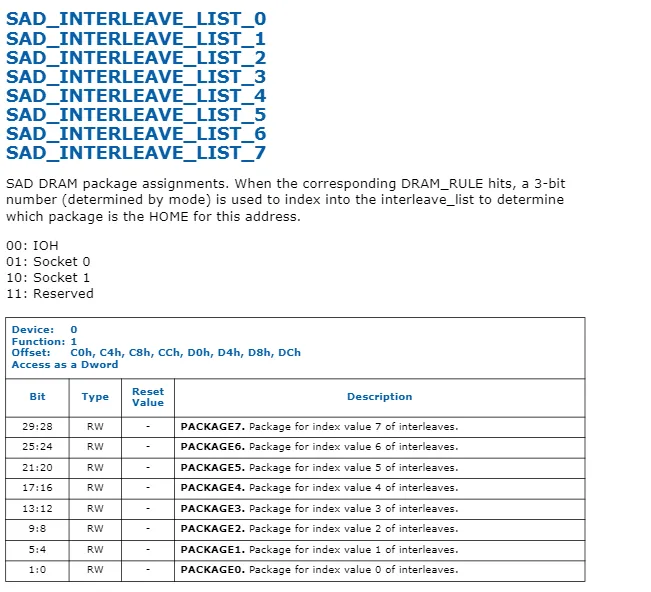
在5500上,您需要在[19:6]中为规则设置PA[39:26],并在
SAD_DRAM_RULE_0中设置索引生成方法,然后在
SAD_INTERLEAVE_LIST_0中放置目标列表--这将设置解码器字段,并可能设置其他字段。必须有一个寄存器来设置条目的半球位(但在数据表上没有显示),它告诉它将NID列表中的第一个比特与当前Cbox的
CboxID[2](它所属的HA -- 与当前Cbox的HA即
addr[6]的
NID[1]相同)进行异或运算。其思想是将NID
1始终设置为目标列表中的0,以便与当前Cbox的
CboxID[2]进行异或运算,从而选择属于Cbox的家庭代理(这就是为什么不需要为每个单独的CBox设置SAD条目)。
目标列表条目是在Xeon 5500 Nehalem-EP (Gainestown)上2位,该处理器属于DP(双处理器)服务器系列,因此最多只有2个插槽(仅有2个QPI链接,一个用于IOH,一个用于CPU之间),因此最多只有4个HA。它将在7500上变为3位(4个QPI)(每个具有2个HA的4个插槽:8个HA),这扩展到4位以包括冗余的
NID [4]。必须在所有插槽上设置相同的SAD和DRAM解码条目配置。
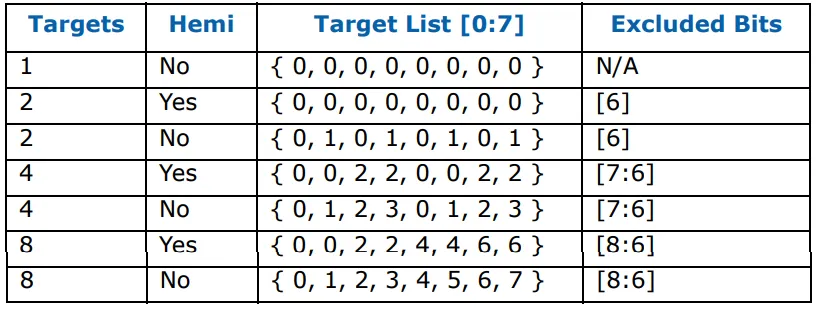
对于8个节点(HAs)的交错,使用地址中的
addr[8:6]进行,这些被从发送到目标HA的地址中删除(排除),因为它知道自己的ID。上述表格适用于7500,其中
addr[6]用于识别插座上的HA(
NodeID[1])。
有两种类型的请求:
非一致性请求
非一致性请求是指映射到非一致性地址空间(如MMIO)或非内存请求(如IO读/写、中断/事件等)的数据访问。当NC请求访问NC存储器时,它们会根据地址哈希值被发送到Cbo,就像一致性请求一样。不针对内存的NC请求会被发送到生成请求的核心所附加的Cbo。
MMIO
Cbo收到与特定地址相关的事务后,将其通过I/O和DRAM解码器,并存储在TOR中,但如果IDI操作码是不可缓存的(例如PRd),则不会将其发送到LLC片。核心根据L1访问中的内存类型在PAT/MTRR读取上发送此操作码,除了WCiL之外,它会使其他核心和缓存代理中的别名失效。它将匹配MMIO区域之一的I/O解码器条目。