该函数定义为
void bucketsort(Array& A){
size_t numBuckets=A.size();
iarray<List> buckets(numBuckets);
//put in buckets
for(size_t i=0;i!=A.size();i++){
buckets[int(numBuckets*A[i])].push_back(A[i]);
}
////get back from buckets
//for(size_t i=0,head=0;i!=numBuckets;i++){
//size_t bucket_size=buckets[i].size();
//for(size_t j=0;j!=bucket_size;j++){
// A[head+j] = buckets[i].front();
// buckets[i].pop_front();
//}
//head += bucket_size;
//}
for(size_t i=0,head=0;i!=numBuckets;i++){
while(!buckets[i].empty()){
A[head] = buckets[i].back();
buckets[i].pop_back();
head++;
}
}
//inseration sort
insertionsort(A);
}
其中List在STL中表示list<double>。
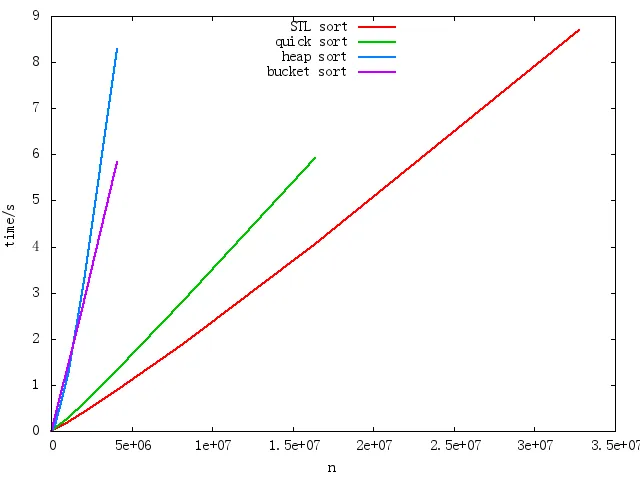
数组的内容在[0,1)范围内随机生成。理论上,桶排序对于大规模数据应该比快排更快,因为它的时间复杂度是O(n),但是实际情况却不尽如人意,如下图所示:
我使用google-perftools对10000000个双精度浮点数进行了性能测试,结果如下:
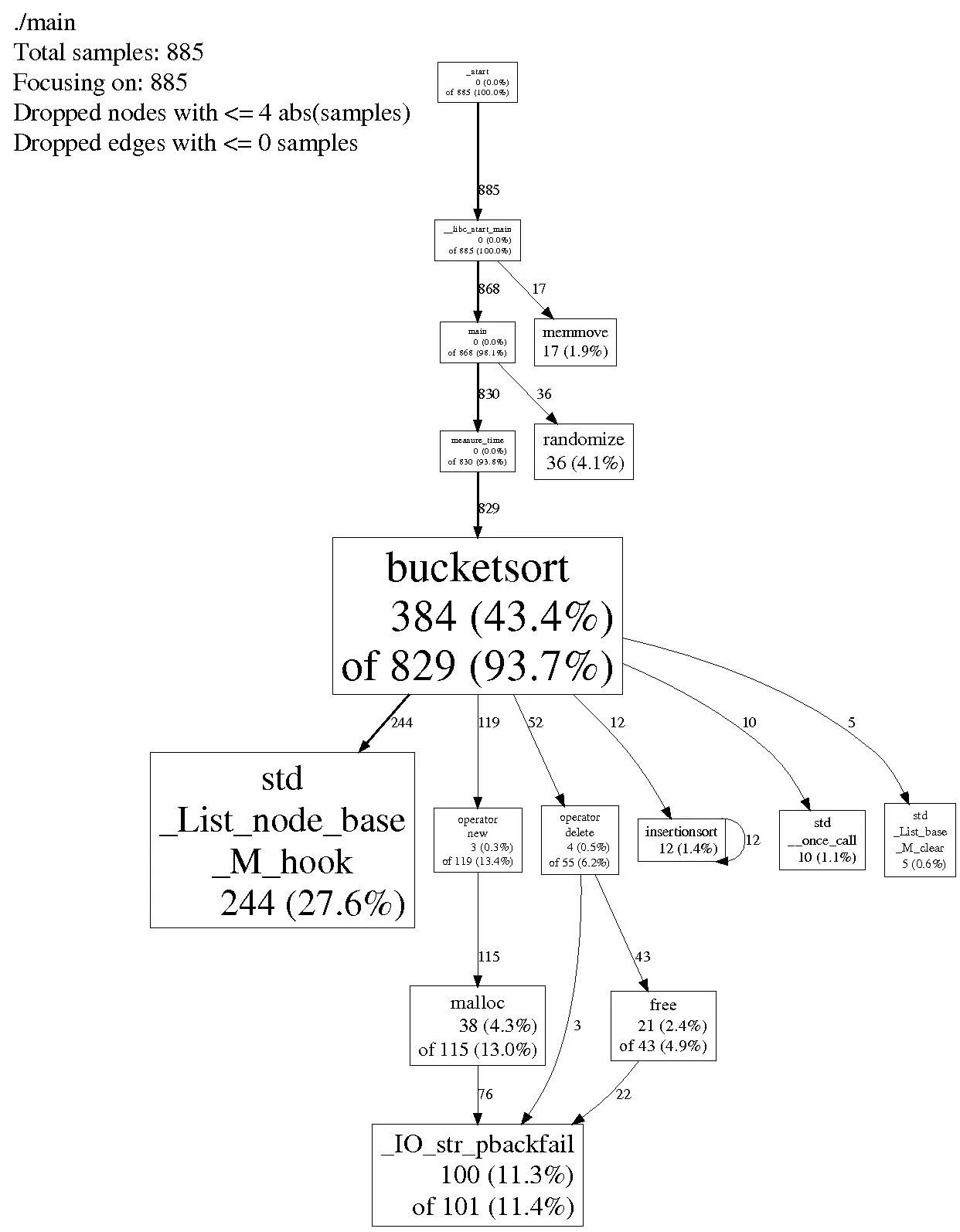
看起来我不应该使用STL中的list,但是我想知道为什么?std_List_node_base_M_hook是用来做什么的?我应该自己编写一个list类吗?
PS: 实验和改进
我尝试只留下把元素放入桶中的代码,这表明大部分时间都用在建立桶上。
进行了以下改进:
- 使用STL vector作为桶,并为其保留合理的空间。
