编辑:我通过这篇文章获得了足够的声望,可以编辑它并添加更多链接,这将有助于更好地阐述我的观点。
玩《以撒的结合》的人经常在小基座上找到重要物品。
目标是让用户能够按下一个按钮,指示他“框定”该物品(类似于 Windows 桌面的选框)。此框会提供我们所关注的区域(实际物品及其一些背景环境)以与整个网格中的物品进行比较。
理论上的用户框出的物品

理论上的物品网格(没有更多了,我只是从维基百科中摘取了这个)

在网格中被确定为用户框选的物品的位置将表示与正确链接相关的图像上的某个区域,该链接可提供关于该物品的信息。
在网格中,该物品位于第一列、底部第三行。我在下面尝试的所有内容中都使用了这两个图像
我的目标是创建一个程序,可以从游戏《以撒的结合》中手动裁剪出一个物品,通过将图像与游戏中物品表的图像进行比较来识别裁剪出的物品,然后显示正确的维基页面。
从库的角度来看,这将是我的第一个“真正的项目”,因为它需要学习大量的库才能完成我想要的工作。让我有一些不知所措。
我已经尝试了一些选项,仅仅是从谷歌上搜索到的(你可以通过搜索方法名称和 opencv 快速找到我使用的教程,我的帐户由于某种原因严重受限于链接发布)。
使用 bruteforcematcher:
http://docs.opencv.org/doc/tutorials/features2d/feature_description/feature_description.html
#include <stdio.h>
#include <iostream>
#include "opencv2/core/core.hpp"
#include <opencv2/legacy/legacy.hpp>
#include <opencv2/nonfree/features2d.hpp>
#include "opencv2/highgui/highgui.hpp"
using namespace cv;
void readme();
/** @function main */
int main( int argc, char** argv )
{
if( argc != 3 )
{ return -1; }
Mat img_1 = imread( argv[1], CV_LOAD_IMAGE_GRAYSCALE );
Mat img_2 = imread( argv[2], CV_LOAD_IMAGE_GRAYSCALE );
if( !img_1.data || !img_2.data )
{ return -1; }
//-- Step 1: Detect the keypoints using SURF Detector
int minHessian = 400;
SurfFeatureDetector detector( minHessian );
std::vector<KeyPoint> keypoints_1, keypoints_2;
detector.detect( img_1, keypoints_1 );
detector.detect( img_2, keypoints_2 );
//-- Step 2: Calculate descriptors (feature vectors)
SurfDescriptorExtractor extractor;
Mat descriptors_1, descriptors_2;
extractor.compute( img_1, keypoints_1, descriptors_1 );
extractor.compute( img_2, keypoints_2, descriptors_2 );
//-- Step 3: Matching descriptor vectors with a brute force matcher
BruteForceMatcher< L2<float> > matcher;
std::vector< DMatch > matches;
matcher.match( descriptors_1, descriptors_2, matches );
//-- Draw matches
Mat img_matches;
drawMatches( img_1, keypoints_1, img_2, keypoints_2, matches, img_matches );
//-- Show detected matches
imshow("Matches", img_matches );
waitKey(0);
return 0;
}
/** @function readme */
void readme()
{ std::cout << " Usage: ./SURF_descriptor <img1> <img2>" << std::endl; }

