有一些工具和API可以完成这个任务。例如,一个非常好用的工具是SmartyStreets的LiveAddress。我参与了它的开发,所以我能理解你的痛苦... 这是你在问题中提供的样例输出:
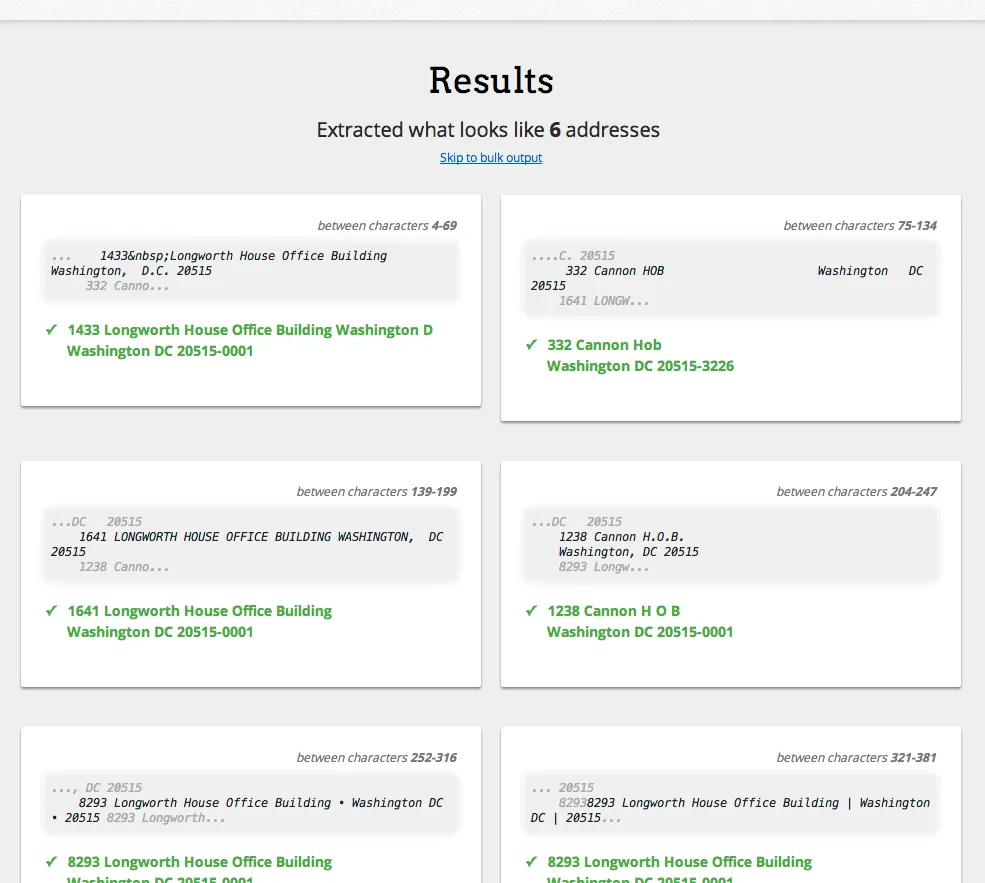
这是CSV输出:
ID,Start,End,Segment,Verified,Candidate,Firm,FirstLine,SecondLine,LastLine,City,State,ZIPCode,County,DpvFootnotes,DeliveryPointBarcode,Active,Vacant,CMRA,MatchCode,Latitude,Longitude,Precision,RDI,RecordType,BuildingDefaultIndicator,CongressionalDistrict,Footnotes
1,4,69,"1433 Longworth House Office Building Washington, D.C. 20515",Y,0,,1433 Longworth House Office Building Washington D,,Washington DC 20515-0001,Washington,DC,20515,District of Columbia,AAU1,205150001330,,,,Y,38.89106,-77.01132,Zip5,Residential,S,,AL,Q#X#
2,75,134,332 Cannon HOB Washington DC 20515,Y,0,,332 Cannon Hob,,Washington DC 20515-3226,Washington,DC,20515,District of Columbia,AAU1,205153226996,,,,Y,38.89106,-77.01132,Zip5,Residential,H,Y,AL,H#Q#
3,139,199,"1641 LONGWORTH HOUSE OFFICE BUILDING WASHINGTON, DC 20515",Y,0,,1641 Longworth House Office Building,,Washington DC 20515-0001,Washington,DC,20515,District of Columbia,AAU1,205150001411,,,,Y,38.89106,-77.01132,Zip5,Residential,S,,AL,Q#X#
4,204,247,"1238 Cannon H.O.B.
Washington, DC 20515",Y,0,,1238 Cannon H O B,,Washington DC 20515-0001,Washington,DC,20515,District of Columbia,AAU1,205150001385,,,,Y,38.89106,-77.01132,Zip5,Residential,S,,AL,Q#X#
5,252,316,8293 Longworth House Office Building • Washington DC • 20515,Y,0,,8293 Longworth House Office Building,,Washington DC 20515-0001,Washington,DC,20515,District of Columbia,AAU1,205150001934,,,,Y,38.89106,-77.01132,Zip5,Residential,S,,AL,Q#X#
6,321,381,8293 Longworth House Office Building | Washington DC | 20515,Y,0,,8293 Longworth House Office Building,,Washington DC 20515-0001,Washington,DC,20515,District of Columbia,AAU1,205150001934,,,,Y,38.89106,-77.01132,Zip5,Residential,S,,AL,Q#X#
大约需要2秒钟。这个API在一定程度上是免费的,可能还有其他类似的选择;我鼓励您四处寻找最适合您的选项......我保证它会比编写自己的正则表达式好(提示:这个代码背后不是基于正则表达式的)。