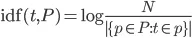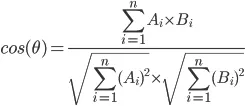我在使用PHP的levenshtein函数比较字符串方面取得了一些成功。
然而,对于包含交换位置的子字符串的两个字符串,该算法会将其视为全新的子字符串。
例如:
被视为比其他人有着更少共同点的人:
我更喜欢一个算法,它能够看到前两个更相似。
我该如何设计一个比较函数,能够识别位置交换的子字符串作为编辑的不同之处?
我想到的一个可能的方法是在比较之前,将字符串中的所有单词按字母顺序排列。这样做完全消除了单词的原始顺序对比较的影响。然而,这种方法的一个缺点是,只改变一个单词的第一个字母可能会引起比改变一个字母应该引起的更大的干扰。
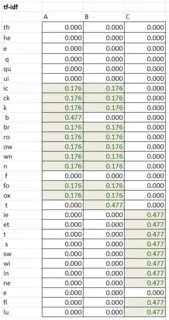
我试图比较关于人的两个自由文本字符串的两个事实,并决定这些事实表明相同事实的可能性有多大。这些事实可能是某人就读的学校、雇主或出版商的名称,例如。两条记录可能会有不同拼写的相同学校、单词顺序不同、有额外的单词等等,所以如果我们要猜测它们是否指的是同一所学校,匹配必须有一定的模糊性。到目前为止,它在拼写错误方面表现得非常好(我在所有这些之上使用了类似于metaphone的音标算法),但如果你改变单词的顺序,它的表现非常差,而这在学校中似乎很常见:“xxx学院”与“学院xxx”。
然而,对于包含交换位置的子字符串的两个字符串,该算法会将其视为全新的子字符串。
例如:
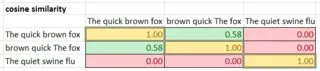
levenshtein("The quick brown fox", "brown quick The fox"); // 10 differences
被视为比其他人有着更少共同点的人:
levenshtein("The quick brown fox", "The quiet swine flu"); // 9 differences
我更喜欢一个算法,它能够看到前两个更相似。
我该如何设计一个比较函数,能够识别位置交换的子字符串作为编辑的不同之处?
我想到的一个可能的方法是在比较之前,将字符串中的所有单词按字母顺序排列。这样做完全消除了单词的原始顺序对比较的影响。然而,这种方法的一个缺点是,只改变一个单词的第一个字母可能会引起比改变一个字母应该引起的更大的干扰。
我试图比较关于人的两个自由文本字符串的两个事实,并决定这些事实表明相同事实的可能性有多大。这些事实可能是某人就读的学校、雇主或出版商的名称,例如。两条记录可能会有不同拼写的相同学校、单词顺序不同、有额外的单词等等,所以如果我们要猜测它们是否指的是同一所学校,匹配必须有一定的模糊性。到目前为止,它在拼写错误方面表现得非常好(我在所有这些之上使用了类似于metaphone的音标算法),但如果你改变单词的顺序,它的表现非常差,而这在学校中似乎很常见:“xxx学院”与“学院xxx”。