使用flann可以得到更干净但同样不可靠的结果。
http://docs.opencv.org/doc/tutorials/features2d/feature_flann_matcher/feature_flann_matcher.html
#include <stdio.h>
#include <iostream>
#include "opencv2/core/core.hpp"
#include <opencv2/legacy/legacy.hpp>
#include <opencv2/nonfree/features2d.hpp>
#include "opencv2/highgui/highgui.hpp"
using namespace cv;
void readme();
/** @function main */
int main( int argc, char** argv )
{
if( argc != 3 )
{ readme(); return -1; }
Mat img_1 = imread( argv[1], CV_LOAD_IMAGE_GRAYSCALE );
Mat img_2 = imread( argv[2], CV_LOAD_IMAGE_GRAYSCALE );
if( !img_1.data || !img_2.data )
{ std::cout<< " --(!) Error reading images " << std::endl; return -1; }
//-- Step 1: Detect the keypoints using SURF Detector
int minHessian = 400;
SurfFeatureDetector detector( minHessian );
std::vector<KeyPoint> keypoints_1, keypoints_2;
detector.detect( img_1, keypoints_1 );
detector.detect( img_2, keypoints_2 );
//-- Step 2: Calculate descriptors (feature vectors)
SurfDescriptorExtractor extractor;
Mat descriptors_1, descriptors_2;
extractor.compute( img_1, keypoints_1, descriptors_1 );
extractor.compute( img_2, keypoints_2, descriptors_2 );
//-- Step 3: Matching descriptor vectors using FLANN matcher
FlannBasedMatcher matcher;
std::vector< DMatch > matches;
matcher.match( descriptors_1, descriptors_2, matches );
double max_dist = 0; double min_dist = 100;
//-- Quick calculation of max and min distances between keypoints
for( int i = 0; i < descriptors_1.rows; i++ )
{ double dist = matches[i].distance;
if( dist < min_dist ) min_dist = dist;
if( dist > max_dist ) max_dist = dist;
}
printf("-- Max dist : %f \n", max_dist );
printf("-- Min dist : %f \n", min_dist );
//-- Draw only "good" matches (i.e. whose distance is less than 2*min_dist )
//-- PS.- radiusMatch can also be used here.
std::vector< DMatch > good_matches;
for( int i = 0; i < descriptors_1.rows; i++ )
{ if( matches[i].distance < 2*min_dist )
{ good_matches.push_back( matches[i]); }
}
//-- Draw only "good" matches
Mat img_matches;
drawMatches( img_1, keypoints_1, img_2, keypoints_2,
good_matches, img_matches, Scalar::all(-1), Scalar::all(-1),
vector<char>(), DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS );
//-- Show detected matches
imshow( "Good Matches", img_matches );
for( int i = 0; i < good_matches.size(); i++ )
{ printf( "-- Good Match [%d] Keypoint 1: %d -- Keypoint 2: %d \n", i, good_matches[i].queryIdx, good_matches[i].trainIdx ); }
waitKey(0);
return 0;
}
/** @function readme */
void readme()
{ std::cout << " Usage: ./SURF_FlannMatcher <img1> <img2>" << std::endl; }

