能否有人解释一下这个语句:
shared variables
x = 0, y = 0
Core 1 Core 2
x = 1; y = 1;
r1 = y; r2 = x;
在x86处理器上,怎么可能同时使r1 == 0和r2 == 0呢?
能否有人解释一下这个语句:
shared variables
x = 0, y = 0
Core 1 Core 2
x = 1; y = 1;
r1 = y; r2 = x;
在x86处理器上,怎么可能同时使r1 == 0和r2 == 0呢?
r1 and r2 before assigning variables x and y, if they find that this would yield better performance. This can be solved by adding a 内存屏障, which would enforce the ordering constraint.Regarding the x86 architecture, the best resource to read is Intel® 64 和 IA-32 架构软件开发人员手册 (Chapter 8.2 Memory Ordering). Sections 8.2.1 and 8.2.2 describe the memory-ordering implemented by Intel486, Pentium, Intel Core 2 Duo, Intel Atom, Intel Core Duo, Pentium 4, Intel Xeon, and P6 family processors: a memory model called processor ordering, as opposed to program ordering (strong ordering) of the older Intel386 architecture (where read and write instructions were always issued in the order they appeared in the instruction stream).现代多核 / 语言破坏了顺序一致性。
shared variables
x = 0, y = 0
Core 1 Core 2
r1 = y; r2 = x;
x = 1; y = 1;
r1 = 1和r2 = 1的情况发生(由于8.2.3.3存储不会与早期加载重新排序的保证),这意味着这些指令永远不会在单个核心中重新排序。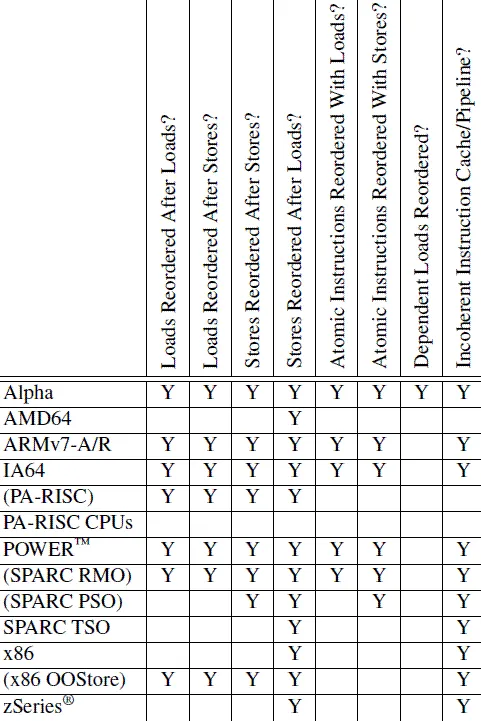
sigprocmask的调用时,由于信号处理语义而出现问题。 - R.. GitHub STOP HELPING ICECore1在y之前看到x的写入,而Core2在x之前看到y的写入。在这种情况下不需要完整的屏障指令... 基本上,只需要强制执行写入或释放语义以确保在读取已写入的变量之前将所有写入提交并显示给所有处理器即可。像x86这样具有强内存一致性模型的处理器体系结构通常不需要这样做,但正如Groo所指出的那样,编译器本身也可以重新排序操作。您可以在C和C++中使用volatile关键字来防止编译器在给定线程内重新排序操作。这并不是说volatile将创建管理线程间读写可见性的线程安全代码...需要使用内存屏障。因此,虽然使用volatile仍然可能创建不安全的线程化代码,但在给定线程中,它将在编译的机器代码级别上强制执行顺序一致性。volatile不能防止编译器在同一线程内重新排序,那么在内存映射的I/O中使用它就毫无意义...编译器仍然会重新排序读写操作,导致各种未定义的硬件行为。 volatile关键字不能防止CPU指令重排,也不能强制保证线程之间的读写可见性...这需要一个内存屏障...但是它确实可以防止编译器在给定的线程中重新排序源代码中定义的操作。 - Jason
mfence的情况,并解释了为什么允许发生这种情况。在 C/C++ 中,如果它们不是原子性的,则只是普通的未定义行为;如果它们是原子性的,则只能使用memory_order_release或更弱的方式进行重排序。 - Peter Cordes