我的原始PDF文件大小约为24MB,但是当我将其编码为base64字符串时,字符串大小约为31MB。我想知道为什么。
对于图像文件来说这很容易理解,因为它可能会失去一些压缩,但是对于PDF或其他格式的文件也会发生吗?
我的原始PDF文件大小约为24MB,但是当我将其编码为base64字符串时,字符串大小约为31MB。我想知道为什么。
对于图像文件来说这很容易理解,因为它可能会失去一些压缩,但是对于PDF或其他格式的文件也会发生吗?
+−−−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−+
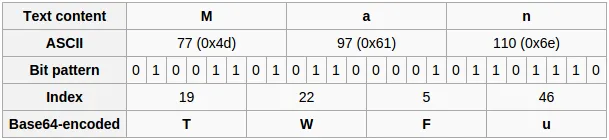
| Text content | M | a | n |
+−−−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−+
| ASCII | 77 (0x4d) | 97 (0x61) | 110 (0x6e) |
| Bit pattern | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 |
| Index | 19 | 22 | 5 | 46 |
| Base64−encoded | T | W | F | u |
+−−−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−−−+
9表示为1001,占用了四倍的空间!你正在从256进制转换为64进制,这将带来一些空间上的收益——通常是33%,因为64进制不会愚蠢,并包含一些数据重新打包的技巧。 - Niet the Dark Absol