目前为止,模板匹配是我最好的方法。虽然在6种方法中,只能正确识别0-4项。
http://docs.opencv.org/doc/tutorials/imgproc/histograms/template_matching/template_matching.html
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include <iostream>
#include <stdio.h>
using namespace std;
using namespace cv;
/// Global Variables
Mat img; Mat templ; Mat result;
char* image_window = "Source Image";
char* result_window = "Result window";
int match_method;
int max_Trackbar = 5;
/// Function Headers
void MatchingMethod( int, void* );
/** @function main */
int main( int argc, char** argv )
{
/// Load image and template
img = imread( argv[1], 1 );
templ = imread( argv[2], 1 );
/// Create windows
namedWindow( image_window, CV_WINDOW_AUTOSIZE );
namedWindow( result_window, CV_WINDOW_AUTOSIZE );
/// Create Trackbar
char* trackbar_label = "Method: \n 0: SQDIFF \n 1: SQDIFF NORMED \n 2: TM CCORR \n 3: TM CCORR NORMED \n 4: TM COEFF \n 5: TM COEFF NORMED";
createTrackbar( trackbar_label, image_window, &match_method, max_Trackbar, MatchingMethod );
MatchingMethod( 0, 0 );
waitKey(0);
return 0;
}
/**
* @function MatchingMethod
* @brief Trackbar callback
*/
void MatchingMethod( int, void* )
{
/// Source image to display
Mat img_display;
img.copyTo( img_display );
/// Create the result matrix
int result_cols = img.cols - templ.cols + 1;
int result_rows = img.rows - templ.rows + 1;
result.create( result_cols, result_rows, CV_32FC1 );
/// Do the Matching and Normalize
matchTemplate( img, templ, result, match_method );
normalize( result, result, 0, 1, NORM_MINMAX, -1, Mat() );
/// Localizing the best match with minMaxLoc
double minVal; double maxVal; Point minLoc; Point maxLoc;
Point matchLoc;
minMaxLoc( result, &minVal, &maxVal, &minLoc, &maxLoc, Mat() );
/// For SQDIFF and SQDIFF_NORMED, the best matches are lower values. For all the other methods, the higher the better
if( match_method == CV_TM_SQDIFF || match_method == CV_TM_SQDIFF_NORMED )
{ matchLoc = minLoc; }
else
{ matchLoc = maxLoc; }
/// Show me what you got
rectangle( img_display, matchLoc, Point( matchLoc.x + templ.cols , matchLoc.y + templ.rows ), Scalar::all(0), 2, 8, 0 );
rectangle( result, matchLoc, Point( matchLoc.x + templ.cols , matchLoc.y + templ.rows ), Scalar::all(0), 2, 8, 0 );
imshow( image_window, img_display );
imshow( result_window, result );
return;
}
http://imgur.com/pIRBPQM,h0wkqer,1JG0QY0,haLJzRF,CmrlTeL,DZuW73V#3
6个项目里面,有3个 fail 和 3个 pass。这个结果其实算是不错的,因为我尝试的第二个项目是 ,结果都是 fail。
,结果都是 fail。
每个图片处理方法都有优点和缺点。我想问一下,模板匹配是我最好的选择吗?还是有其他处理方法我没有考虑到的,能够让我事半功倍?
怎样才能让用户手动裁剪图片呢?opencv 的文档真的很差,而且我在网上找到的例子都是用 C++ 或者 C 写的,而且非常老旧。
感谢你们的帮助。这次尝试真的很有趣。其实我本来可以放更多链接来更好地描述我的问题,但是网站说我发布了超过10个链接,即使我没发那么多。
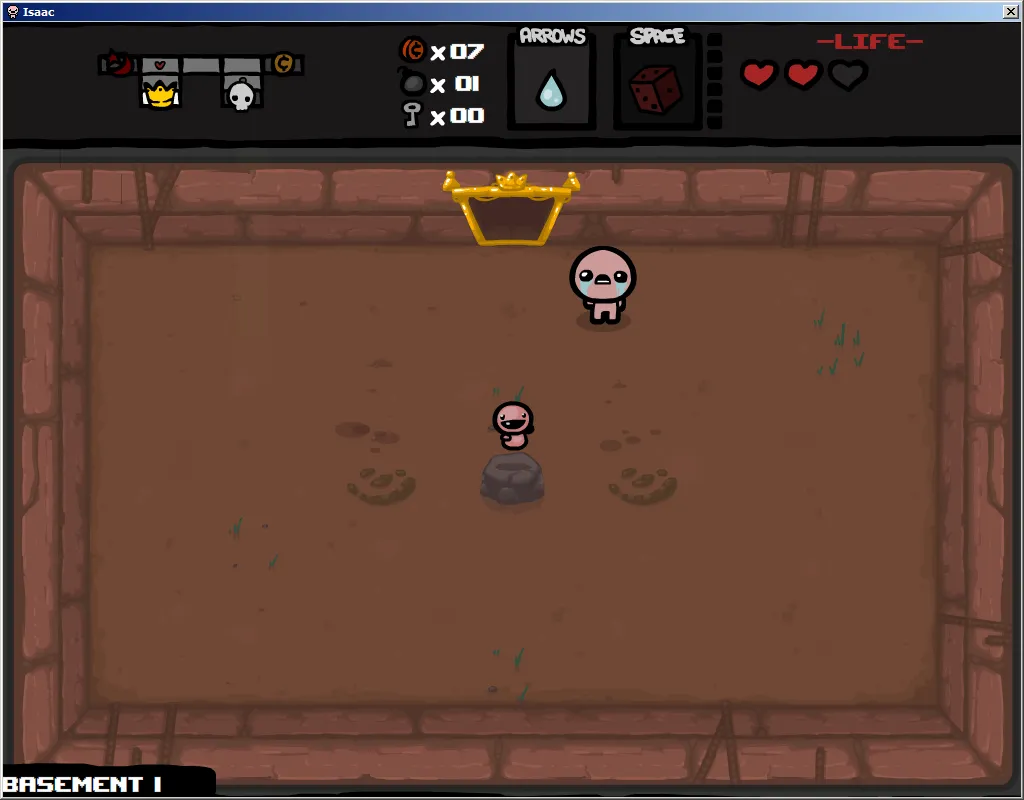
以下是游戏中的一些项目示例:
石头是一种稀有物品,可以出现在屏幕的任何位置。像石头这样的物品是最适合用户手动裁剪来隔离物品的,否则它们的位置只会出现在几个特定的地方。
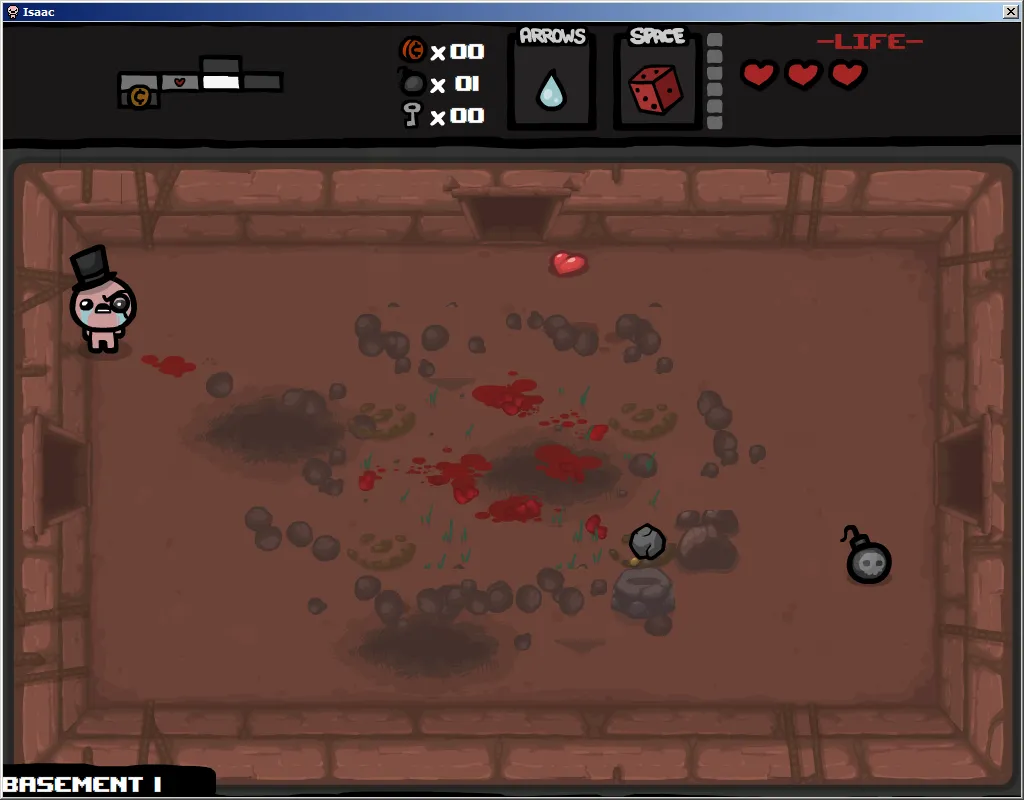