- 使用两个辅助数组来存储用于构建桶的信息,从而避免使用链表,具体代码如下:
void bucketsort2(Array& A){
size_t numBuckets = ceil(A.size()/1000);
Array B(A.size());
IndexArray head(numBuckets+1,0),offset(numBuckets,0);//extra end of head is used to avoid checking of i == A.size()-1
for(size_t i=0;i!=A.size();i++){
head[int(numBuckets*A[i])+1]++;//Note the +1
}
for(size_t i=2;i<numBuckets;i++){//head[1] is right already
head[i] += head[i-1];
}
for(size_t i=0;i<A.size();i++){
size_t bucket_num = int(numBuckets*A[i]);
B[head[bucket_num]+offset[bucket_num]] = A[i];
offset[bucket_num]++;
}
A.swap(B);
//insertionsort(A);
for(size_t i=0;i<numBuckets;i++)
quicksort_range(A,head[i],head[i]+offset[i]);
}
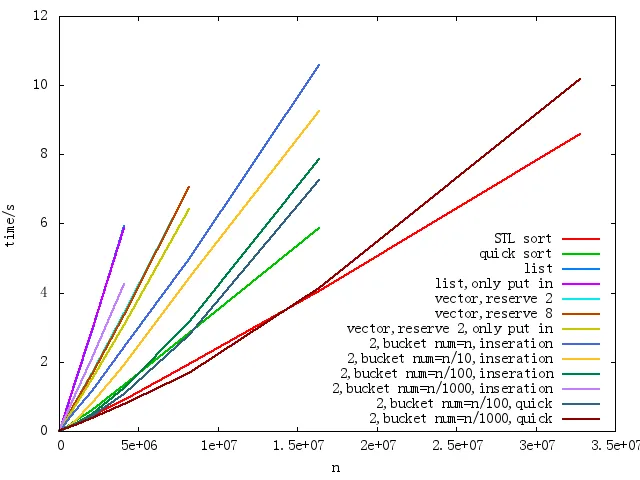 ,其中使用列表作为桶的行以列表开始,使用向量作为桶的行以向量开始,使用帮助数组开始第二个行。默认情况下,在最后使用插入排序,一些人使用快速排序,因为桶大小很大。
,其中使用列表作为桶的行以列表开始,使用向量作为桶的行以向量开始,使用帮助数组开始第二个行。默认情况下,在最后使用插入排序,一些人使用快速排序,因为桶大小很大。注意,“list”和“list,only put in”,“vector,reserve 8”和“vector,reserve 2”几乎重叠。
我将尝试使用足够多的内存保留较小的大小。
A.size() / some_const?或者是一个固定的数字(10,100)? - ruslik