例如,我有100张分辨率相同的图片,我想将它们合并成一张图片。 对于最终的图片,每个像素的RGB值是该位置100张图片的平均值。 我知道在这种情况下
getdata函数可以工作,但是否有更简单,更快速的方法在PIL(Python图像库)中实现这一点?getdata函数可以工作,但是否有更简单,更快速的方法在PIL(Python图像库)中实现这一点?假设你的所有图像都是 .png 文件,并且它们都存储在当前工作目录中。下面的 Python 代码会完成你想要的事情。正如Ignacio所建议的那样,在这里使用numpy和PIL是关键。当构建平均像素强度时,你只需要小心在整数数组和浮点数数组之间切换。
import os, numpy, PIL
from PIL import Image
# Access all PNG files in directory
allfiles=os.listdir(os.getcwd())
imlist=[filename for filename in allfiles if filename[-4:] in [".png",".PNG"]]
# Assuming all images are the same size, get dimensions of first image
w,h=Image.open(imlist[0]).size
N=len(imlist)
# Create a numpy array of floats to store the average (assume RGB images)
arr=numpy.zeros((h,w,3),numpy.float)
# Build up average pixel intensities, casting each image as an array of floats
for im in imlist:
imarr=numpy.array(Image.open(im),dtype=numpy.float)
arr=arr+imarr/N
# Round values in array and cast as 8-bit integer
arr=numpy.array(numpy.round(arr),dtype=numpy.uint8)
# Generate, save and preview final image
out=Image.fromarray(arr,mode="RGB")
out.save("Average.png")
out.show()
上面的图像是使用上述代码从一系列高清视频帧生成的。
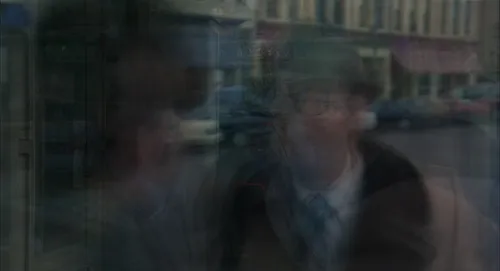
我觉得很难想象在这里会出现内存问题,但是如果你绝对不能够负担起创建所需的浮点数数组(参见原回答),你可以使用PIL的混合函数,如@mHurley建议的那样(点击查看):
# Alternative method using PIL blend function
avg=Image.open(imlist[0])
for i in xrange(1,N):
img=Image.open(imlist[i])
avg=Image.blend(avg,img,1.0/float(i+1))
avg.save("Blend.png")
avg.show()
out = image1 * (1.0 - alpha) + image2 * alpha


可以使用numpy的平均函数进行平均。代码看起来更好,运行速度更快。
这里是对700张嘈杂的灰度人脸图像进行计时和结果比较:
def average_img_1(imlist):
# Assuming all images are the same size, get dimensions of first image
w,h=Image.open(imlist[0]).size
N=len(imlist)
# Create a numpy array of floats to store the average (assume RGB images)
arr=np.zeros((h,w),np.float)
# Build up average pixel intensities, casting each image as an array of floats
for im in imlist:
imarr=np.array(Image.open(im),dtype=np.float)
arr=arr+imarr/N
out = Image.fromarray(arr)
return out
def average_img_2(imlist):
# Alternative method using PIL blend function
N = len(imlist)
avg=Image.open(imlist[0])
for i in xrange(1,N):
img=Image.open(imlist[i])
avg=Image.blend(avg,img,1.0/float(i+1))
return avg
def average_img_3(imlist):
# Alternative method using numpy mean function
images = np.array([np.array(Image.open(fname)) for fname in imlist])
arr = np.array(np.mean(images, axis=(0)), dtype=np.uint8)
out = Image.fromarray(arr)
return out
average_img_1()
100 loops, best of 3: 362 ms per loop
average_img_2()
100 loops, best of 3: 340 ms per loop
average_img_3()
100 loops, best of 3: 311 ms per loop
顺便说一下,取平均值的结果相当不同。我认为第一种方法在取平均值时丢失了信息。而第二种方法则有一些人工制品。
average_img_1
平均图像_2

平均图像_3

如果有人对numpy的蓝图解决方案感兴趣(我实际上正在寻找这个),这里是代码:
mean_frame = np.mean(([frame for frame in frames]), axis=0)
我建议创建一个x乘y的整数数组,从(0, 0, 0)开始,然后对于每个文件中的每个像素,将RGB值添加到数组中,除以图像数量,然后从其中创建图像 - 您可能会发现numpy很有帮助。
N=len(images_to_blend)
avg = Image.open(images_to_blend[0])
for im in images_to_blend: #assuming your list is filenames, not images
img = Image.open(im)
avg = Image.blend(avg, img, 1/N)
avg.save(blah)