尝试使用BERT模型对文本情感进行分类,但是遇到了ValueError: too many dimensions 'str'错误。
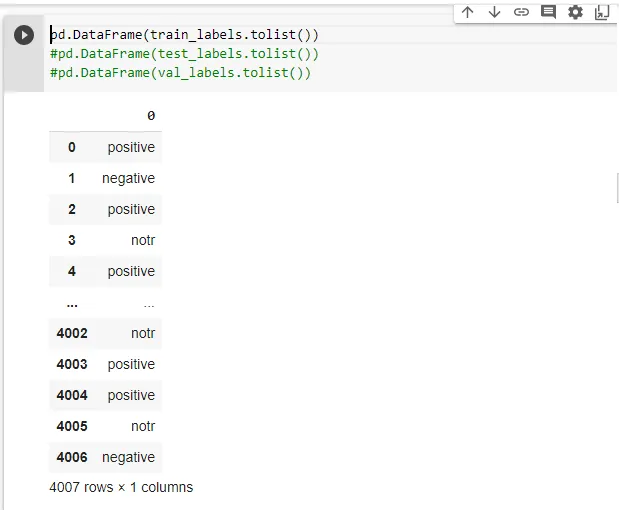
这是训练数据值的DataFrame;因此它们是train_labels。
0 notr
1 notr
2 notr
3 negative
4 notr
... ...
854 positive
855 notr
856 notr
857 notr
858 positive
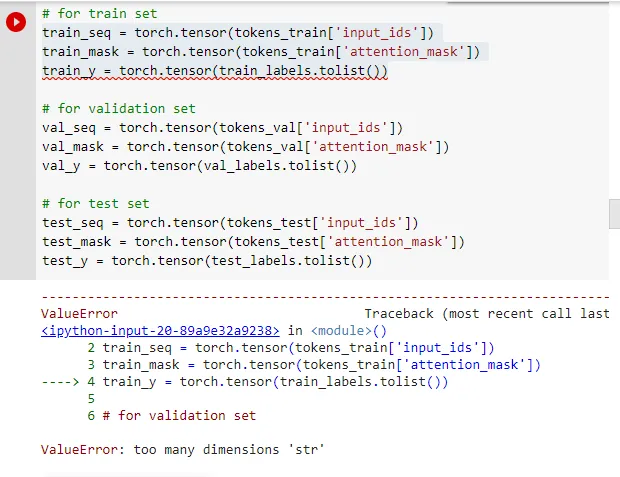
这里有一段产生错误的代码:
train_seq = torch.tensor(tokens_train['input_ids'])
train_mask = torch.tensor(tokens_train['attention_mask'])
train_y = torch.tensor(train_labels.tolist())
在 train_y = torch.tensor(train_labels.tolist()); 处出现错误:ValueError: too many dimensions 'str'
请问您能帮我解决吗?