问题设置介绍
我正在进行一些基准测试,涉及到一个没有NaN的双精度数组的~A和A==0,两者都将A转换为逻辑数组,其中所有的0被转换为true值,其余的则设为false值。
对于基准测试,我使用了三组输入数据 -
- 非常小到小型数据 -
15:5:100 - 小到中等大小的数据 -
50:40:1000 - 中等到大型数据 -
200:400:3800
输入是用A = round(rand(N)*20)创建的,其中N是从大小数组中取出的参数。因此,N将从15到100以5为步长变化,第二和第三组类似。请注意,我定义数据大小为N,因此元素的数量将是datasize^2或N^2。
基准测试代码
N_arr = 15:5:100; %// for very small to small sized input array
N_arr = 50:40:1000; %// for small to medium sized input array
N_arr = 200:400:3800; %// for medium to large sized input array
timeall = zeros(2,numel(N_arr));
for k1 = 1:numel(N_arr)
A = round(rand(N_arr(k1))*20);
f = @() ~A;
timeall(1,k1) = timeit(f);
clear f
f = @() A==0;
timeall(2,k1) = timeit(f);
clear f
end
结果
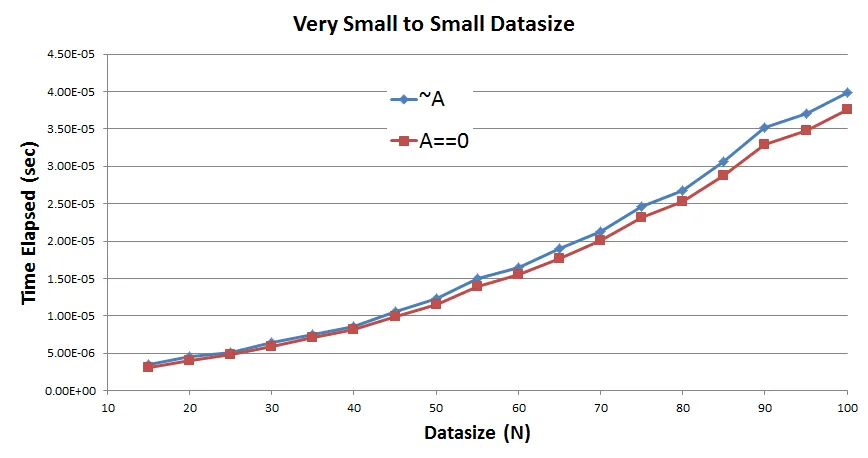
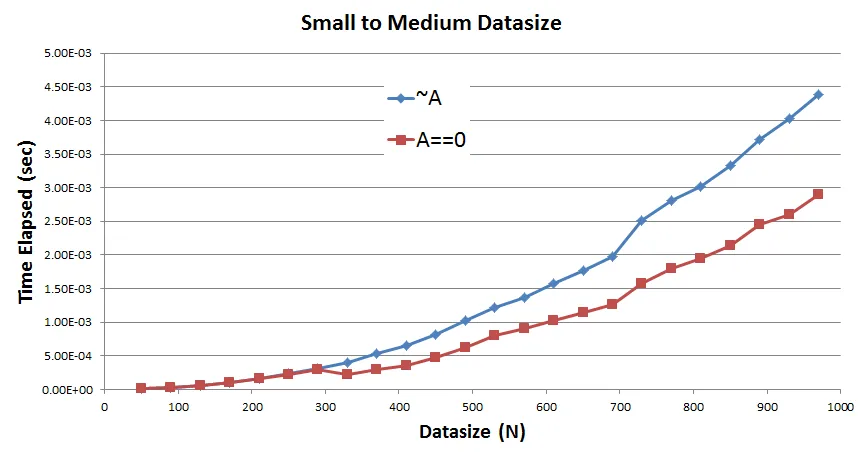
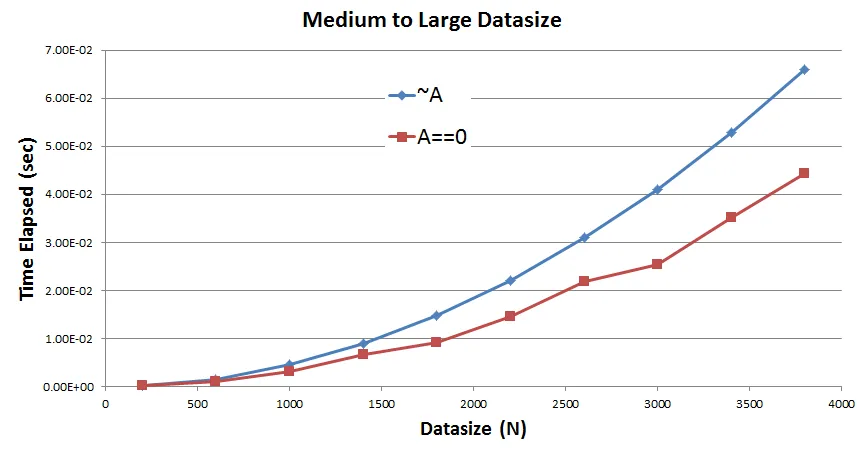
最后是问题:
可以看到在所有数据大小上,A==0 的表现比 ~A 好。因此,这里有一些观察和相关问题 -
A==0有一个关系运算符和一个操作数,而~A只有一个关系运算符。两者都产生逻辑数组并都接受双精度数组。实际上,A==0也可以处理NaNs,但~A不能。那么,为什么~A至少不像看起来的A==0那样好,因为A==0正在做更多的工作,或者我在这里漏掉了什么吗?A==0在N = 320,即102400个元素的 A 上出现了经过时间的奇怪下降,因此性能有所提高。我在两个不同系统上的多次运行中都观察到了这一点。那么这是怎么回事?
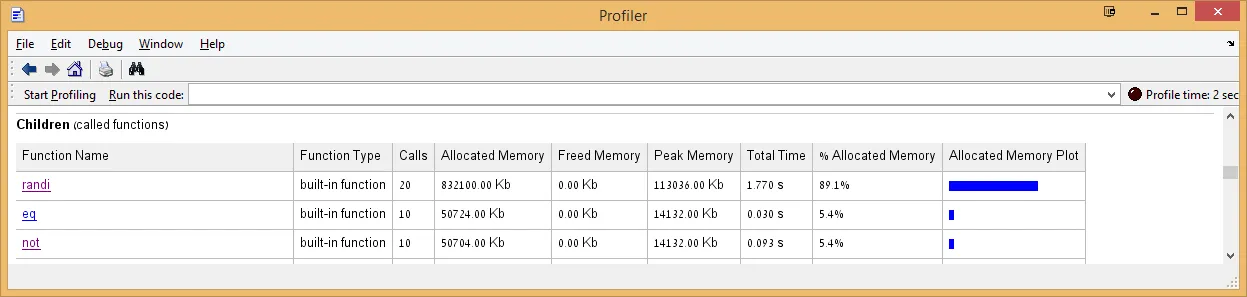 关于你的第二个问题:在删除保留timeall之前,我尝试用Excel绘制了与你相同的图表。我没有观察到你提到的N = 320的行为。我怀疑这可能与你代码中使用的额外包装(即函数句柄)有关。
关于你的第二个问题:在删除保留timeall之前,我尝试用Excel绘制了与你相同的图表。我没有观察到你提到的N = 320的行为。我怀疑这可能与你代码中使用的额外包装(即函数句柄)有关。
nnz()函数! - Nematollah ZarmehiA == 0,因为这个表达式恰好说明了你要做的事情,而~A则依赖于布尔和数值的歧义,基本上是一个技巧。而且正如你发现的那样,它也更有效率。至于实现细节,我不清楚,但我通常发现Matlab足够高效,可以让你所编写的代码就是你的意思(WYCIWYM);-) - A. Dondalogical(A)和A~=0)。 - Luis MendoA被缓存。因此,A==0比之前没有访问它时更快。 在第一次clear f之后再触发A = round(rand(N_arr(k1))*20);,看看是否有很大的差异。 此外,randi()可以简化您的代码。 - Markusrandi是个好建议!我可能会加上它。 - Divakar