目标是在不重复任何点的情况下将10米内的点平均在一起,将点数据框减少到平均点,并理想地沿着收集这些点的路线获得点的平滑流动。 这是一个来自较大文件(25,000次观察)的11点子集示例数据框:
library(sf)
df <- data.frame(trait = as.numeric(c(91.22,91.22,91.22,91.58,91.47,92.19,92.19,90.57,90.57,91.65,91.65)),
datetime = as.POSIXct(c("2021-08-06 15:08:43","2021-08-06 15:08:44","2021-08-06 15:08:46","2021-08-06 15:08:47","2021-08-06 15:43:17","2021-08-06 15:43:18","2021-08-06 15:43:19","2021-08-06 15:43:20","2021-08-06 15:43:21","2021-08-06 15:43:22","2021-08-06 15:43:23")),
lat = c(39.09253, 39.09262, 39.09281, 39.09291, 39.09248, 39.09255, 39.09261, 39.09266, 39.0927, 39.09273, 39.09274),
lon = c(-94.58463, -94.58462, -94.5846, -94.58459, -94.58464, -94.58464, -94.58464, -94.58464, -94.58466, -94.5847, -94.58476)
) # just to add some value that is plotable
projcrs <- "+proj=longlat +datum=WGS84 +no_defs +ellps=WGS84 +towgs84=0,0,0"
df <- st_as_sf(x = df,
coords = c("lon", "lat"),
crs = projcrs)
这是我尝试过的:
- 多次尝试使用
st_is_within_distance(trav, trav, tolerance),包括: - 所展示的聚合方法。这些方法不起作用,因为同一点被多次平均。
- 通过尝试在
lapply中动态更新列表来使用filter和across,但最终没有成功。 - Jeffreyevans提供的这个帖子对我很有帮助,但并没有真正解决问题,而且有点过时了。
spThin包不起作用,因为它是针对更特定的变量设计的。- 我想使用这个帖子进行聚类,但是聚类会产生随机点,实际上不能有效地减小数据框。
下面是我接近解决问题的方法。这种解决方法的问题在于在收集平均值时重复了点,这样会给某些点带来更多的权重。
# first set tolerance
tolerance <- 20 # 20 meters
# get distance between points
i <- st_is_within_distance(df, df, tolerance)
# filter for indices with more than 1 (self) neighbor
i <- i[which(lengths(i) > 1)]
# filter for unique indices (point 1, 2 / point 2, 1)
i <- i[!duplicated(i)]
# points in `sf` object that have no neighbors within tolerance
no_neighbors <- trav[!(1:nrow(df) %in% unlist(i)), ]
# iterate over indices of neighboring points
avg_points <- lapply(i, function(b){
df <- df[unlist(b), ]
coords <- st_coordinates(df)
df <- df %>%
st_drop_geometry() %>%
cbind(., coords)
df_sum <- df %>%
summarise(
datetime = first(datetime),
trait = mean(trait),
X = mean(X),
Y = mean(Y),
.groups = 'drop') %>%
ungroup()
return(df)
}) %>%
bind_rows() %>%
st_as_sf(coords = c('X', 'Y'),
crs = "+proj=longlat +datum=WGS84 +no_defs ")


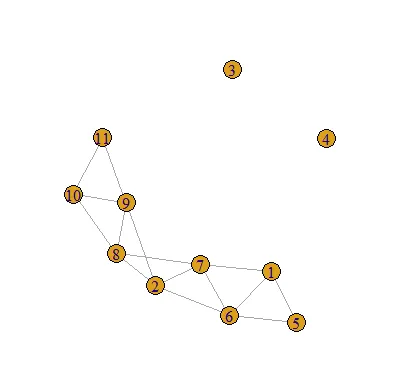
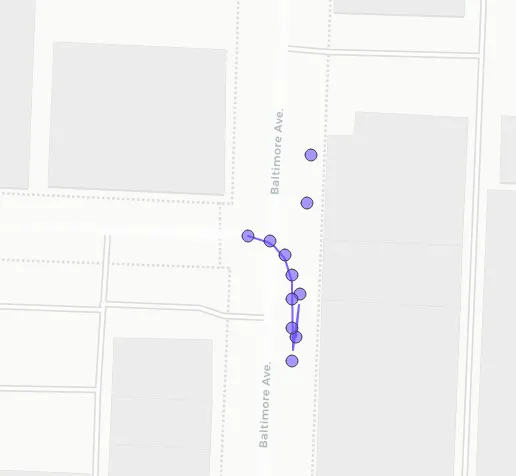
trait进行空间平均。我认为在summarise函数中将datetime变量设置为first是一种不错的方式,可以在不将其作为主要问题焦点的情况下进行包含。 - estebangatillo1 2 5 6 7 8 9和1 2 5 6 7 8 9 10 11,这是否意味着对于第一个点,我们按照给定的平均值进行计算,但对于第二个点,仅在10和11之间(唯一尚未使用的索引)进行计算?如果是这种情况,那么对于没有剩余邻居的点会发生什么情况(甚至该点本身可能已经被包含在其他地方)? - thothal