我能给出的最佳简短答案就是:测量、测量、测量。使用 Stopwatch 可以感受代码执行时间,但最终你会不得不在大段代码中加入它,或者找到更好的工具。我建议为此获取专用的性能分析器工具,对于 C# 和 .NET 有许多可用的。
我已经通过三个步骤成功地缩减了总运行时间的约43%。
首先,我测量了您的代码并获得了以下结果:
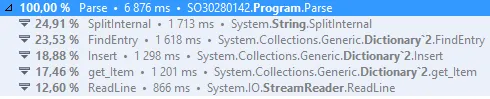
这似乎表明我们可以尝试解决两个热点问题:
- 字符串拆分(SplitInternal)
- 字典维护(FindEntry、Insert、get_Item)
最后一部分时间花费在读取文件上,我真的怀疑我们改变那部分代码不会带来太多收益。这里的另一个答案提到使用特定的缓冲区大小,我尝试过这个方法,但无法获得可衡量的差异。
第一个问题——字符串拆分——比较容易解决,但需要将一个非常简单的 string.Split 调用重新编写成更多的代码。我将处理一行的循环改写为:
while ((line = streamReader.ReadLine()) != null)
{
int lastPos = 0;
for (int index = 0; index <= line.Length; index++)
{
if (index == line.Length || line[index] == ' ')
{
if (lastPos < index)
{
string word = line.Substring(lastPos, index - lastPos);
}
lastPos = index + 1;
}
}
}
我随后将一个单词的处理重写为以下方式:
int currentCount;
wordCount.TryGetValue(word, out currentCount);
wordCount[word] = currentCount + 1;
这取决于以下事实:
TryGetValue方法比检查单词是否存在并检索其当前计数更为便宜。- 如果
TryGetValue无法获取值(键不存在),则会将currentCount变量初始化为其默认值0。这意味着我们不需要真正检查单词是否存在。
- 我们可以通过索引器将新单词添加到字典中(它将覆盖现有值或向字典添加新的键+值)。
因此,最终循环看起来像这样:
while ((line = streamReader.ReadLine()) != null)
{
int lastPos = 0;
for (int index = 0; index <= line.Length; index++)
{
if (index == line.Length || line[index] == ' ')
{
if (lastPos < index)
{
string word = line.Substring(lastPos, index - lastPos);
int currentCount;
wordCount.TryGetValue(word, out currentCount);
wordCount[word] = currentCount + 1;
}
lastPos = index + 1;
}
}
}
新的测量结果显示如下:

详细信息:
- 我们从6876毫秒降到了5013毫秒
- 我们失去了在SplitInternal、FindEntry和get_Item中花费的时间
- 我们获得了在TryGetValue和Substring中花费的时间
这是差异详细信息:
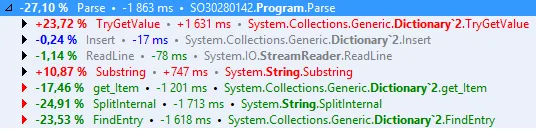
正如您所看到的,我们失去的时间比我们获得的新时间多,这导致了净改善。
然而,我们可以做得更好。我们在这里进行了2个字典查找,这涉及计算单词的哈希码,并将其与字典中的键进行比较。第一个查找是TryGetValue的一部分,第二个查找是wordCount[word] = ...的一部分。
我们可以通过在字典内创建智能数据结构来消除第二个字典查找,代价是使用更多的堆内存。
我们可以使用Xanatos的技巧,在对象内部存储计数,以便我们可以删除第二个字典查找:
public class WordCount
{
public int Count;
}
...
var wordCount = new Dictionary<string, WordCount>();
...
string word = line.Substring(lastPos, index - lastPos);
WordCount currentCount;
if (!wordCount.TryGetValue(word, out currentCount))
wordCount[word] = currentCount = new WordCount();
currentCount.Count++;
这将只从词典中提取计数,增加1个额外出现不涉及词典。该方法的结果也会更改为返回此WordCount类型作为词典的一部分,而不仅仅是一个int。
最终结果:节省约43%。
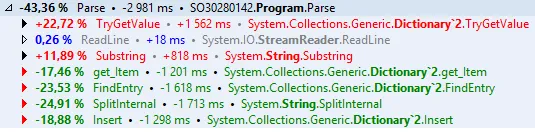
最终代码:
public class WordCount
{
public int Count;
}
public static IDictionary<string, WordCount> Parse(string path)
{
var wordCount = new Dictionary<string, WordCount>();
using (var fileStream = new FileStream(path, FileMode.Open, FileAccess.Read, FileShare.None, 65536))
using (var streamReader = new StreamReader(fileStream, Encoding.Default, false, 65536))
{
string line;
while ((line = streamReader.ReadLine()) != null)
{
int lastPos = 0;
for (int index = 0; index <= line.Length; index++)
{
if (index == line.Length || line[index] == ' ')
{
if (lastPos < index)
{
string word = line.Substring(lastPos, index - lastPos);
WordCount currentCount;
if (!wordCount.TryGetValue(word, out currentCount))
wordCount[word] = currentCount = new WordCount();
currentCount.Count++;
}
lastPos = index + 1;
}
}
}
}
return wordCount;
}