这是一次 boss 战后的房间,到处都是东西,中间还有透明部分。我想象这可能是处理得最困难的之一。
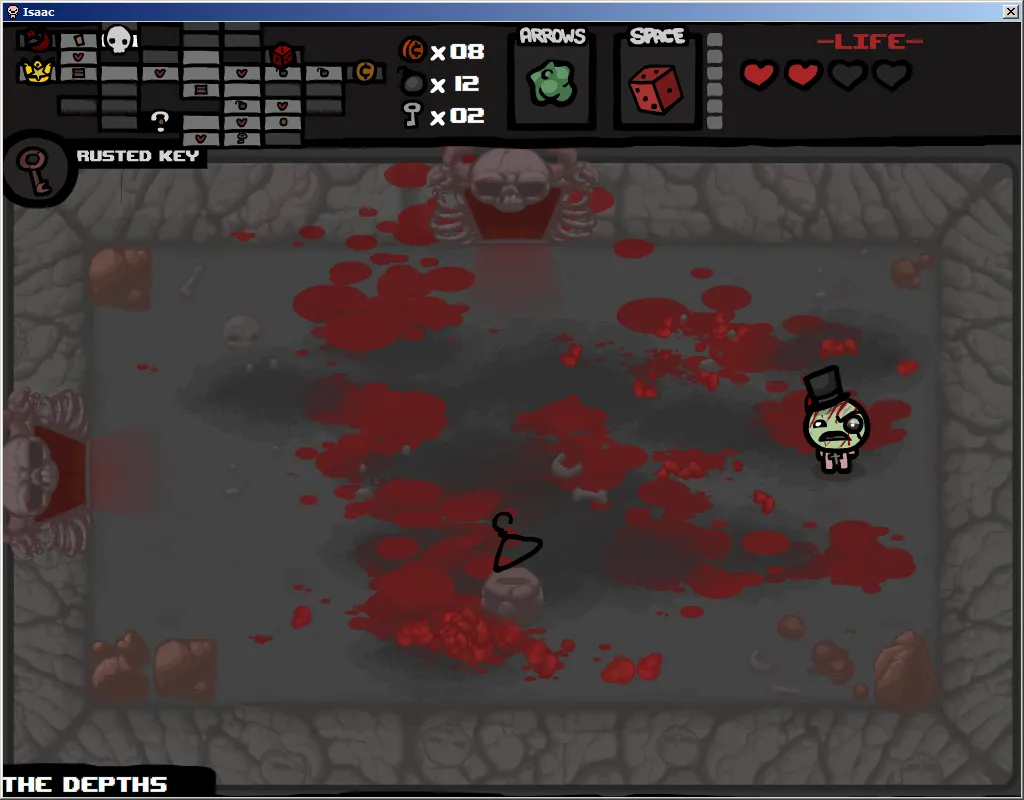

这是一间稀有房间,背景简单,没有物品的透明度。

这是游戏中所有物品的两张表格,我最终会把它们合成一张图片,但目前它们是直接从 isaac 维基上复制下来的。

