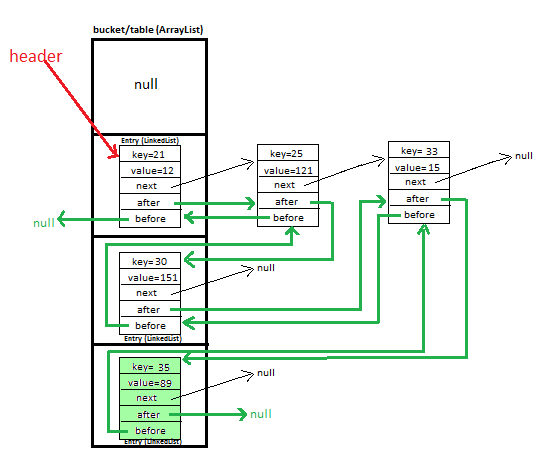
我阅读到HashMap有以下实现方式:
main array
↓
[Entry] → Entry → Entry ← linked-list implementation
[Entry]
[Entry] → Entry
[Entry]
[null ]
所以,它有一个Entry对象的数组。
问题:
我想知道,在哈希值相同但对象不同的情况下,该数组的索引如何存储多个Entry对象。
这与LinkedHashMap实现有何区别?它是地图的双向链表实现,但是否保持类似上述的数组结构,并且如何存储指向下一个和上一个元素的指针?