我已在使用SQL Server 2008的计算机上制作了一个dtsx包。 它将分号分隔的csv文件中的数据导入到所有字段类型为NVARCHAR MAX的表中。
它在我的计算机上运作良好,但需要在客户端服务器上运行。 当他们使用相同的csv文件和目标表创建相同的包时,他们会收到上述错误。
我们一步一步地进行了包的创建,一切似乎都没问题。 映射都是正确的,但当他们在最后一步运行包时,他们会收到此错误。 他们正在使用SQL Server 2005。
有人能指导从哪里开始查找这个问题吗?
我已在使用SQL Server 2008的计算机上制作了一个dtsx包。 它将分号分隔的csv文件中的数据导入到所有字段类型为NVARCHAR MAX的表中。
它在我的计算机上运作良好,但需要在客户端服务器上运行。 当他们使用相同的csv文件和目标表创建相同的包时,他们会收到上述错误。
我们一步一步地进行了包的创建,一切似乎都没问题。 映射都是正确的,但当他们在最后一步运行包时,他们会收到此错误。 他们正在使用SQL Server 2005。
有人能指导从哪里开始查找这个问题吗?
有时候你需要将一个 nvarchar 列转换成一个 varchar 列(或者反过来)。
此外,为什么所有的东西都是(假定为)nvarchar(max)?如果我发现这样的代码,我会认为这是一个坏味道。你知道 SQL Server 是如何存储这些列的吗?它们使用指针来指向实际行中存储的列位置,因为它们不能适应8k页面。
两个解决方案: 1- 如果目标列的类型为[nvarchar],则应更改为[varchar]
2- 在SSIS包中添加“派生列”组件,并添加一个新列,该列具有以下表达式:
(DT_WSTR,“长度”) [ColumnName]
其中“长度”是目标表中列的长度,“ColumnName”是目标表中列的名称。最后,在映射部分,您应该使用此新添加的列而不是原始列。
非Unicode字符串数据类型:
对于文本文件,使用STR;对于SQL Server列,使用VARCHAR。
Unicode字符串数据类型:
对于文本文件,使用W_STR;对于SQL Server列,使用NVARCHAR。
问题在于您的数据类型不匹配,因此在转换过程中可能会丢失数据。
我不确定这是否是SSIS的最佳实践,但有时候当你想进行此类操作时,他们的工具有点笨重。
与其使用他们的组件,你可以在查询中转换数据。
不要这样做:
SELECT myField = myNvarchar20Field
FROM myTable
您可以做
SELECT myField = CONVERT(VARCHAR(20),myNvarchar20Field)
FROM myTable
这是一种使用IDE进行修复的解决方案:
Data Conversion 项目;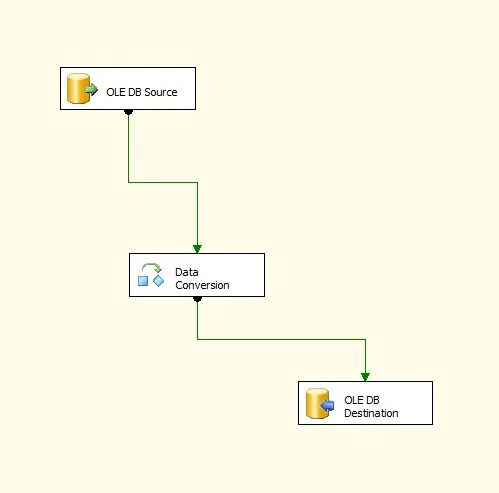
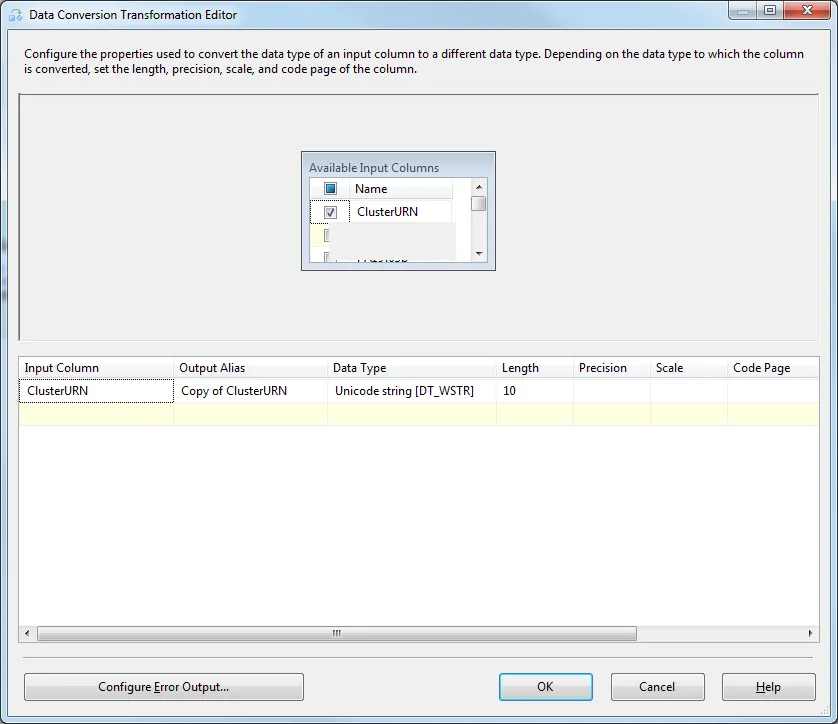
Data Conversion 项目,并按照以下设置:
