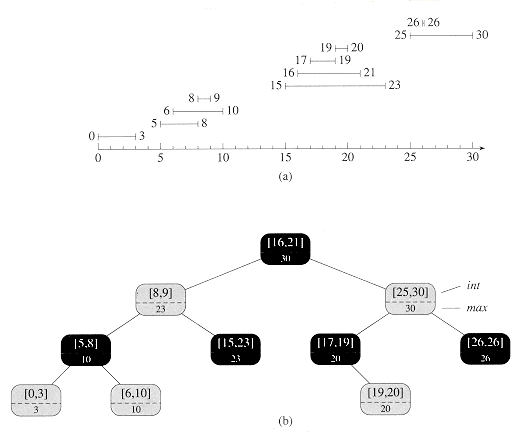
我有一个巨大的数据库表,其中包含n个整数区间(例如{1-5},{4-16},{6434-114343}),需要找出哪些区间彼此重叠。在stackoverflow上有大量类似的问题,但不同之处在于我需要分别返回每个区间重叠的区间集合。
------------------ A -------------------
------ B ------- ----- D -----
--------- C ---------
对于这个例子,输出将是
A:{B,C,D} B:{A,C} C:{A,B} D:{A}
最坏情况下,所有区间可能彼此重叠,产生大小为O(n2)的输出。这与朴素解决方案(比较每对区间)无异。然而,在实践中,我知道我的区间很少会与其他区间重叠,当它们重叠时,也只有最多5个其他区间。在这种情况下,我应该如何解决这个问题?(理想情况下,我希望使用SQL查询解决方案,因为数据存储在数据库中,但我认为只有常规算法解决方案才是可能的。)