Content-disposition头包含文件名,该文件名可以轻松提取,但有时会包含双引号,有时没有引号,可能还有其他变体。 有人能否编写一个正则表达式,以在所有情况下都起作用。
Content-Disposition: attachment; filename=content.txt
以下是可能的目标字符串:
attachment; filename=content.txt
attachment; filename*=UTF-8''filename.txt
attachment; filename="EURO rates"; filename*=utf-8''%e2%82%ac%20rates
attachment; filename="omáèka.jpg"
and some other combinations might also be there

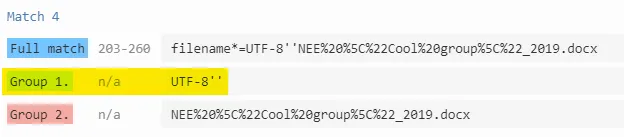
/filename[^;=\n]*=((['"]).*?\2|[^;\n]*)/.exec(contentDisposition)[1]的翻译是:在contentDisposition字符串中匹配以"filename"开头且不包含等号和分号的部分,该部分的取值可以由单引号、双引号或无引号的任意字符组成。返回匹配结果的第一个捕获组。 - jsgoupil