我模糊地记得tries不会在每个节点上存储整个数据,只会存储到父节点的后缀。
而树是会存储整个数据的,但只基于前缀来组织节点。
所以,tries可以变得更小,这允许例如对字典进行很好的压缩。
这真的是唯一的区别吗?
从实际应用中,我记得tries在范围查询方面更快。甚至有专门针对范围查询加速的solr/lucene trie字段。但是这是为什么呢?
tries和树的实际区别及其优缺点是什么?

二叉树或bst通常用于存储数字值。在bst中,插入、删除和搜索的时间复杂度为O(log(n))。二叉树中的每个节点最多有两个子节点。
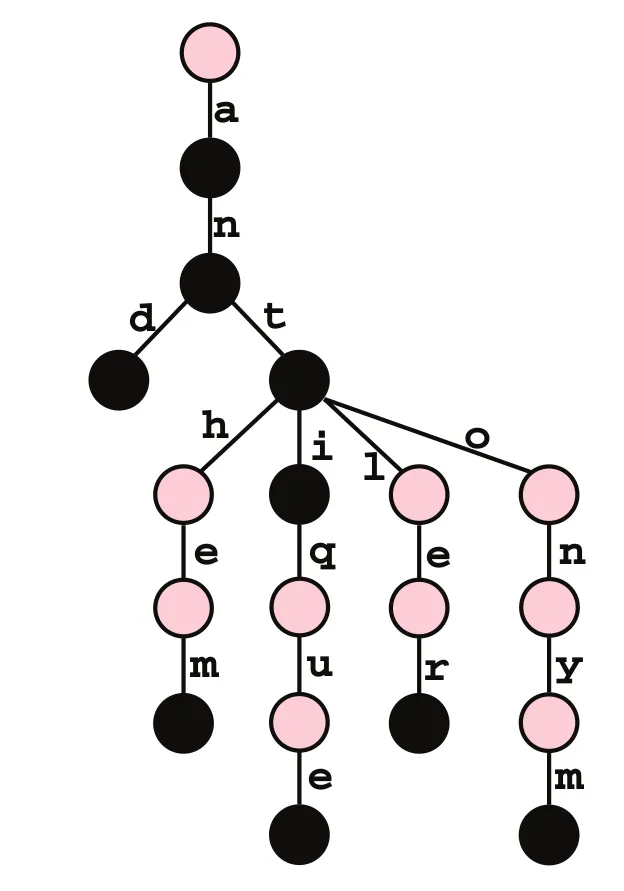
Trie:trie的每个节点都包含多个分支。每个分支表示一个可能的键字符。我们需要将每个键的最后一个节点标记为叶节点。trie节点字段值将用于区分节点作为叶子节点(还有其他用途)。
要了解更多关于tries的内容,请参考这篇topcoder教程。 https://www.topcoder.com/community/data-science/data-science-tutorials/using-tries/
O(m),而在树中查找是根据节点数和字符串长度为O(m * log n),因为比较两个字符串最坏情况下需要花费O(m)的时间,而你需要进行最坏情况下O(log n)次比较。而Trie只需进行一次O(1)字符比较。 - semicolonO(1)的,因为您正在比较值的常量大小子部分,而在树中它们是O(m)。 - semicolonO(m) = O(1)。 - undefined