有没有可能同时从列表中删除多个元素?如果我想删除索引为0和2的元素,并尝试类似于del somelist [0]然后跟着del somelist [2],第二条语句实际上会删除somelist[3]。
我猜我可以总是先删除较高编号的元素,但我希望有更好的方法。
list_indices = [0, 2]
original_list = [0, 1, 2, 3]
new_list = np.delete(original_list, list_indices)
输出
array([1, 3])
这里,第一个参数是原始列表,第二个参数是您要删除的索引或索引列表。
如果有ndarrays,可以使用第三个参数:axis(对于ndarrays,0表示行,1表示列)。
我希望找到一种比较不同解决方案的方法,以便更轻松地调整参数。
首先,我生成了我的数据:
import random
N = 16 * 1024
x = range(N)
random.shuffle(x)
y = random.sample(range(N), N / 10)
然后我定义了我的函数:
def list_set(value_list, index_list):
index_list = set(index_list)
result = [value for index, value in enumerate(value_list) if index not in index_list]
return result
def list_del(value_list, index_list):
for index in sorted(index_list, reverse=True):
del(value_list[index])
def list_pop(value_list, index_list):
for index in sorted(index_list, reverse=True):
value_list.pop(index)
然后我使用timeit来比较这些解决方案:
import timeit
from collections import OrderedDict
M = 1000
setup = 'from __main__ import x, y, list_set, list_del, list_pop'
statement_dict = OrderedDict([
('overhead', 'a = x[:]'),
('set', 'a = x[:]; list_set(a, y)'),
('del', 'a = x[:]; list_del(a, y)'),
('pop', 'a = x[:]; list_pop(a, y)'),
])
overhead = None
result_dict = OrderedDict()
for name, statement in statement_dict.iteritems():
result = timeit.timeit(statement, number=M, setup=setup)
if overhead is None:
overhead = result
else:
result = result - overhead
result_dict[name] = result
for name, result in result_dict.iteritems():
print "%s = %7.3f" % (name, result)
输出
set = 1.711
del = 3.450
pop = 3.618
所以,带有 set 索引的生成器是获胜者。而且,del 比 pop 稍微快一点。
some_list.remove(some_list[max(i, j)])
仅为此目的而导入可能过度,但如果您已经在使用 pandas,那么解决方案就是简单明了的:
import pandas as pd
stuff = pd.Series(['a','b','a','c','a','d'])
less_stuff = stuff[stuff != 'a'] # define any condition here
# results ['b','c','d']
我可以想到两种方法来实现:
像这样切片列表(这将删除第1、3和8个元素)
somelist = somelist[1:2]+somelist[3:7]+somelist[8:]
逐个在原地进行操作:
somelist.pop(2) somelist.pop(0)
我使用perfplot测试了建议的解决方案,并发现NumPy的性能最佳。
np.delete(lst, remove_ids)
如果列表长度超过100条,使用set()是最快的解决方案。在此之前,所有解决方案的时间都在10^-5秒左右。那么列表推导式看起来足够简单:
out = [item for i, item in enumerate(lst) if i not in remove_ids]
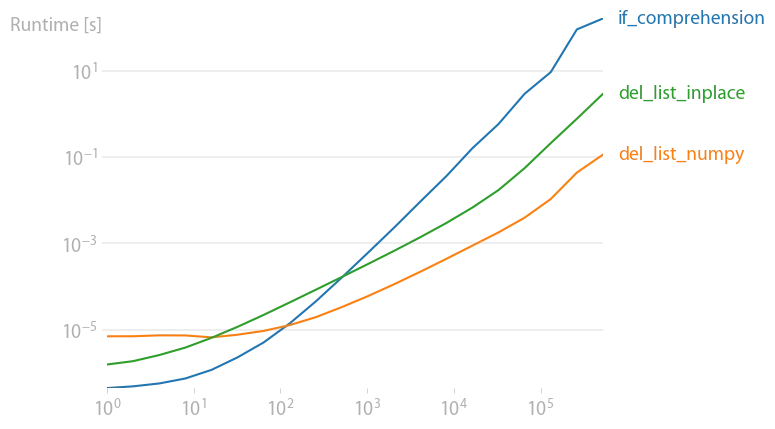
用于重现图形的代码:
import perfplot
import random
import numpy as np
import copy
def setup(n):
lst = list(range(n))
random.shuffle(lst)
# //10 = 10%
remove_ids = random.sample(range(n), n // 10)
return lst, remove_ids
def if_comprehension(lst, remove_ids):
return [item for i, item in enumerate(lst) if i not in remove_ids]
def del_list_inplace(lst, remove_ids):
