x <- c('a', 'v', 'c', 'a', 'd', 'e', 'g', 'f', 'h', 'y', 'u', 'r', 's', 'w', 's', 'd', 'g', 'j', 'u', 'r', 's', 's', 's', 'v', 'b', 'g', 'e', 'w', 's', 'd', 'g', 'h', 'j', 'i', 't', 'e', 'w', 'w', 'q', 'q', 'd', 'v', 'b', 'm', 'm', 'k', 'l', 'u', 'p', 'o', 'r', 't', 'n', 'e', 'w', 'w', 'j', 'f', 'c', 'g', 'h', 't', 'r', 'd', 'e', 'w', 'w', 'w', 'z', 'f', 'g', 'f', 'h', 'h', 'y', 'r', 'f', 'f', 'l')
y <- sample(1:40, 79, replace=T)
y
1 38 18 19 19 37 38 26 4 32 23 11 24 36 15 22 19 6 24 13 36 2 26 35 39 8 33 20 19 23 28 5 17 40 26 18 21 [37] 35 23 27 12 3 33 16 32 11 19 4 5 8 19 5 19 33 33 33 13 12 32 21 4 14 8 28 34 33 22 34 19 39 23 6 8 [73] 37 17 21 16 38 15 36
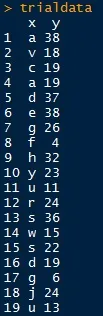
我有两个变量'x'和'y'。在'x'中有多个观察实例。对应于'x'中的每个观察值,都有相应的'y'值。
我想要实现对'y'值进行分组和分区间的操作。
换句话说,每个字母出现的次数将被划分为不同的间隔,这些间隔是根据每个字母在其出现中被赋予的值来确定的。
例如:
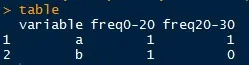
由于我在此处无法找到更好的输入方式,因此无法正确地表示表格。
希望我的意思清楚了。如果需要,我会尝试重新陈述它。 非常感谢您的帮助。
dplyr一无所知,因此基于 Ananda 的建议提供了解决方案。有趣的是,如果有人能想出更简洁的dplyr解决方案会更加有趣。 - tchakravartyc(0,13,30,..),而不是使用seq。我只是根据你的示例使用了seq。 - akrun