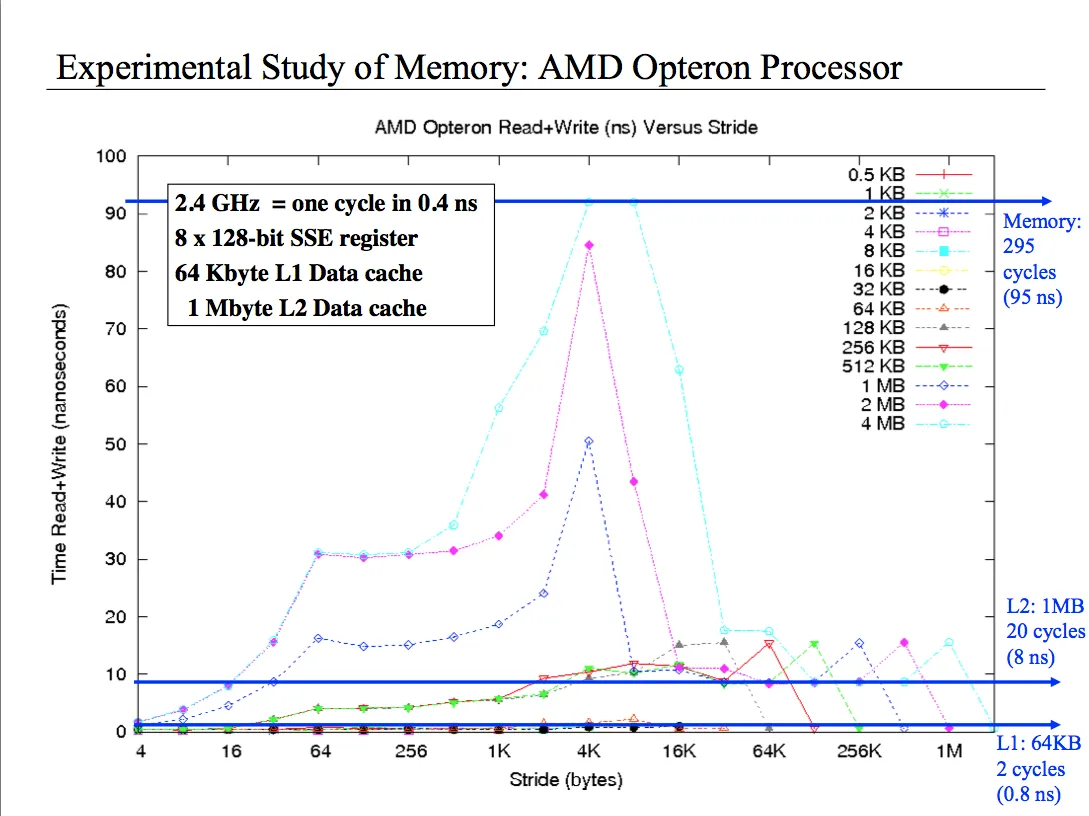
我尝试了各种可能的推理,但我真的不太理解这个图表。它基本上显示了从不同大小的数组中读取和写入不同步长时的性能。我知道对于像4字节这样的小步长,我可以读取缓存中的所有单元格,因此我具有良好的性能。但是当我使用2MB数组和4k步长时会发生什么?或者4M和4k步长呢?为什么性能如此糟糕?最后,为什么当我有1MB数组并且步长是大小的1/8时性能还可以,而当步长是大小的1/4时性能变差,然后在一半大小时,性能非常好?请帮帮我,这件事让我发疯。
在此链接中,代码:https://dl.dropboxusercontent.com/u/18373264/membench/membench.c