以下是我的问题描述:
- 我希望我的程序能够压缩和解压选定的文件
- 我的文件非常大(20 GB+)。可以假设这些文件永远不可能适合内存
- 即使压缩后,压缩文件仍然可能无法适应内存
- 我想使用来自.NET Framework的System.IO.Compression.GzipStream
- 我希望我的应用程序是并行的
作为一个新手,对于压缩/解压缩,我有以下想法:
我可以将文件分成块,并单独压缩每个块。然后将它们合并成一个整体压缩文件。
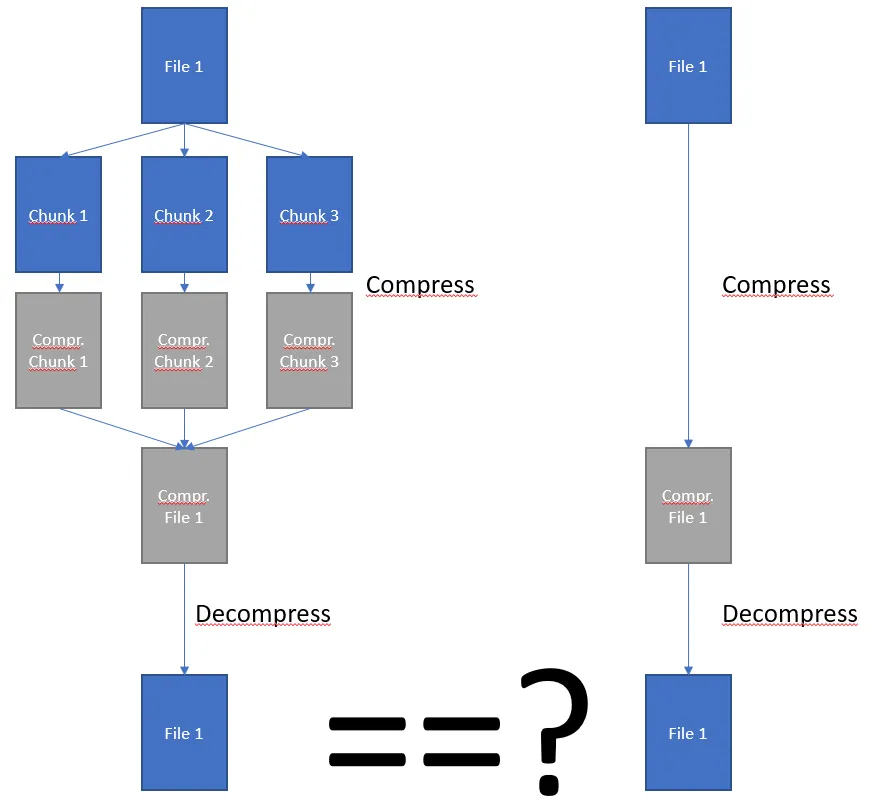
关于这种方法的问题1 - 压缩多个块,然后将它们合并在一起是否会给我正确的结果,即如果我要反转该过程(从压缩文件开始,返回到解压缩),是否会收到相同的原始输入?
关于这种方法的问题2 - 这种方法对你来说有意义吗?也许你可以指引我一些关于这个主题的好的讲座?不幸的是,我自己找不到任何资料。