我曾多次为各种OCR项目与Tesseract奋斗过,今天我发现了一个使用案例,本以为这会是它的一大优势,但经过多个小时的尝试,仍然无法满足需求。我想在这里提出问题,看看是否有其他人能提供解决方案。
今天早上,我妻子问我是否有简便方法可以扫描她从沃尔玛收到的收据,并逐渐建立类别和特定物品的花费历史记录,以便我们可以进行趋势分析并轻松深入地了解支出去向。起初我觉得这是一个非常困难的任务,但经过一些调查,我发现了一些东西,让我觉得这是可以实现的:
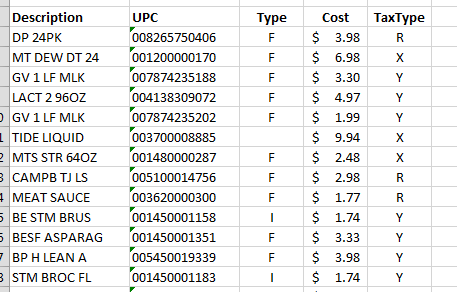
Wal-Mart的收据通常结构良好,易于阅读。它们甚至包括每个项目的UPC(潜在用于UPC数据库的查找?),并且似乎使用F或I对食品进行分类(不确定差异是什么),还有一个税收代码列,这可能会在我了解代码含义的秘密时证明有用。
我进一步发现,有某种Wal-Mart物品查找API,我可能可以获得访问权限,这将在UPC查找中证明有用。
他们为智能手机提供了一个应用程序,可以扫描每张收据上印刷的QR码。该应用程序会从其服务器上查找收据上的“TC”代码,并下载整个详细列表。它会向您显示收据的优秀图形表示,包括所有项目的缩略图和成本等。如果此应用程序只需对收据进行分类和汇总,那就太完美了!但遗憾的是,这不是该应用程序的目的...
谜题的最后一块是,您可以导出计算机生成的收据PNG图像,以便保存并丢弃纸质版本。对我而言,这是重点,因为这些PNG是由计算机创建的,因此不受拍照或扫描纸质收据的问题影响。
我自己最接近的例子是这个: 我使用了psm6和字符限制集,强制它只能使用大写字母、数字和少量符号:
乍一看,OCR似乎几乎匹配。但是当你深入挖掘时,你会发现它整体上失败得相当惨。3和8几乎总是错误的。5和6也是如此。然后有时它会完全跳过字符或开始崩溃(例如示例中的31+行)。它开始将2看作1,甚至会漏掉字符。第33行的SO PIZZA应该是“2.82”,但输出为“32”。
我已经尝试在图像上进行一些预处理,使字符更加粗细,确保它是纯黑色和白色,但我的所有努力都没有比来自沃尔玛的原始图像和上述命令更接近。
理想情况下,由于这是一个非常结构化的PNG文件,宽度可能始终相同,因此我希望能够通过像素宽度定义列,以便Tesseract将每个列视为独立的。我尝试过研究这个问题,但我看到的UZN文件对于像素宽度来说不太适用,而且它们似乎高度也是一个因素,这对于这些文件来说是不起作用的,因为高度始终会有所变化。
此外,我需要找出如何训练Tesseract以100%准确地识别数字(字母并不重要)。我开始研究如何训练程序,但说实话,由于文档中的培训范围更多地是为了使其识别整个语言而不仅仅是10个数字,因此很快就超出了我的能力范围。
最终的解决方案将是一个管道命令链,它从应用程序中获取原始PNG并将5列数据从收据的重要部分返回给我CSV。我不指望这个问题能够得到解决,但任何帮助引导我走向解决方案都将不胜感激!此时,我只是不想再次被Tesseract折磨,所以我决心找到掌握她的方法!
今天早上,我妻子问我是否有简便方法可以扫描她从沃尔玛收到的收据,并逐渐建立类别和特定物品的花费历史记录,以便我们可以进行趋势分析并轻松深入地了解支出去向。起初我觉得这是一个非常困难的任务,但经过一些调查,我发现了一些东西,让我觉得这是可以实现的:
Wal-Mart的收据通常结构良好,易于阅读。它们甚至包括每个项目的UPC(潜在用于UPC数据库的查找?),并且似乎使用F或I对食品进行分类(不确定差异是什么),还有一个税收代码列,这可能会在我了解代码含义的秘密时证明有用。
我进一步发现,有某种Wal-Mart物品查找API,我可能可以获得访问权限,这将在UPC查找中证明有用。
他们为智能手机提供了一个应用程序,可以扫描每张收据上印刷的QR码。该应用程序会从其服务器上查找收据上的“TC”代码,并下载整个详细列表。它会向您显示收据的优秀图形表示,包括所有项目的缩略图和成本等。如果此应用程序只需对收据进行分类和汇总,那就太完美了!但遗憾的是,这不是该应用程序的目的...
谜题的最后一块是,您可以导出计算机生成的收据PNG图像,以便保存并丢弃纸质版本。对我而言,这是重点,因为这些PNG是由计算机创建的,因此不受拍照或扫描纸质收据的问题影响。
以下是其中一个示例(稍作编辑以隐藏某些区域,但其余内容与应用程序获取的完全相同):
https://postimg.cc/image/s56o0wbzf/
你可以看到文本的重要部分完美地对齐在5列中,这才是这个问题的关键。如何让 Tesseract 将其准确地 OCR 成文本。我有很多想法可以从这里开始,但所有的一切都始于 OCR!我自己最接近的例子是这个: 我使用了psm6和字符限制集,强制它只能使用大写字母、数字和少量符号:
tessedit_char_whitelist 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ#()/*@%-.
乍一看,OCR似乎几乎匹配。但是当你深入挖掘时,你会发现它整体上失败得相当惨。3和8几乎总是错误的。5和6也是如此。然后有时它会完全跳过字符或开始崩溃(例如示例中的31+行)。它开始将2看作1,甚至会漏掉字符。第33行的SO PIZZA应该是“2.82”,但输出为“32”。
我已经尝试在图像上进行一些预处理,使字符更加粗细,确保它是纯黑色和白色,但我的所有努力都没有比来自沃尔玛的原始图像和上述命令更接近。
理想情况下,由于这是一个非常结构化的PNG文件,宽度可能始终相同,因此我希望能够通过像素宽度定义列,以便Tesseract将每个列视为独立的。我尝试过研究这个问题,但我看到的UZN文件对于像素宽度来说不太适用,而且它们似乎高度也是一个因素,这对于这些文件来说是不起作用的,因为高度始终会有所变化。
此外,我需要找出如何训练Tesseract以100%准确地识别数字(字母并不重要)。我开始研究如何训练程序,但说实话,由于文档中的培训范围更多地是为了使其识别整个语言而不仅仅是10个数字,因此很快就超出了我的能力范围。
最终的解决方案将是一个管道命令链,它从应用程序中获取原始PNG并将5列数据从收据的重要部分返回给我CSV。我不指望这个问题能够得到解决,但任何帮助引导我走向解决方案都将不胜感激!此时,我只是不想再次被Tesseract折磨,所以我决心找到掌握她的方法!
{kind=link}