DB Destination 项目,点击 Mapping,确保你的输入列实际上与来自 [你的列名] 的副本相同,这实际上是 Data Conversion 的输出而不是 DB Source 的输出(要小心)。以下是截图: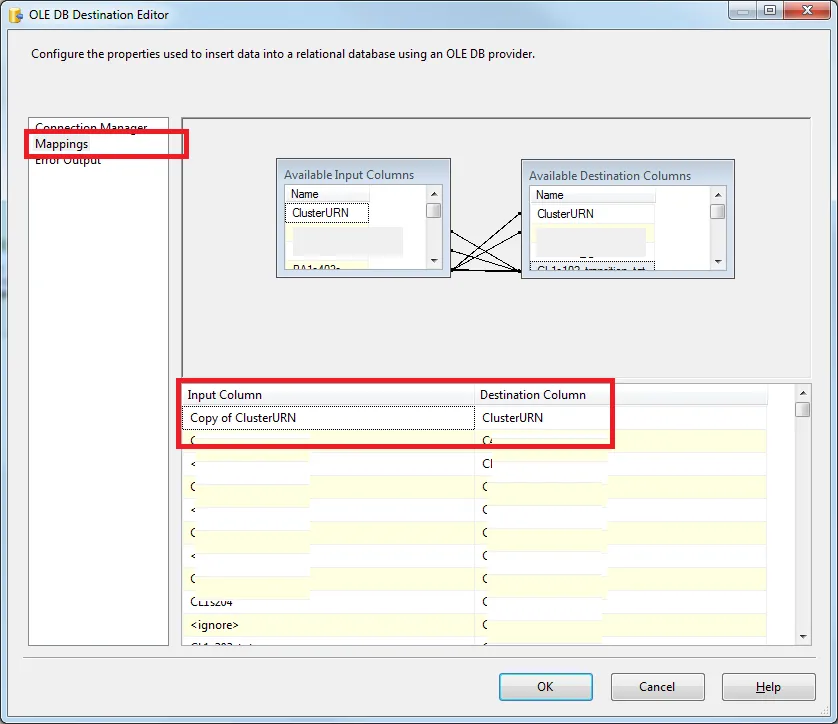
就是这样了..保存并运行..
Mike,我遇到了与SQL Server 2005中的SSIS相同的问题......显然,DataFlowDestination对象始终会尝试将输入的数据验证为Unicode编码。前往该对象,打开高级编辑器,进入组件属性窗格,将“ValidateExternalMetaData”属性更改为False。现在,进入输入输出属性窗格,选择目标输入、外部列,将每个列的数据类型和长度设置为要匹配的数据库表。现在,当你关闭该编辑器时,这些列更改将被保存而不会进行验证,并且它将正常工作。
遵循以下步骤以避免出现“无法在unicode和非unicode字符串数据类型之间进行转换”的错误:
i)将“数据转换转换工具”添加到您的数据流中。
ii)打开数据流转换并选择[string DT_STR]数据类型。
iii)然后进入目标流,选择映射。
iv)将您的i / p名称更改为名称的副本。
http://rdc.codeplex.com/releases/view/48420
*Open the .DTSX file on Notepad++. Choose language as XML
*Goto the <DTS:FlatFileColumns> tag. Select all items within this tag
*Find the string **DTS:DataType="129"** replace with **DTS:DataType="130"**
*Save the .DTSX file.
*Open the project again on Visual Studio BIDS
*Double Click on the Source Task . You would get the message
the metadata of the following output columns does not match the metadata of the external columns with which the output columns are associated:
...
Do you want to replace the metadata of the output columns with the metadata of the external columns?
*Now Click Yes. We are done !
进入注册表以配置客户端并更改语言。 对于Oracle,请转到HLM\SOFTWARE\ORACLE\KEY_ORACLIENT...HOME\NLS_LANG并更改为适当的语言。