某些CPU上会有8个IOAPICs(Xeon 7500上没有,因为它涉及ICH/IOH,而且这是ringbus的第一个实现;但是当PCH在Nehalem Ibex Peak上引入时,它被集成在IIO模块的芯片上)。FECX_(yyyx)XXXh中的yyy(位[15:13])将用于索引NodeID的APIC []表。这意味着在64KiB连续区域中每个IOAPIC有8KiB。SAD输出NodeID和要使用的操作码(NcRd)。Xeon 3400手册谈到'node Id'被分配给IIO,也许这是'chipset/IOH'节点ID,但E7 v2没有这个,所以可能有一个隐藏的扩展来选择IIO和Ubox之间或者QPI请求附加了一个单独的ID,Cbo也有一个ID。然后,IIO将根据集成的IIO和PCI桥寄存器路由MMIO访问,并从DMI中减去解码。
此外,MMIO BARs有2个区域,即MMIOL和MMIOH。最后7个插槽最多可交错256MiB的MMIOLL,前7个插槽最多可拥有256MiB的MMIOLU,具体取决于PCIEXBAR的值(如果PCIEXBAR在2GiB,则MMIOLL将不存在)。7500数据表说明MMIOH需要每个插槽单独的I/O解码器条目。
通用服务器CPU内存布局如下:
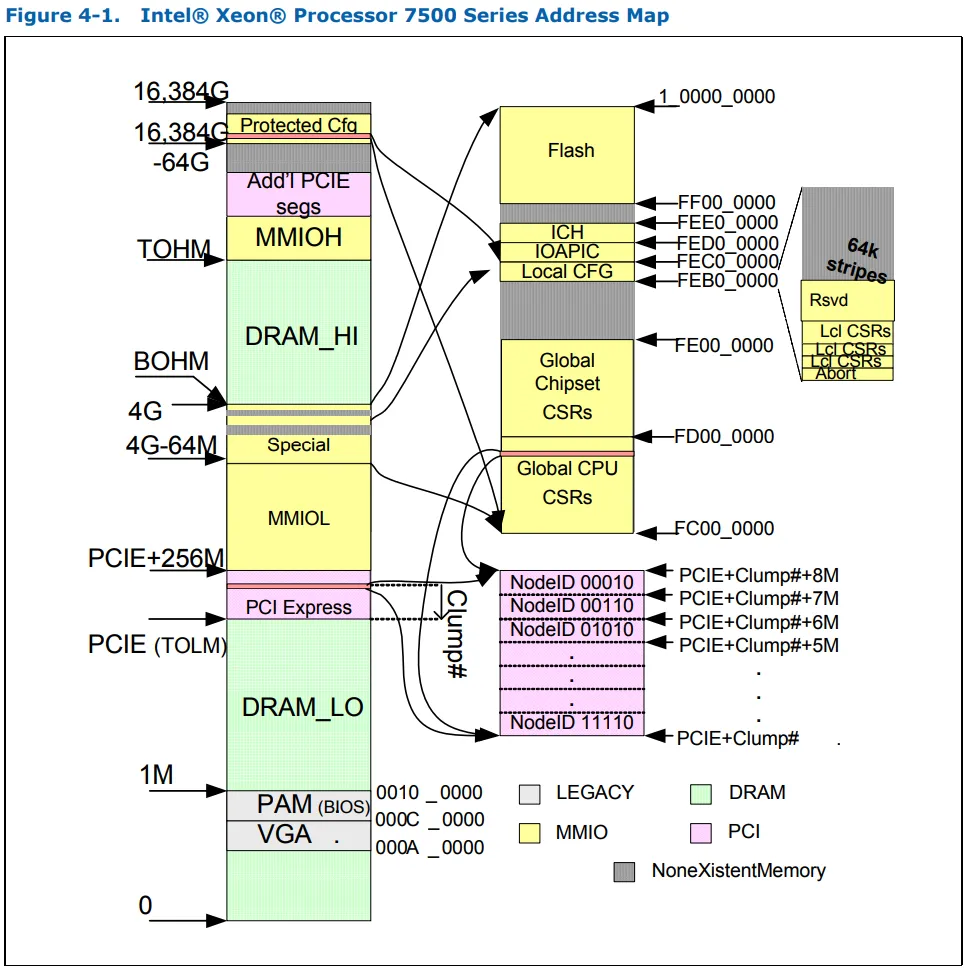
有一个SCA_PCIE子区域,占据了256MiB配置空间的前8MiB。该子区域必须在4GiB以下的256MiB区域内。当事务中的地址在本地簇地址范围(每个插槽1MiB)内时,常规PCIe解码会被覆盖,并且NodeID将被视为PhysicalAddr[22:20]。请注意,1MiB是总线0(32 dev * 8 func) - 所有插槽的总线0对所有其他插槽都可见。然后将NodeID放入具有NcCfgRd操作码和NodeID目标的QPI事务中,将flits放置在请求环上。这将被识别该NID范围的QPI链接吸收,并一旦到达目标插槽,将被路由到Ubox(在SnB上,IIO根据Xeon 3400 vol2 5.8.1似乎处理NcCfg请求),Ubox将执行配置读取; Ubox在7500上具有唯一的NodeID,因此它将无缝地路由到Ubox(在e7 v2上,我们假设对于这些插入的数据包,存在隐藏的ID)。在QPI数据包中,Cbo可能会插入请求节点ID、请求CBo ID和事务ID。Ubox会缓冲和跟踪事务(我假设在确认环上发送确认回来),并在处理完成后将结果(成功/失败)发送回QPI数据环中源NodeID的QPI数据包,然后它会返回到QPI链接。CBo完成事务并通过数据环向核心返回IDI数据包。
