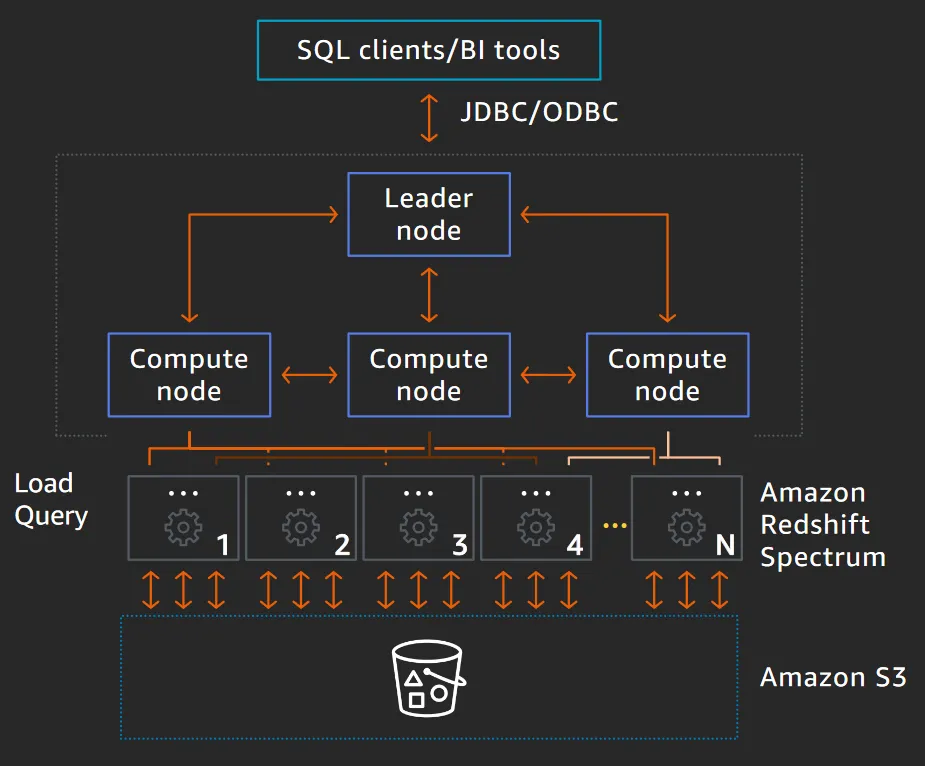
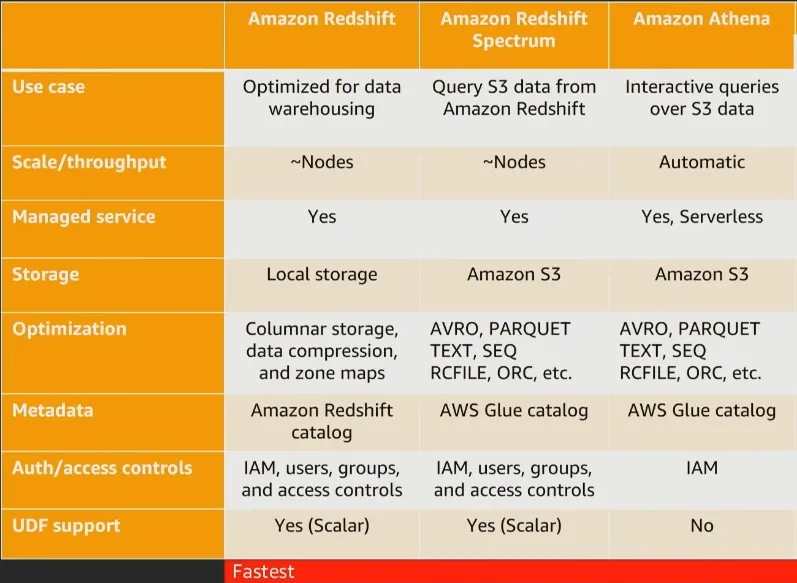
我正在评估 Athena 和 Redshift Spectrum。这两者都有同样的目的,Spectrum需要一个Redshift集群,而Athena是纯无服务器的。Athena使用Presto查询引擎,而Spectrum使用Redshift的引擎。
那么Athena和Redshift Spectrum有什么具体的缺点吗?在使用Athena或Spectrum时有哪些限制吗?
那么Athena和Redshift Spectrum有什么具体的缺点吗?在使用Athena或Spectrum时有哪些限制吗?