好的,我写了一些代码来检查运行时可用的内存。下面是一个完整(最小)的cpp文件。
注意:这段代码不完美,也不是最佳实践,但我希望你能关注内存管理而不是代码。
它的功能(第一部分):
- (1) 在一个块中分配尽可能多的内存。清除该内存
- (2) 分配尽可能多的中等大小的块(16MB)。清除该内存。
--> 这很好用
它的功能(第二部分):
- (1) 在一个块中分配尽可能多的内存。清除该内存
- (2) 分配尽可能多的微小块(16kb)。清除该内存。
--> 这个表现很奇怪!
问题是:如果我重复这样做,我只能为第二次运行分配522kb --->?
如果分配的块有16MB大小,就不会发生这种情况。
你有任何想法,为什么会发生这种情况吗?
// AvailableMemoryTest.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
#include <vector>
#include <list>
#include <limits.h>
#include <iostream>
int _tmain(int argc, _TCHAR* argv[])
{
auto determineMaxAvailableMemoryBlock = []( void ) -> int
{
int nBytes = std::numeric_limits< int >::max();
while ( true )
{
try
{
std::vector< char >vec( nBytes );
break;
}
catch ( std::exception& ex )
{
nBytes = static_cast< int >( nBytes * 0.99 );
}
}
return nBytes;
};
auto determineMaxAvailableMemoryFragmented = []( int nBlockSize ) -> int
{
int nBytes = 0;
std::list< std::vector< char > > listBlocks;
while ( true )
{
try
{
listBlocks.push_back( std::vector< char >( nBlockSize ) );
nBytes += nBlockSize;
}
catch ( std::exception& ex )
{
break;
}
}
return nBytes;
};
std::cout << "Test with large memory blocks (16MB):\n";
for ( int k = 0; k < 5; k++ )
{
std::cout << "run #" << k << " max mem block = " << determineMaxAvailableMemoryBlock() / 1024.0 / 1024.0 << "MB\n";
std::cout << "run #" << k << " frag mem blocks of 16MB = " << determineMaxAvailableMemoryFragmented( 16*1024*1024 ) / 1024.0 / 1024.0 << "MB\n";
std::cout << "\n";
} // for_k
std::cout << "Test with small memory blocks (16k):\n";
for ( int k = 0; k < 5; k++ )
{
std::cout << "run #" << k << " max mem block = " << determineMaxAvailableMemoryBlock() / 1024.0 / 1024.0 << "MB\n";
std::cout << "run #" << k << " frag mem blocks of 16k = " << determineMaxAvailableMemoryFragmented( 16*1024 ) / 1024.0 / 1024.0 << "MB\n";
std::cout << "\n";
} // for_k
std::cin.get();
return 0;
}
使用大内存块输出(这很好用)
Test with large memory blocks (16MB):
run #0 max mem block = 1023.67MB OK
run #0 frag mem blocks of 16MB = 1952MB OK
run #1 max mem block = 1023.67MB OK
run #1 frag mem blocks of 16MB = 1952MB OK
run #2 max mem block = 1023.67MB OK
run #2 frag mem blocks of 16MB = 1952MB OK
run #3 max mem block = 1023.67MB OK
run #3 frag mem blocks of 16MB = 1952MB OK
run #4 max mem block = 1023.67MB OK
run #4 frag mem blocks of 16MB = 1952MB OK
使用小内存块进行输出(从第二次运行开始,内存分配很奇怪)
Test with small memory blocks (16k):
run #0 max mem block = 1023.67MB OK
run #0 frag mem blocks of 16k = 1991.06MB OK
run #1 max mem block = 0.493021MB ???
run #1 frag mem blocks of 16k = 1991.34MB OK
run #2 max mem block = 0.493021MB ???
run #2 frag mem blocks of 16k = 1991.33MB OK
run #3 max mem block = 0.493021MB ???
run #3 frag mem blocks of 16k = 1991.33MB OK
run #4 max mem block = 0.493021MB ???
run #4 frag mem blocks of 16k = 1991.33MB OK
更新:
这个问题也会出现在使用new和delete[]而不是STL内部的内存分配。
更新:
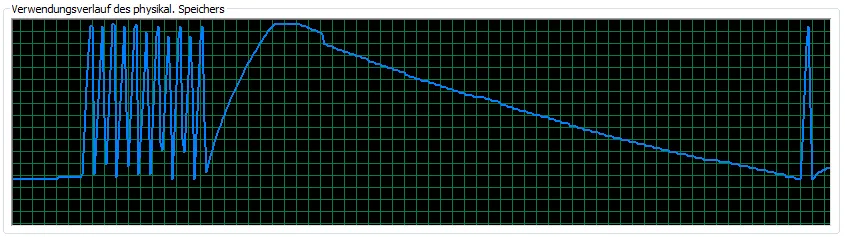
它可以在64位上工作(我限制了两个函数允许分配的内存为12GB)。真的很奇怪。这是该版本RAM使用情况的图像:
更新:
它可以使用malloc和free,但不能使用new和delete[](或者如上所述的STL)。
std::vector<char>而不是更直接的方法(new char[]或malloc)? - sfstewmantcmalloc,看看是否会得到不同的结果。 - Jason