如果地址超出了8MiB区域,但在256 PCIe配置空间中,则它将与I/O解码器列表中的顶部条目匹配。zzz位(显然是第27-25位)用于索引目标列表以选择一个节点。我们知道这明显是总线号的前3位。这必须表明,假设索引=交错列表中的套接字编号,套接字0分配将从总线8开始(总线0为总线0),套接字1将从总线32开始(总线0为总线1),套接字2将从总线64开始(总线0为总线2),套接字3将从96开始(总线0为总线3)(并且在发送到套接字3的请求中,我假设它会删除NodeID位,以便它会看到总线1而不是96(或者如果别名而不是加1,则为总线0))。从此PCIEXBAR配置空间访问限制了段中总线数为32,因此需要为每个段分配完整的256MiB别名(在DRAM解码器中,您可以通过设置目标列表仅包含套接字上的NodeID来设置MMCFG条目以定位特定套接字),并且对此范围的任何访问都将定向到该套接字。PCI [zzz]似乎意味着:索引到PCI目标列表以选择NodeID,并为请求赋予属性类的操作码(基于TOR详细信息的NcCfgRd / Wr),Cbo还将地址转换为总线/设备/功能号。BIOS必须读取此配置寄存器,以便输入PCIe端口上的PCI-to-PCI桥接器的正确从属设备编号。
在I/O解码器上,还有LclCSRs(本地配置),Glb IOH CSRs(IOH Cfg),Glb CPU CSRs(CPU Cfg),lcl clump CSRs(本地clump CPU配置)条目。这些是访问PCIe配置空间寄存器(CSRs)的固定MMIO别名,而不使用PCIEXBAR。
IO
所有插座都有固定的IO端口和可以设置在带有内存空间指示符的BAR中的端口。
IO请求由Cbo接收,并在IO表中查找。IDI列表上似乎没有单独的IO操作码,也没有PRd的UC写入对应项,可能存在未记录的操作码,或者将其编码为WCiL。
IO请求可以是IO-PCIE,IO-SCA或非PCIe-IO。如果地址与底部行中的模式匹配且设置了IO位并且地址为CF8 / CFC,则会在地址[11:8](核心只能发出8位寄存器索引)中插入4个零,使CONFIG_ADDRESS函数号LSB从第12位开始而不是8位,并且总线号MSB位于第27位,现在将其与第3个底部行进行比较。如果顶部5个总线位匹配,则通过[22:20]确定NodeID,并向该NodeID发送NcCfgRd / Wr。如果不是CF8 / CFC,则通过使用IO_Addr [15:13]查找目标列表条目来确定目标NodeID-因此是IO端口的3个最高有效位。这意味着每个插槽都有8KiB的I / O空间,并且变量I / O必须设置在插槽范围内。对于固定的I / O访问,如果将前3位设置为插槽,则理论上它们可以被Cbo匹配删除;因此,为了访问插槽1上的20h,您将使用2020h。
