你可以通过检查执行计划来确定,这两种方法没有区别。如果id是聚集索引,你会看到有序的聚集索引扫描;如果没有索引,你仍然会看到表扫描或聚集索引扫描,但无论哪种情况都不会有顺序。
如果你想从行中提取其他值,TOP 1的方法可能很有用,这比在子查询中提取最大值然后连接更容易。如果您需要从行中获得其他值,则需要在两种情况下确定如何处理并列的情况。
尽管如此,在某些情况下,计划可能会有所不同,因此根据列是否具有索引以及是否单调递增而进行测试非常重要。我创建了一个简单的表,并插入了50000行:
CREATE TABLE dbo.x
(
a INT, b INT, c INT, d INT,
e DATETIME, f DATETIME, g DATETIME, h DATETIME
);
CREATE UNIQUE CLUSTERED INDEX a ON dbo.x(a);
CREATE INDEX b ON dbo.x(b)
CREATE INDEX e ON dbo.x(e);
CREATE INDEX f ON dbo.x(f);
INSERT dbo.x(a, b, c, d, e, f, g, h)
SELECT
n.rn,
n.a,
n.rn,
n.a,
DATEADD(DAY, n.rn/100, '20100101'),
DATEADD(DAY, -n.a % 1000, '20120101'),
DATEADD(DAY, n.rn/100, '20100101'),
DATEADD(DAY, -n.a % 1000, '20120101')
FROM
(
SELECT TOP (50000)
(ABS(s1.[object_id]) % 10000) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS n(a,rn);
GO
在我的系统上,这将创建从1到50000的a/c值,3到9994之间的b/d值,以及从2010-01-01到2011-05-16的e/g值和从2009-04-28到2012-01-01的f/h值。
首先,让我们比较索引的单调递增整数列a和c。a具有聚集索引,而c没有:
SELECT MAX(a) FROM dbo.x;
SELECT TOP (1) a FROM dbo.x ORDER BY a DESC;
SELECT MAX(c) FROM dbo.x;
SELECT TOP (1) c FROM dbo.x ORDER BY c DESC;
结果:

第4个查询的主要问题是,与MAX不同,它需要排序。这里是3和4的比较:
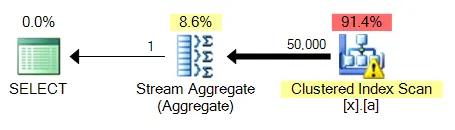
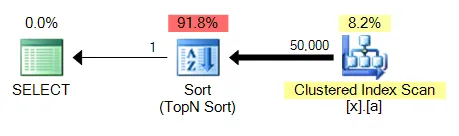
所有这些查询变体都会遇到一个常见问题:对未索引列的MAX将能够利用聚集索引扫描并执行流式聚合,而TOP 1需要执行更昂贵的排序操作。
我进行了测试,并在测试b + d、e + g和f + h时看到了完全相同的结果。
因此,在我看来,除了产生更多符合标准的代码外,根据底层表格和索引(在将代码投入生产后可能会发生变化),使用MAX而不是TOP 1可能会带来潜在的性能优势。因此,如果没有其他信息,我会说MAX更可取。
(正如我之前所说的,如果你拉取额外的列,TOP 1可能真的是你想要的行为。如果你真的需要这个结果,你还需要测试MAX+JOIN方法。)
id是自增的,那么这个问题是https://dev59.com/A3RB5IYBdhLWcg3wj32c的重复。 - Ben