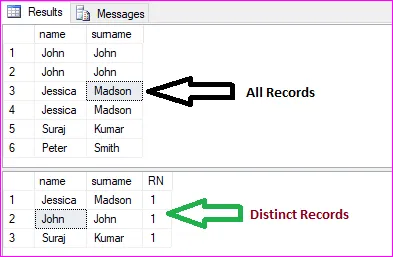
I have a table that looks like this:
name | surname
------------------
John | John
Jessica | Madson
我有一个类似这样的查询:
SELECT *
FROM TABLE
WHERE name LIKE '%j%'
OR surname LIKE '%j%'
What I get:
John John
John John
Jessica Madson
我需要的是:
John John
Jessica Madson
如何去除重复结果?