可以与解码器条目匹配的核心发出的请求包括:• IntA、Lock、SplitLock、Unlock、SpCyc、DbgWr、IntPriUp、IntLog、IntPhy、EOI、FERR、Quiesce。它们分配在TOR中,但不发送到LLC。当硬件锁操作跨越2个缓存行时,使用SplitLock。Lock曾经由Cbo指示Ubox静默所有代理以执行原子操作,但这是不必要的开销,因为它可以在高速缓存一致性协议中实现。所以现在Lock RFO可以被Cbo拾取并使其他副本无效,并响应,直到那时核心无法读取该行(假定LLC中有一个指示核心中该行已锁定的指示器,在嗅探过滤器中表示)。
一致请求
一致请求是访问映射到一致性地址空间的内存地址的请求。它们通常用于以高速缓存行粒度传输数据和/或更改高速缓存行的状态。最常见的一致请求是数据和代码读取、RFO、ItoMs和写回驱逐(WbMtoI)/写回(WbMtoE)到LLC(仅包含高速缓存)。一致请求由Cbo服务,它持有指定地址的LLC切片,由哈希函数确定。
如果地址解码到DRAM区域,并且最后一级缓存片连接到该Cbo表明套接字中的核心拥有该行(用于一致性读取),则Cbo会对该本地核心进行嗅探请求(这显然是在讨论具有LLC片段中的Snoop过滤器位的包容性L3,通过其他核心的访问;请注意,在SKL服务器网状互连(而不是桌面环路),L3是非包容性的;在包容性缓存中,如果它在2个核心中有效,则LLC副本是有效的)。
如果缓存中没有该行(假设使用COD/HS模式 w.带目录(ecc)+ OSB + HitME高速缓存),那么请求缓存行的缓存代理不会广播探测。相反,它会将请求在QPI中转发到拥有地址的HA NodeID,基于SAD译码器规则,然后向可能拥有该行的其他缓存代理发送探测。转发到主节点会增加延迟。但是,HA可以在DRAM的ECC位中实现一个目录以提高性能。该目录用于过滤到远程插座或节点控制器的探测;成功的探测响应将分配目录缓存中的条目。目录编码3个状态:未出现在任何节点中,在1个节点中进行了修改(需要写回和降级,并且该位可能指示针对目标广播的节点的一半),在多个节点中共享(这意味着不需要探测);如果不支持目录,则我认为必须在每次DRAM访问时窥视所有插座,而访问正在进行。 