我创建了一个 AWS Firehose 端点(可能会变成简单的 Kinesis),用于接收生产者发送的日志并将其保存到 S3 存储桶和消费数据的 Lambda 函数,处理后将输出保存到数据库中。
一切运作正常。现在我正在计划为整个结构创建一个分阶段和开发流程。当我发布新版本时,我无法立即替换全部生产者,因此需要保留旧版本,直到没有生产者使用旧版本。因为我可能会对新版本进行重大协议更改。
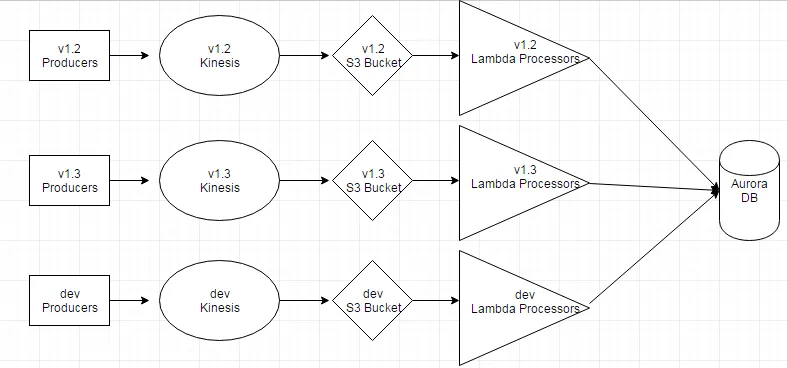
我不确定使用 kinesis 和 lambda 创建可版本化系统的最佳方法是什么。我应该复制整个结构以支持新版本(包括开发和分段),并使生产者写入特定版本的流吗?
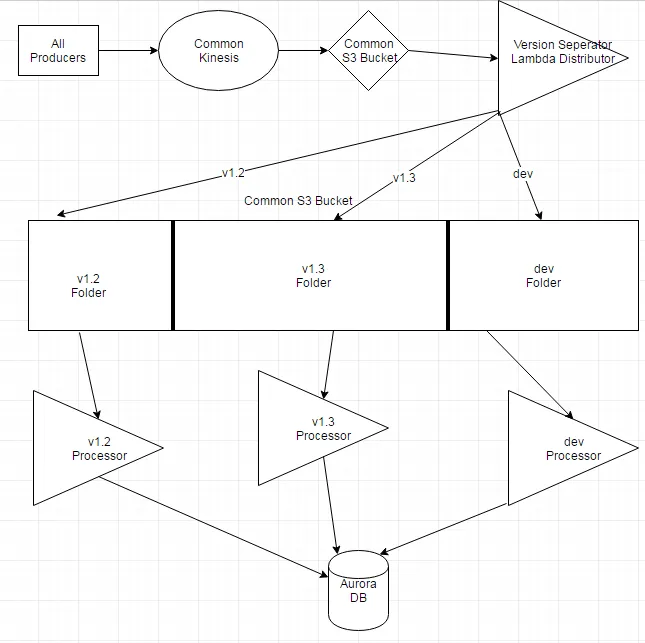
还是应该创建一个中间 Lambda 函数来检查数据包(其中包含版本信息),并将事件输出到具有版本化文件夹的特定 S3 中?这样,Lambda 函数将仅消费它们了解的数据。这将让我使用 Lambda 函数的版本控制支持。
这是第一个想法的结构图。
一切运作正常。现在我正在计划为整个结构创建一个分阶段和开发流程。当我发布新版本时,我无法立即替换全部生产者,因此需要保留旧版本,直到没有生产者使用旧版本。因为我可能会对新版本进行重大协议更改。
我不确定使用 kinesis 和 lambda 创建可版本化系统的最佳方法是什么。我应该复制整个结构以支持新版本(包括开发和分段),并使生产者写入特定版本的流吗?
还是应该创建一个中间 Lambda 函数来检查数据包(其中包含版本信息),并将事件输出到具有版本化文件夹的特定 S3 中?这样,Lambda 函数将仅消费它们了解的数据。这将让我使用 Lambda 函数的版本控制支持。
这是第一个想法的结构图。