out = copy.deepcopy(lst)
for i in sorted(remove_ids, reverse=True):
del out[i]
return out
def del_list_numpy(lst, remove_ids):
return np.delete(lst, remove_ids)
b = perfplot.bench(
setup=setup,
kernels=[if_comprehension, del_list_numpy, del_list_inplace],
n_range=[2**k for k in range(20)],
)
b.save("out.png")
b.show()
你可以在字典上这样做,而不是在列表上。在列表中,元素是按顺序排列的。在字典中,它们仅依赖于索引。
下面是一个简单的代码示例,用于解释:
>>> lst = ['a','b','c']
>>> dct = {0: 'a', 1: 'b', 2:'c'}
>>> lst[0]
'a'
>>> dct[0]
'a'
>>> del lst[0]
>>> del dct[0]
>>> lst[0]
'b'
>>> dct[0]
Traceback (most recent call last):
File "<pyshell#19>", line 1, in <module>
dct[0]
KeyError: 0
>>> dct[1]
'b'
>>> lst[1]
'c'
>>> dct = {}
>>> for i in xrange(0,len(lst)): dct[i] = lst[i]
它的逆是:
lst = [dct[i] for i in sorted(dct.keys())]
无论如何,我认为从高索引开始删除会更好,就像你说的那样。
到目前为止提供的答案都无法在O(n)时间复杂度内就任意数量的索引进行原地删除,因此这里是我的版本:
def multi_delete(the_list, indices):
assert type(indices) in {set, frozenset}, "indices must be a set or frozenset"
offset = 0
for i in range(len(the_list)):
if i in indices:
offset += 1
elif offset:
the_list[i - offset] = the_list[i]
if offset:
del the_list[-offset:]
# Example:
a = [0, 1, 2, 3, 4, 5, 6, 7]
multi_delete(a, {1, 2, 4, 6, 7})
print(a) # prints [0, 3, 5]
import numpy as np
arr = np.array([0,3,5,7])
# [0,3,5,7]
indexes = [0,3]
np.delete(arr, indexes)
# [3,5]
第二种方法(使用Python列表):
arr = [0,3,5,7]
# [0,3,5,7]
indexes = [0,3]
for index in sorted(indexes, reverse=True):
del arr[index]
arr
# [3,5]
编写代码对一个包含500000个元素的数组进行基准测试,随机删除其中一半元素:
import numpy as np
import random
import time
start = 0
stop = 500000
elements = np.arange(start,stop)
num_elements = len(temp)
temp = np.copy(elements)
temp2 = elements.tolist()
indexes = random.sample(range(0, num_elements), int(num_elements/2))
start_time = time.time()
temp = np.delete(temp, indexes)
end_time = time.time()
total_time = end_time - start_time
print("First method: ", total_time)
start_time = time.time()
for index in sorted(indexes, reverse=True):
del temp2[index]
end_time = time.time()
total_time = end_time - start_time
print("Second method: ", total_time)
# First method: 0.04500985145568848
# Second method: 16.94180393218994
第一种方法比第二种方法快约376倍。
这些中的一个怎么样(我对Python非常新手,但它们看起来还不错):
ocean_basin = ['a', 'Atlantic', 'Pacific', 'Indian', 'a', 'a', 'a']
for i in range(1, (ocean_basin.count('a') + 1)):
ocean_basin.remove('a')
print(ocean_basin)
['大西洋', '太平洋', '印度洋']
ob = ['a', 'b', 4, 5,'Atlantic', 'Pacific', 'Indian', 'a', 'a', 4, 'a']
remove = ('a', 'b', 4, 5)
ob = [i for i in ob if i not in (remove)]
print(ob)
['大西洋', '太平洋', '印度洋']