Haswell-EP还包括目录缓存(HitMe)以加速目录查找。但是,由于每个HA仅有14 KiB,这些缓存非常小。因此,只有经常在节点之间传输的高速缓存行存储在HitMe缓存中。目录缓存存储指示哪些8个节点(Haswell-EP上有最多3 * 2个逻辑COD节点)拥有高速缓存行的8位向量。当请求到达主节点时,会检查目录缓存。如果它包含所请求行的条目,则会根据目录缓存发送探测。如果目录缓存中没有该请求的缺失,HA将从内存中的地址获取,并读取目录位,如果在某个插座中被修改,则相应地发送探测,如果不需要探测,则直接发送从内存中获取的数据并且不分配条目。
[3]
E7 v2 HA实现了128个入站内存缓冲区(Home tracker)和512个追踪器(备用追踪器)。所有进入HA的主通道消息都将经过BT(如果启用)。BT维护一组FIFO,以对等待进入HT的请求进行排序,使得当最老的等待请求变为可用时,HT条目分配给最老的等待请求。它还具有Home Agent数据缓冲区(一组用于在环和内存控制器之间传输数据的数据缓冲区。它有128个条目,每个Home Tracker一个)。HA需要从地址中解码适当的DRAM通道。这个过程称为“目标地址解码”。每个HA的TAD规则可以通过CSRs进行配置;规则由要匹配的内存范围和交错模式组成,即截断地址的
addr[8:6]用于索引到DRAM通道列表中。因为TAD包含要匹配的地址范围,所以允许对I/O解码器窃取的范围进行内存回收:将SAD DRAM解码器配置为解码特定的回收范围,并在TAD条目中进行配置(工作站CPU使用TOLUD和REMAPBASE等;设置这些寄存器将更改从中读取的Cbo解码器)。解码目标通道后,请求将转发到相应的BGF(泡生成器FIFO)。在读取时,数据将从iMC返回并转发到HADB。在写入时,数据将从环下载到HADB并转发到iMC。服务器处理器上的iMC连接到每个插槽的2个SMI2端口,用于具有通常12个DIMM和可扩展内存缓冲区(例如Jordan Creek)的升级卡。HA将数据发送回请求的CBo ID + NodeID。
无匹配
如果地址不匹配任何范围,或匹配了一个地址空洞(不存在的内存属性),则目标默认为套接字的Ubox,并将消息编码为具有零长度或所有零字节启用的NcRdPtl或NcWrPtl操作码。 Ubox将此消息视为错误;可以配置错误以返回错误响应或正常完成(对于读取或防止写入的数据更新返回全1数据),带或不带MCA。此机制用于在某些初始化序列期间防止任何非法访问被路由到外部。除非访问是带有写回(WB)内存属性的存储访问,否则7500系列缓存代理将不会对标记为“不存在的内存”(NXM)的SAD地址区域进行MCA。
