Non-cryptographic hashes,例如MurmurHash3和xxHash,几乎专门为哈希表设计,但它们似乎与CRC-32、Adler-32和Fletcher-32的功能相当甚至更好。非加密哈希通常比CRC-32更快,并产生类似于慢加密哈希(MD5,SHA)的更多“随机”输出。尽管如此,我只看到CRC-32或MD5被推荐用于数据完整性/校验和目的。
在下表中,我测试了32位校验和/CRC/hash函数,以确定它们检测数据中小差异的效果如何:
看着这张表格,MurmurHash3和 Jenkins lookup2与CRC-32(实际上有一个测试失败)相比较,表现得更好。它们也很均匀。DJB2和FNV1a通过碰撞测试,但分布不均匀。Fletcher32和Adler32在NullBytes和8RandBytes测试中表现不佳。
那么我的问题是,与其他校验和相比,'非加密哈希'用于检测文件中的错误或差异有多合适?是否有任何理由认为CRC-32 / Adler-32 / CRC-64可能优于任何良好的32位/ 64位哈希?
在下表中,我测试了32位校验和/CRC/hash函数,以确定它们检测数据中小差异的效果如何:
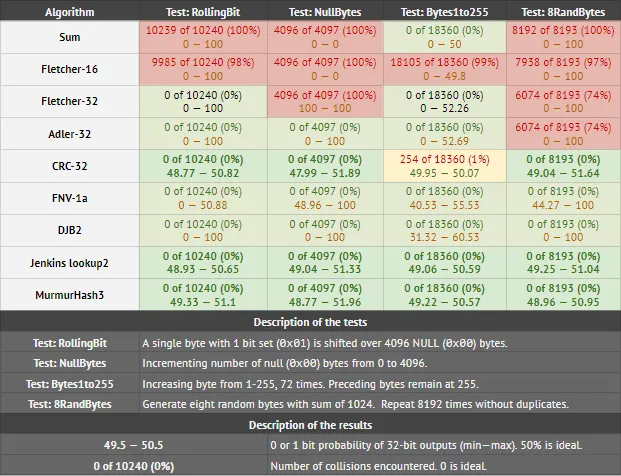
看着这张表格,MurmurHash3和 Jenkins lookup2与CRC-32(实际上有一个测试失败)相比较,表现得更好。它们也很均匀。DJB2和FNV1a通过碰撞测试,但分布不均匀。Fletcher32和Adler32在NullBytes和8RandBytes测试中表现不佳。
那么我的问题是,与其他校验和相比,'非加密哈希'用于检测文件中的错误或差异有多合适?是否有任何理由认为CRC-32 / Adler-32 / CRC-64可能优于任何良好的32位/ 64位哈希?