我帮助您翻译以下关于IT技术的内容,涉及到一个字典函数中正确命名捕获的显示问题。我的程序读取一个.txt文件并将其中的文本转化成字典格式。我已经确定了正确的正则表达式公式以便进行捕获。
这是我的File.txt文件:
file Science/Chemistry/Quantum 444 1
file Marvel/CaptainAmerica 342 0
file DC/JusticeLeague/Superman 300 0
file Math 333 0
file Biology 224 1
这是一个能够捕获我想要的内容的正则表达式链接:
通过查看链接,我想要显示的部分用绿色和橙色进行了高亮。
下面是我代码中有效的部分:
rx= re.compile(r'file (?P<path>.*?)( |\/.*?)? (?P<views>\d+).+')
i = sub_pattern.match(data) # 'data' is from the .txt file
x = (i.group(1), i.group(3))
print(x)
但是由于我要把 .txt 文件变成字典,我无法想出如何将 .group(1) 或 .group(3) 作为键来显示在我的显示函数中。我不知道如何在使用 print("Title: %s | Number: %s" % (key[1], key[3])) 时显示这些组的内容。希望有人能帮助我在字典函数中实现这一点。
这是我的字典函数:
def create_dict(data):
dictionary = {}
for line in data:
line_pattern = re.findall(r'file (?P<path>.*?)( |\/.*?)? (?P<views>\d+).+', line)
dictionary[line] = line_pattern
content = dictionary[line]
print(content)
return dictionary
我想让我的文本文件输出看起来像这样:
Science 444
Marvel 342
DC 300
Math 333
Biology 224
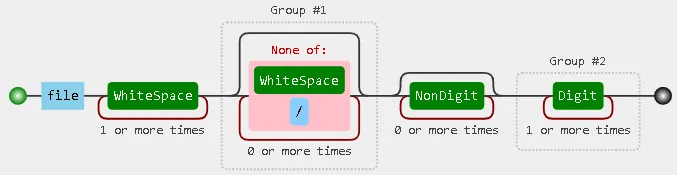
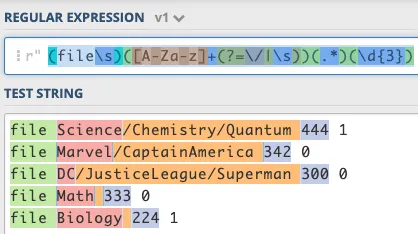
m = re.search(r'file ([^/\s]*).*?(\d+)', line)(演示) 在一行中搜索匹配项,然后if m:你可以将"{} {}".format(m.group(1), m.group(2))添加到输出中。 - Wiktor Stribiżew