经典PCIe交换机图表上的
总线编号是非常错误的。我的GPU实际上在总线1上(因为它在一个PCIe端口上)。看来集成的PCIe交换机对软件是不可见的,端口只出现在总线0上作为单个PCIe控制器/PCI到PCI桥接器,并且连接到点对点端口的设备出现在一个新的总线号上(总线2上的以太网控制器和总线3上的无线局域网控制器)。
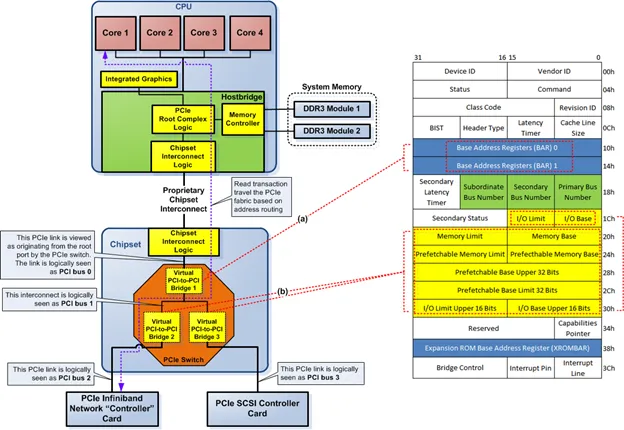
实际上,PCI-to-PCI桥1无法存在,因为它需要一个不在我的系统上的从属总线。要么它在我的系统上不存在,要么就像这样有2个集成的PCI-to-PCI桥:
或者它确实存在,但对程序员不可见的寄存器会根据下级PCI-to-PCI桥的内容发生变化,下级总线号必须为0(而不是图中的1)(这不会通过具有相同总线号的2个总线来搞乱路由,因为另一侧的接口不是总线0,而是直接连接到PCH逻辑,因此交易将始终显示为从PCI-to-PCI桥1发起,就像它是没有其他东西的根复杂)。该图呈现了一个非常误导性的PCH;PCIe接口并不像那样纯净,并且在必要时由芯片组分解和接口化(所有集成的PCH桥和控制器作为独立的点对点PCIe设备位于端口上太昂贵了)。
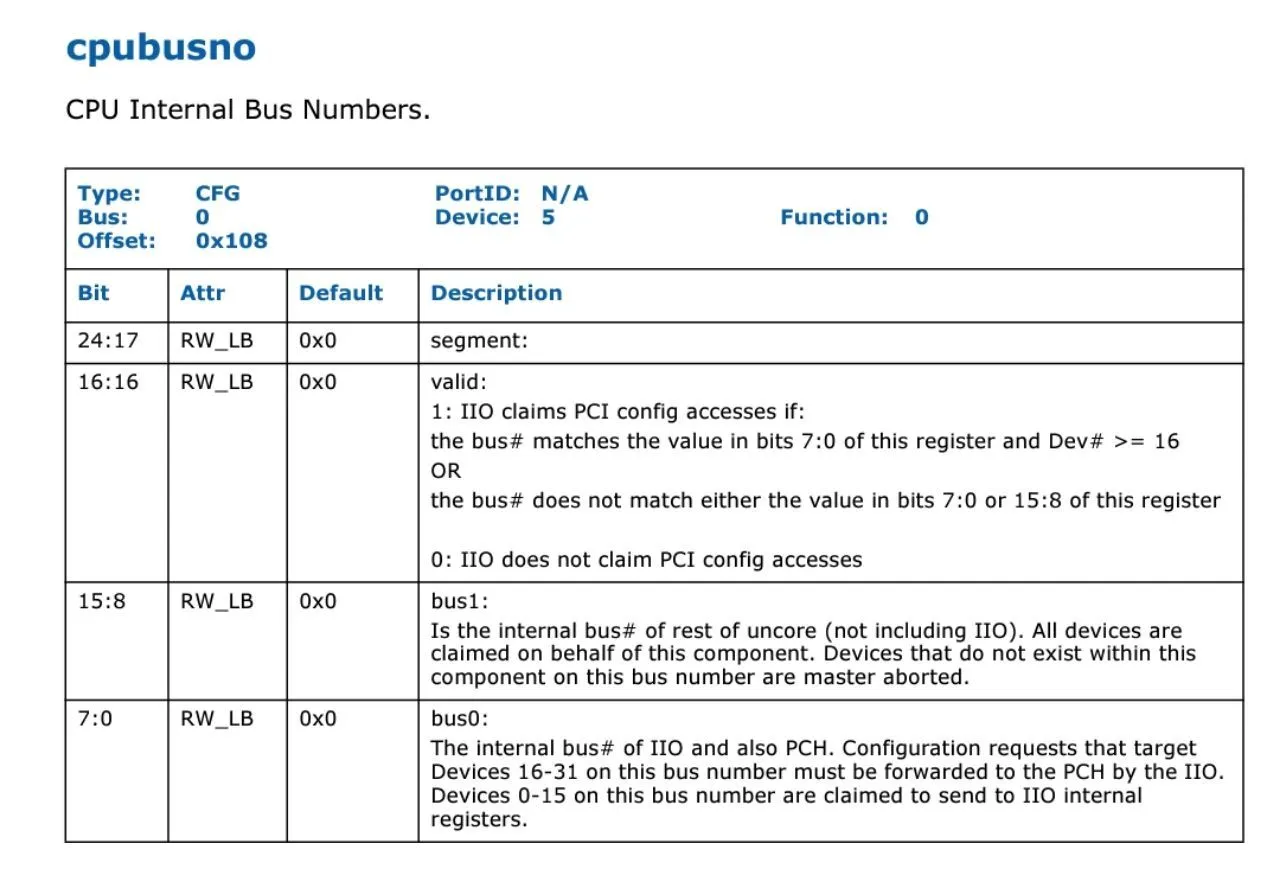
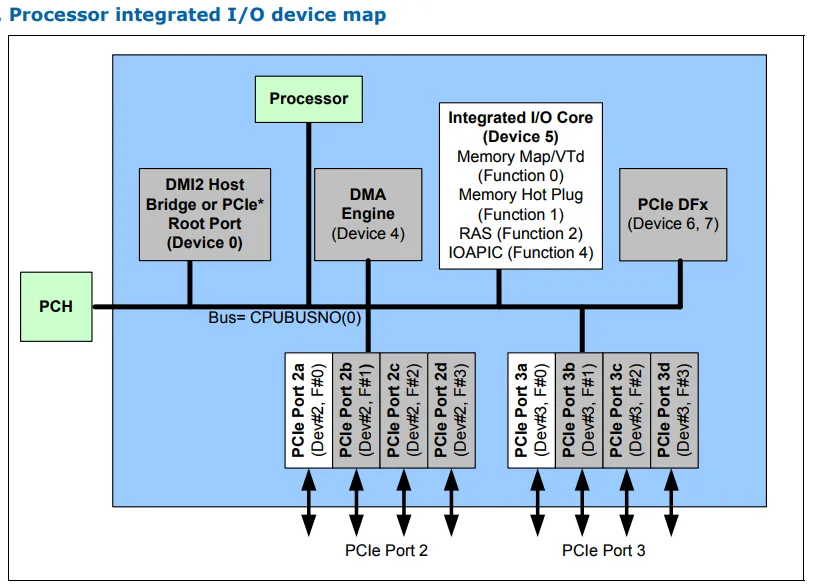
CPU和PCH作为单个物理PCIe设备与逻辑子设备一起运行。 Ubox拦截NcCfgRd / NcCfgWr。 IIO + PCH(CPUBUSNO(0))设备实际上可以具有与核心(CPUBUSNO(1))不同的总线号。如果总线号为CPUBUSNO(1),或者CPUBUSNO(0)但设备编号低于特定设备编号,则它将直接处理请求。如果它在CPUBUSNO(0)上并且设备编号高于特定设备编号,则将路由Type 0配置TLP到DMI接口,在那里除逻辑PCI桥之外的任何设备都会响应其功能/设备编号(它的下级号码就像是该总线号一样的逻辑桥,尽管在同一条总线上)。如果总线号>CPUBUSNO(0),则它会在DMI上生成Type 1 Configuration TLP,并被具有该从属总线号的逻辑桥吸收。